







爬取豆瓣电影
豆瓣top250链接:https://movie.douban.com/top250
每25个一页,
第一页url:https://movie.douban.com/top250?start=0&filter=
第二页url:URL变成了https://movie.douban.com/top250?start=50&filter=
以此类推,修改url,start=0,50,100可以验证
这次爬取电影名称

代码如下:
import requests
from bs4 import BeautifulSoup
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/80.0.3987.163 Chrome/80.0.3987.163 Safari/537.36',
}
def URL_list(): # 构建URL列表
urls = []
# 根据我们观察到的规律进行构建
for i in range(0, 250, 25):
url = 'https://movie.douban.com/top250?start=' + str(i)+'&filter='
urls.append(url)
return urls
def get_data(url):
res = requests.get(url, headers=headers) # 发出请求
soup = BeautifulSoup(res.text, 'lxml')
return soup
def parse_data(soup, data):
# target = soup.select("#content > div > div.article > ol > li > div > div.info > div.hd > a > span:nth-of-type(1)")
target = soup.select("#content > div > div.article > ol > li > div > div.info > div.hd > a > span.other")
for i in target:
data.append(i.get_text())
return data
def main():
urls = URL_list()
data = []
for url in urls:
soup = get_data(url) # 发起请求
parse_data(soup, data)
print("---- 豆瓣前250电影 ----")
for i in range(len(data)):
print("%6s" % (str(i+1)) + " " + "%25s" % data[i]) #格式化输出
if __name__ == "__main__":
main()
结果如下:
re正则表达式提取电影名称、导演、年份
代码:
import re
import requests
from bs4 import BeautifulSoup
count = 1
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/80.0.3987.163 Chrome/80.0.3987.163 Safari/537.36',
}
def URL_list(): # 构建URL列表
urls = []
# 根据我们观察到的规律进行构建
for i in range(0, 250, 25):
url = 'https://movie.douban.com/top250?start=' + str(i)+'&filter='
urls.append(url)
return urls
def get_data(url):
res = requests.get(url, headers=headers) # 发出请求
soup = BeautifulSoup(res.text, 'lxml')
return soup
def parse_data_all(soup, data):
global count
# soup = BeautifulSoup(text, 'lxml')
film_names = soup.select('#content > div > div.article > ol > li > div > div.info > div.hd > a > span:nth-of-type(1)')
film_data = soup.select("#content > div > div.article > ol > li > div > div.info > div.bd > p:nth-of-type(1)")
# print(film_data)
for (i,j) in zip(film_data, film_names):
target = i.get_text()
# print(target)
director_name = re.search('导演:.*', target).group()[4:-1] # 匹配导演
year = re.search('[0-9]{4}', target).group() # 匹配年份
# print(j.get_text())
film_names = j.get_text()
# print('导演:'+director_name)
lis = [film_names, director_name.split()[0], year]
data[count] = lis
# data.append(lis)
count += 1
def print_data(data):
for i in range(1, 251):
print(data[i])
def main1():
urls = URL_list()
data = {}
for url in urls:
text = get_data(url)
parse_data_all(text, data)
print_data(data)
if __name__ == "__main__":
main1()
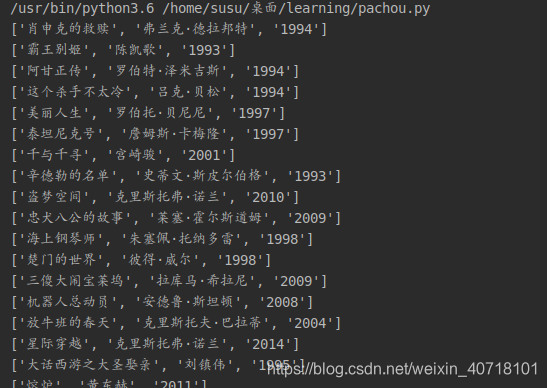
结果:

















 2668
2668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









