







1.概念
词法:词汇构成、变化和使用规则
句法:句子各个组成部分的排列以及相互关系,研究句子类型和句子成分
依存句法分析:识别句子中词汇与词汇之间的相互依赖关系
使用语义依存刻画句子语义,好处在于不需要明白词汇本身的意义,而是通过词汇所承受的语义框架来描述该词汇。
依存语法存在一个共同的基本假设:句法结构本质上包含词和次之间的依存关系。
依存句法通过词汇之间的依存关系表达整个句子结构,这些依存关系表达了句子各成分之间的语义依赖关系。所有词汇之间的依存关系构成一颗句法树,树的根节点为句子核心谓词,用来表达整个句子的核心内容。
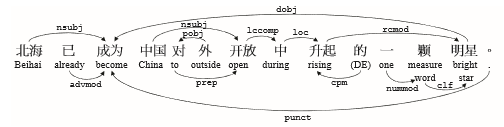
通过依存句法树中的依赖关系,可以获得具有特定语法关系的两个词汇。箭头起点称为被依赖项,又称为支配项,箭头指向依赖项。
2.公理
一个句子中只有一个成分是独立的;
其他成分直接依存于某一成分;
任何一个成分都不能依存于两个或两个以上的成分;
中心成分左右两面的其他成分相互不发生关系。
也就是说依存句法中,每个句子只有一个核心的谓词,句中每一个词都有一个与之相关的词。
3.应用
(1)可对相应树库构建体系的正确性和完善性进行验证;
(2)直接服务于上层应用,比如搜索引擎用户日志分析和关键词识别,信息抽取、自动问答、机器翻译等;
(3)观点标签挖掘:抽取的标签在与续上并不一定连续,句法分析能够准确找到句子中的关键成分,很适合在模糊语料中做信息挖掘和抽取。
4.分析方法
(基于规则和基于统计)主流是基于统计的方法,基于统计的方法主要分为基于图和基于决策两种。
基于图——看成从完全有向图中寻找最大生成树的问题,通常采用基于动态规划的解码算法,也有一些学者采用beamsearch提高效率。学习特征权重时,通常采用在线训练算法,如平均感知器(averagedperceptron)。
基于转移——将依存树的构成过程建模成一个动作序列,将依存分析问题转化为寻找最优动作序列的问题。模型通过贪心搜索或者柱搜索等解码算法找到近似最优的依存树。
目前在开源中文句法分析器中比较具有代表性有Stanford parser和 Berkeley parser。
附Stanford parser参考论文:https://nlp.stanford.edu/pubs/ssst09-chang.pdf


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









