







 本文介绍了如何利用Python的BeautifulSoup库爬取丁香园论坛特定帖子的所有回复内容。首先讲解了BeautifulSoup的安装和基本用法,然后通过案例展示了抓取用户名和内容的过程。在遇到只获取到部分回复的问题时,通过添加cookie模拟用户登录来解决。最后,对BeautifulSoup的特点和常用方法进行了总结。
本文介绍了如何利用Python的BeautifulSoup库爬取丁香园论坛特定帖子的所有回复内容。首先讲解了BeautifulSoup的安装和基本用法,然后通过案例展示了抓取用户名和内容的过程。在遇到只获取到部分回复的问题时,通过添加cookie模拟用户登录来解决。最后,对BeautifulSoup的特点和常用方法进行了总结。
beautifsoup----爬虫数据挖掘又一大利器
– 安装:
conda install beautifulsoup4 或者 pip install beautifulsoup4(这个4代表着bs的版本)
这里我用了conda安装:
– beautiful soup:
BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库.
官方文档:Beautifulsoup官方文档(里面讲的很详细)
–案例:
-
工具:urllib bs
-
思考:
1. 用urllib.request.Request请求网页,使用headers设置用户代理或者使用proxy代理服务器隐 藏身份,因为直接请求,返回403。
2. 通过查看源代码发现,用户名在auth类下的a标签里,而用户回复内容在postbody类里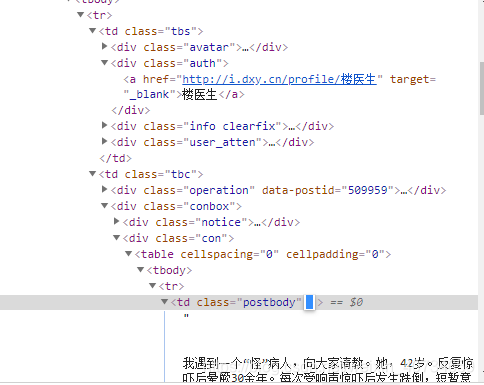
4. 炖一锅汤,使用css选择器 select方法下的get_text()方法找到我们想要的数据
5. for循环并按想要的格式输出数据 -
代码:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









