







 本文深入剖析了可变形卷积v2的PyTorch实现,从源码角度详细介绍了其工作原理,包括如何通过学习得到偏移量并应用于卷积过程,以及如何使用双线性插值处理小数偏移。
本文深入剖析了可变形卷积v2的PyTorch实现,从源码角度详细介绍了其工作原理,包括如何通过学习得到偏移量并应用于卷积过程,以及如何使用双线性插值处理小数偏移。
接着上一章的来讲,上一章主要是介绍了一下可变形卷积v1和v2,红色字都是基于源码来的。那么这一篇文章就分析一下整个代码流程是怎么样的。代码是Pytorch版的,这里附上Github地址:https://github.com/4uiiurz1/pytorch-deform-conv-v2/blob/master/deform_conv_v2.py。这里再次感谢大佬的开源代码!
先附上我debug时采用的代码。
if __name__ == '__main__':
feature_map = torch.randint(high=256, size=(1, 2, 5, 5), dtype=torch.float32)
feature_map = feature_map/255
deformconv2d = DeformConv2d(2, 4, modulation=True)
output = deformconv2d(feature_map)
print(output.shape)我模拟了网络中间的特征图输入,即[1,2,5,5](Batch_size=1,Channel=2,H,W=5)。同时进行了归一化操作,然后我初始化了一个可变形卷积,其输入通道数等于上一层的通道即2,输出通道数为4,最后利用forward前传得出output,output最终的输出为[1,4,5,5]。
class DeformConv2d(nn.Module):
def __init__(self, inc, outc, kernel_size=3, padding=1, stride=1, bias=None, modulation=False):
"""
Args:
modulation (bool, optional): If True, Modulated Defomable Convolution (Deformable ConvNets v2).
"""
super(DeformConv2d, self).__init__()
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.zero_padding = nn.ZeroPad2d(padding)
self.conv = nn.Conv2d(inc, outc, kernel_size=kernel_size, stride=kernel_size, bias=bias)
self.p_conv = nn.Conv2d(inc, 2*kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.p_conv.weight, 0)
self.p_conv.register_backward_hook(self._set_lr)
self.modulation = modulation
if modulation:
self.m_conv = nn.Conv2d(inc, kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.m_conv.weight, 0)
self.m_conv.register_backward_hook(self._set_lr)首先分析下其初始化函数,self.conv代表的是最终在offset过后的特征图上进行卷积的那个卷积核参数设置,注意它的stride=kernel_size。它不是写错了。self.p_conv就是学习到的offset,他得到的是[1,2*3*3,5,5]大小的Tensor。通道2*3*3就是原论文中的2N!这里我简单的解释下2N的含义,让大家先有个初步的认识。。那么2N是怎么来的。这里上一张图
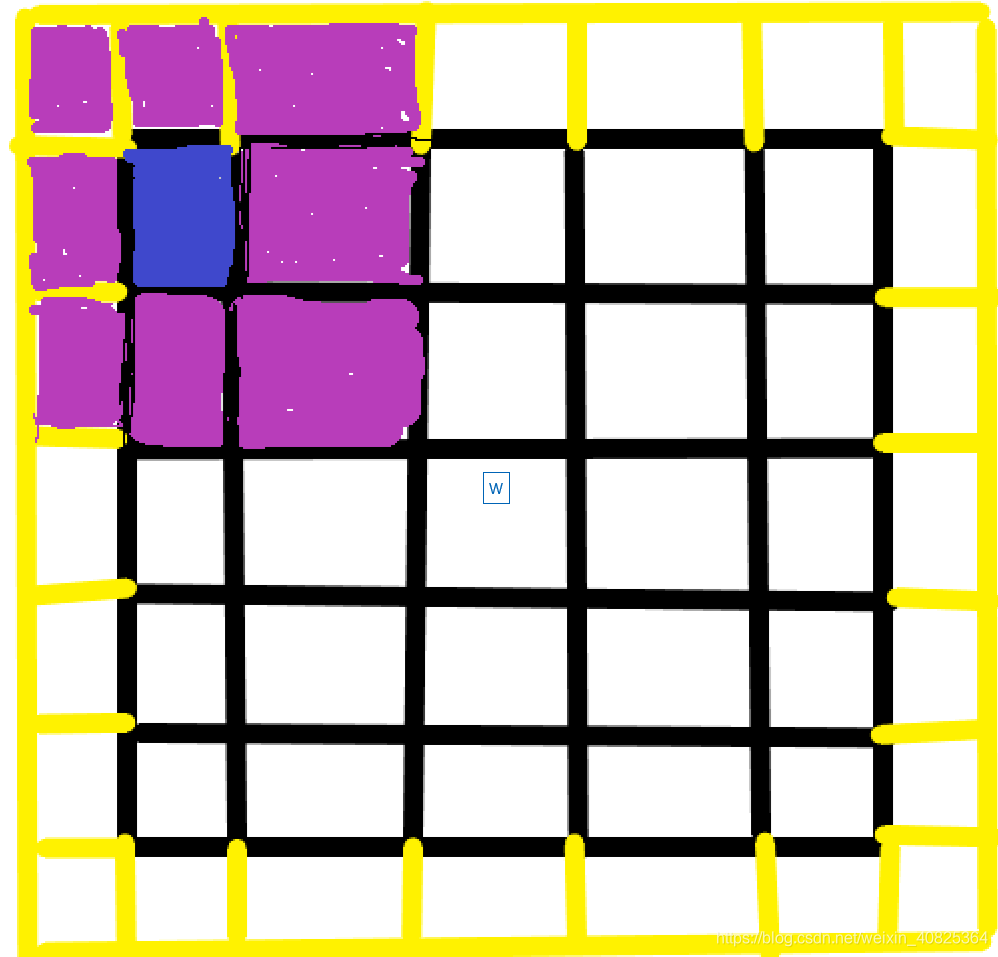
图1
图画的有点丑了。解释一下我这个图,黑色的矩形框就是咱们的原图(5*5大小),粉红色是咱们的3*3的卷积核,黄色是因为我们有一个padding=1的操作,现在试想一个正常的卷积操作。当粉红色卷积核在原图上滑动过程第一次就是如上图所示,但是因为咱们这是可变形卷积。也就是这8个粉红色的点加上这个蓝色的点即原图上的卷积采样点都要学习一组offset的,一共9组offset。每一组offset都有x偏移和y偏移总共18个offset。同时这18个offset是由卷积采样点中心负责学习,一共有25个卷积采样中心点,为什么是25&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









