







一、定义
为了避免树的高度增长过快,降低二叉排序树的性能,规定在插入和删除而擦函数结点,保证任意结点的左、右子树高度差的绝对值不超过1,将这样的二叉树成为平衡二叉树。
结点的平衡因子:该结点左子树高度 减去右子树高度所得的差,取值只有0,1,-1
typedef int DataType;
typedef struct node{
DataType data; //结点的数据值
int bf; //平衡因子
struct node *lchild,*rchild;
}AVLNode,*AVLTree;
二、基本操作演示
Avl和bst的插入相同,但avl每次插入后都要保证平衡
当发生不平衡时,调整的是最小不平衡子树。
从插入结点那里算起,找到最先发生不平衡的结点为根的树。
(每次调整要满足bst的性质)
若三个结点处于一条直线,采用单旋。(LL和RR)
这个名字比较难受,反着记。LL字面英文意思是左左,实际名字叫右单旋
若三个结点处于一条折线,采用双旋。(LR和RL)
LR叫先左后右,看字母就懂。
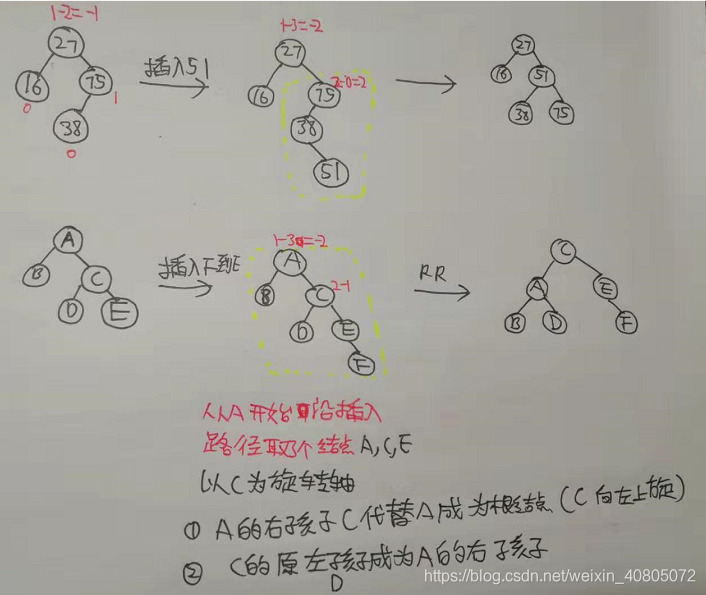
接着再说那个名字。
LL,RR,LR,RL实际上是对不平衡状态的描述。
比如上面的第一个用的LR调整,
因为新插入的结点在最小不平衡子树的左(L)孩子的右(R)子树上
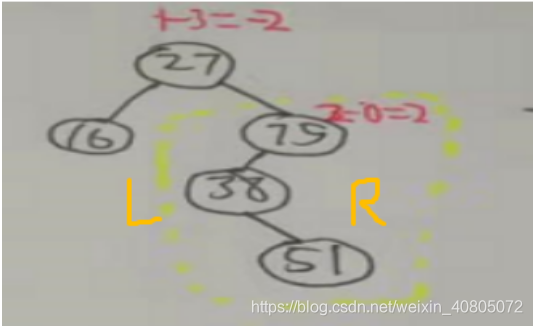
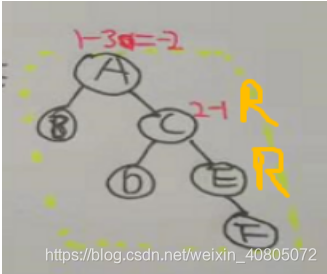
比如上面第二个图用的RR调整,新插入结点F在,A的右孩子C的右子树上
此外一个知识点就是,含有n个结点的avl的最大深度为,也能求出最多比较次数。
三、习题
1.二叉树、二叉查找树和avl树之间什么关系?
答:二叉树时满足二叉树特性的树形结构,对树中结点的值没有限定;在一棵二叉树中结点的值可重复,也可不重复;
二叉查找树每个结点的值不重复,且比左子树所有结点值都大,比右子树所有结点值都小;
avl树是二叉查找树的特殊情形,为了保证高效查找,每次插入或删除都进行平衡化处理,使得每个结点的左右子树高度差绝对值不超过1
2.在高度为h的avl树中离根最近的叶结点在第几层
答:设高度为h的avl树的离根最近的叶结点所在层次为,则有
直接计算公式为:
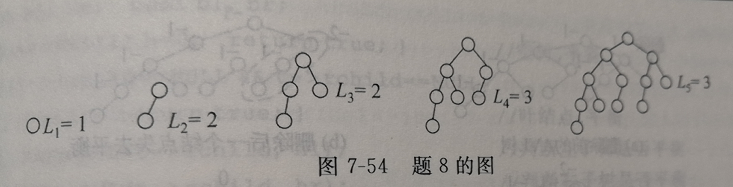
3.n个结点的avl树的最小高度为多少?最大高度为多少?
答:设avl树的高度为h,让avl树每层结点达到最大,就得到它的最小高度
若让根的左右子树的结点个数达到最少,可得最大高度。设高度为h的avl树的最少结点数为,则
最大高度满足是斐波那契数;
此外由斐波那契数通项公式,再换底推出
4.avl树在旋转调整时只调整了最小不平衡子树,调整后avl树是否还会存在不平衡结点?为什么?
答:虽然在旋转调整时只调整了最小不平衡子树,但调整后avl树中不会再有不平衡的结点。因为当在avl树上插入结点出现不平衡时,会将最小不平衡子树的高度加1,经过调整后使得最小不平衡子树恢复原来的高度,因此除了最小不平衡子树外,其他结点的平衡因子没发生辩护,因此不会存在不平衡的的结点

















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









