



 本文介绍如何运用lxml库结合XPath语法高效解析XML文档,通过实例演示了爬虫中提取特定信息的方法,包括模拟登录、数据抓取及解析技巧。
本文介绍如何运用lxml库结合XPath语法高效解析XML文档,通过实例演示了爬虫中提取特定信息的方法,包括模拟登录、数据抓取及解析技巧。
xml xpath lxml
-
xml:可扩展标记语言
-参考网址:http://www.w3school.com.cn/xml/index.asp -
xpath:一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性 进行遍历
-
lxml: lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高
实战案例:
案例和昨天的一样,爬取丁香园指定帖子的用户和回复内容,不同的是这次我们使用lxml和xpath进行操作
工具:xpath lxml requests
方法:
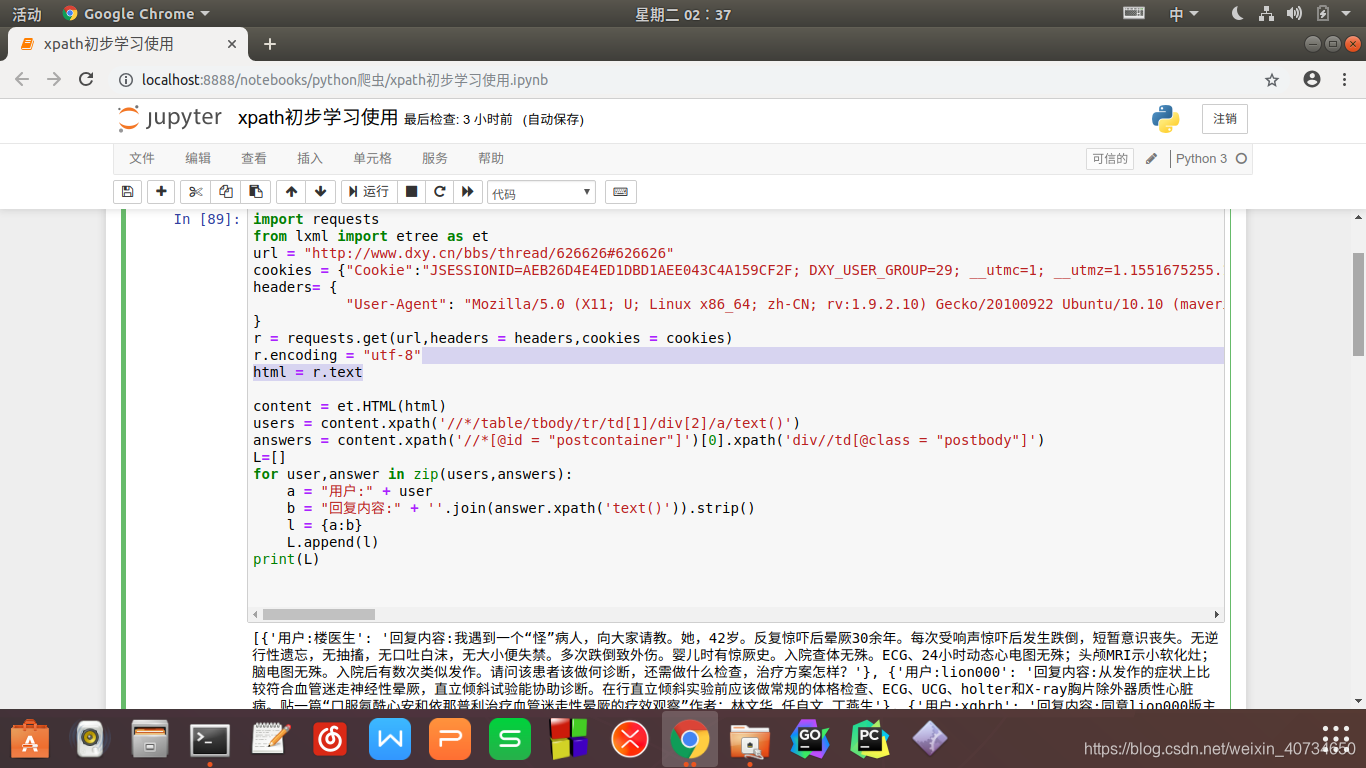
1.用cookie模拟登录,用headers隐藏身份,requests.get或者requests.request请求网页
2.利用lxml里的etree模块的HTML方法构造了一个XPath解析对象并对HTML文本进行自动修正。
3.观察我们想要的内容所在的标签,然后利用xpath方法,根据xpath语法规则进行数据处理,找到我们想要的用户名和回复内容,xpath方法返回的是一个列表
4,通过zip方法,我们把两个列表内容分别作为字典的键和值合在一起构造成一个新列表,将列表打印即可得到我们想要的结果
代码实现:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









