




 该博客详细介绍了如何使用PaddlePaddle实现十二生肖图像分类任务,从数据准备、模型开发、训练优化到模型评估。首先,解压数据集并进行标注,然后定义数据集类,使用ResNet50预训练模型进行模型开发,通过CosineAnnealingDecay学习率策略进行训练,并利用VisualDL进行训练过程可视化。最后,进行模型评估和批量预测。
该博客详细介绍了如何使用PaddlePaddle实现十二生肖图像分类任务,从数据准备、模型开发、训练优化到模型评估。首先,解压数据集并进行标注,然后定义数据集类,使用ResNet50预训练模型进行模型开发,通过CosineAnnealingDecay学习率策略进行训练,并利用VisualDL进行训练过程可视化。最后,进行模型评估和批量预测。
任务要求
找到一个最优算法,让机器能够分清每个属相动物的照片,这是一个基于图像的分类任务。
图像分类
实现思路
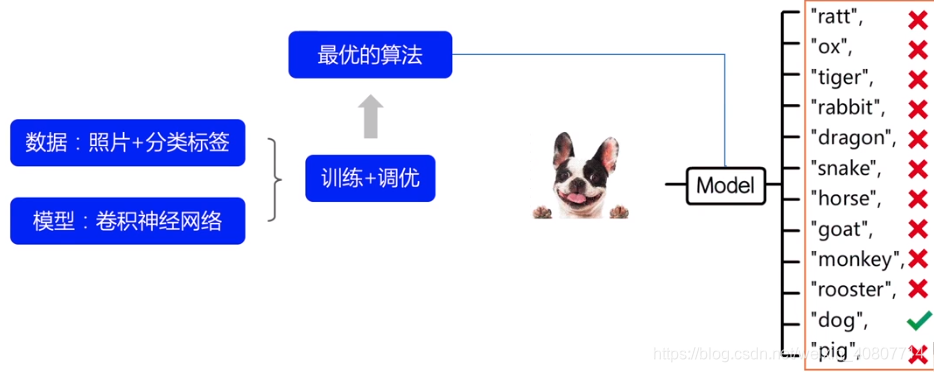
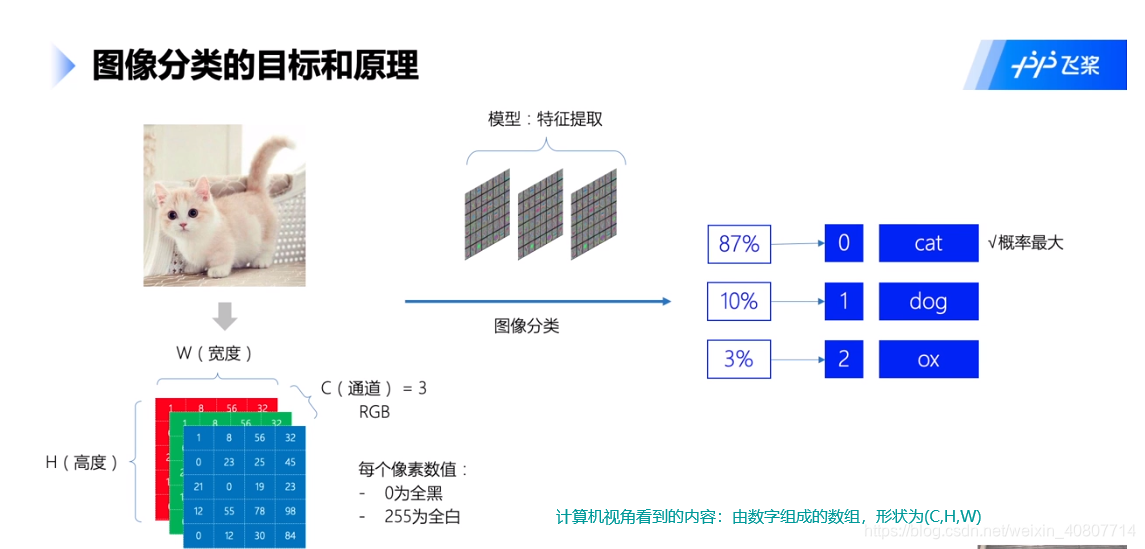
图像分类原理
数据准备
解压数据集
我们将网上获取的数据集以压缩包的方式上传到aistudio数据集中,并加载到我们的项目内。在使用之前我们进行数据集压缩包的一个解压(十二生肖数据集
)
!unzip -q -o <压缩包路径>
数据标注
数据集结构:
.
├── test
│ ├── dog
│ ├── dragon
│ ├── goat
│ ├── horse
│ ├── monkey
│ ├── ox
│ ├── pig
│ ├── rabbit
│ ├── ratt
│ ├── rooster
│ ├── snake
│ └── tiger
├── train
│ ├── dog
│ ├── dragon
│ ├── goat
│ ├── horse
│ ├── monkey
│ ├── ox
│ ├── pig
│ ├── rabbit
│ ├── ratt
│ ├── rooster
│ ├── snake
│ └── tiger
└── valid
├── dog
├── dragon
├── goat
├── horse
├── monkey
├── ox
├── pig
├── rabbit
├── ratt
├── rooster
├── snake
└── tiger
数据集分为train、valid、test三个文件夹,每个文件夹内包含12个分类文件夹,每个分类文件夹内是具体的样本图片。我们对这些样本进行一个标注处理,最终生成train.txt/valid.txt/test.txt三个数据标注文件。
import io
import os
from PIL import Image
from config import get
# 数据集根目录
DATA_ROOT = 'signs'
# 标签List
LABEL_MAP = get('LABEL_MAP')
# 标注生成函数
def generate_annotation(mode):
# 建立标注文件
with open('{}/{}.txt'.format(DATA_ROOT, mode), 'w') as f:
# 对应每个用途的数据文件夹,train/valid/test
train_dir = '{}/{}'.format(DATA_ROOT, mode)
# 遍历文件夹,获取里面的分类文件夹
for path in os.listdir(train_dir):
# 标签对应的数字索引,实际标注的时候直接使用数字索引
label_index = LABEL_MAP.index(path)
# 图像样本所在的路径
image_path = '{}/{}'.format(train_dir, path)
# 遍历所有图像
for image in os.listdir(image_path):
# 图像完整路径和名称
image_file = '{}/{}'.format(image_path, image)
try:
# 验证图片格式是否ok
with open(image_file, 'rb') as f_img:
image = Image.open(io.BytesIO(f_img.read()))
image.load()
if image.mode == 'RGB':
f.write('{}\t{}\n'.format(image_file, label_index))
except:
continue
generate_annotation('train') # 生成训练集标注文件
generate_annotation('valid') # 生成验证集标注文件
generate_annotation('test') # 生成测试集标注文件
数据集定义
接下来我们使用标注好的文件进行数据集类的定义,方便后续模型训练使用。
import paddle
import numpy as np
from config import get
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 888
888




 到【灌水乐园】发言
到【灌水乐园】发言







