







 本文介绍了使用Python的lxml库配合Xpath进行HTML解析的方法,讲解了Xpath的基本语法,包括节点选择、文本获取以及属性操作。重点讨论了在爬虫中如何从URL响应中正确提取Xpath数据,并提供了Chrome和Firefox的Xpath辅助工具。
本文介绍了使用Python的lxml库配合Xpath进行HTML解析的方法,讲解了Xpath的基本语法,包括节点选择、文本获取以及属性操作。重点讨论了在爬虫中如何从URL响应中正确提取Xpath数据,并提供了Chrome和Firefox的Xpath辅助工具。
7、Xpath
-
lxml是一款高性能的Python HTML/XML解析器,我们可以利用Xpath来快速定位特定元素以及获取节点信息。XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
-
工具:
1.Chrome插件 Xpath Helper
2.开源的Xpath表达式编辑工具:XML Quire(xml格式文件可用)
3.Firefox插件 Xpath Checker -
节点选择语法
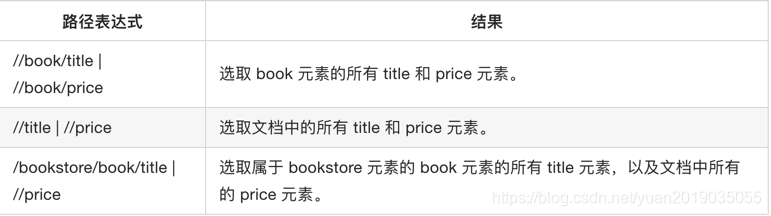 获取a下的文本
- a//text() 获取a下的所有标签的文本
- //a[text()=‘下一页 >’] 选

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











