







大数据系统的任务要求,从HDFS中读文件,进行Hash based groupby处理,再写入Hbase。

首先要仔细学会使用docker,菜鸟教学上对docker的教程很快就可以入门,该任务的环境已经在docker中配置好,要了解什么是镜像,什么是容器,如何下载镜像,如何通过镜像打开一个容器。熟悉一些docker指令。
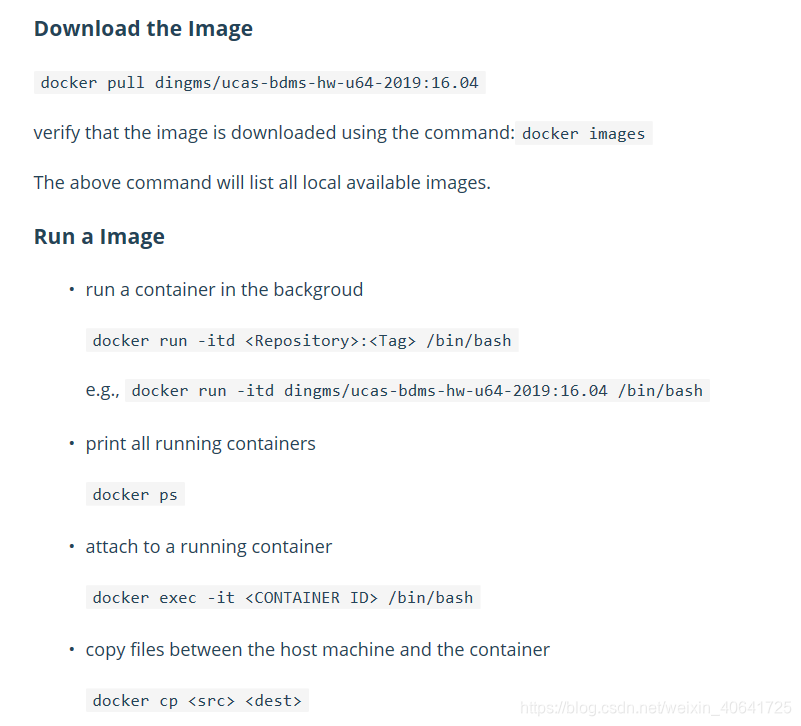
当学会了用docker的简单功能之后,就可以开始have fun了!
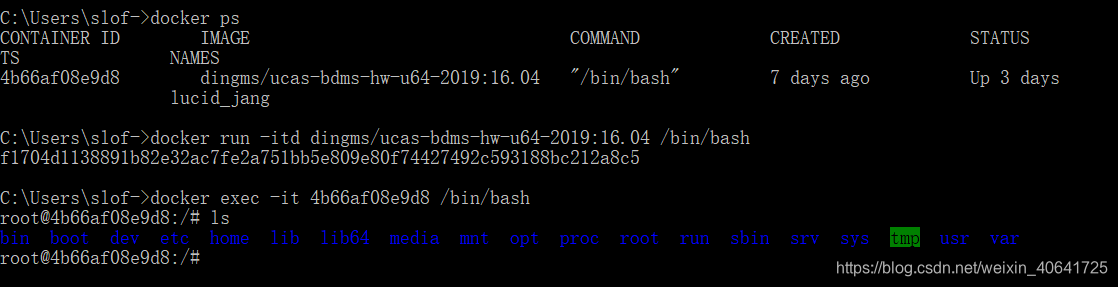
一路cd进目标位置/home/bdms/homework/hw1/README.md,进行学习。
有一些如何启动HDFS,如何编译,如何使用hbase shell的方法。
start -dfs.sh之前要把ssh打开,service ssh start
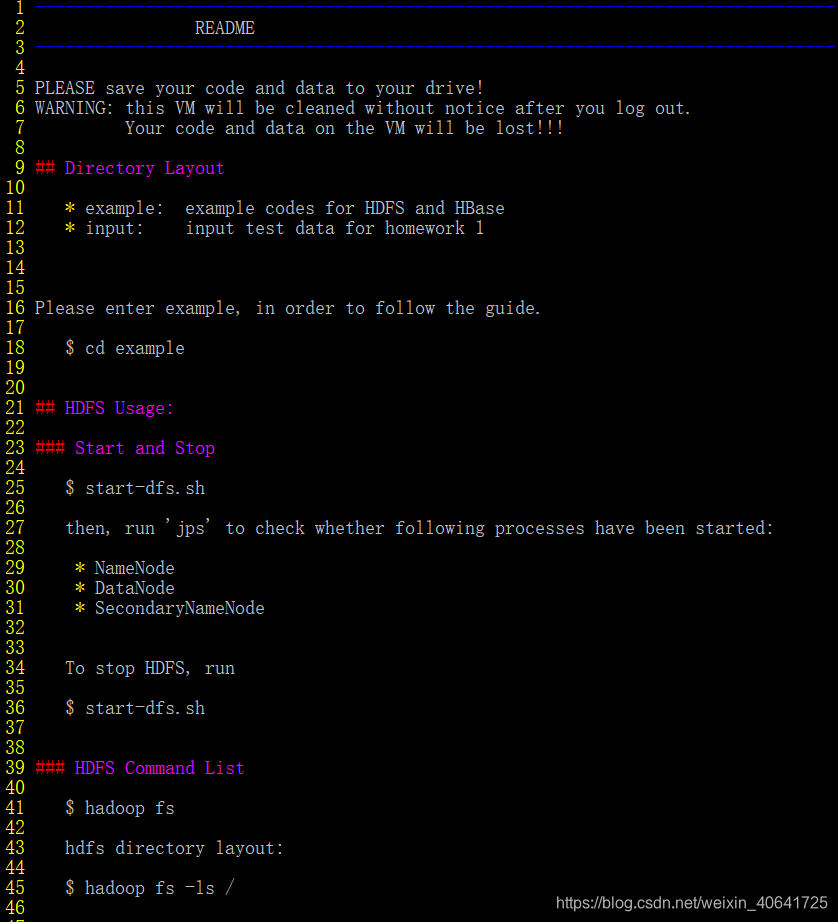
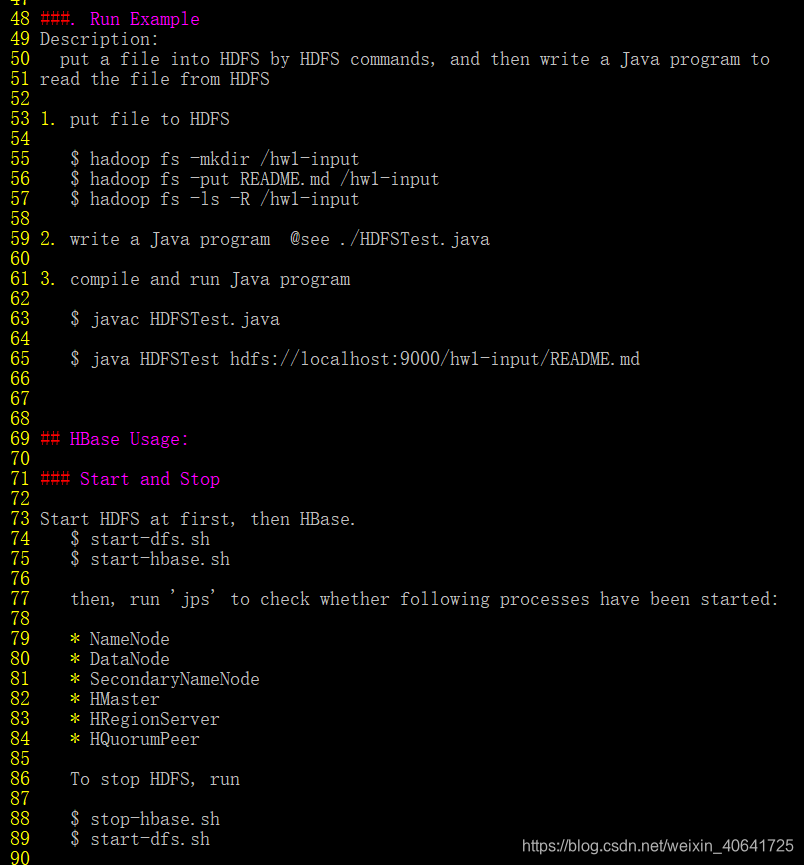
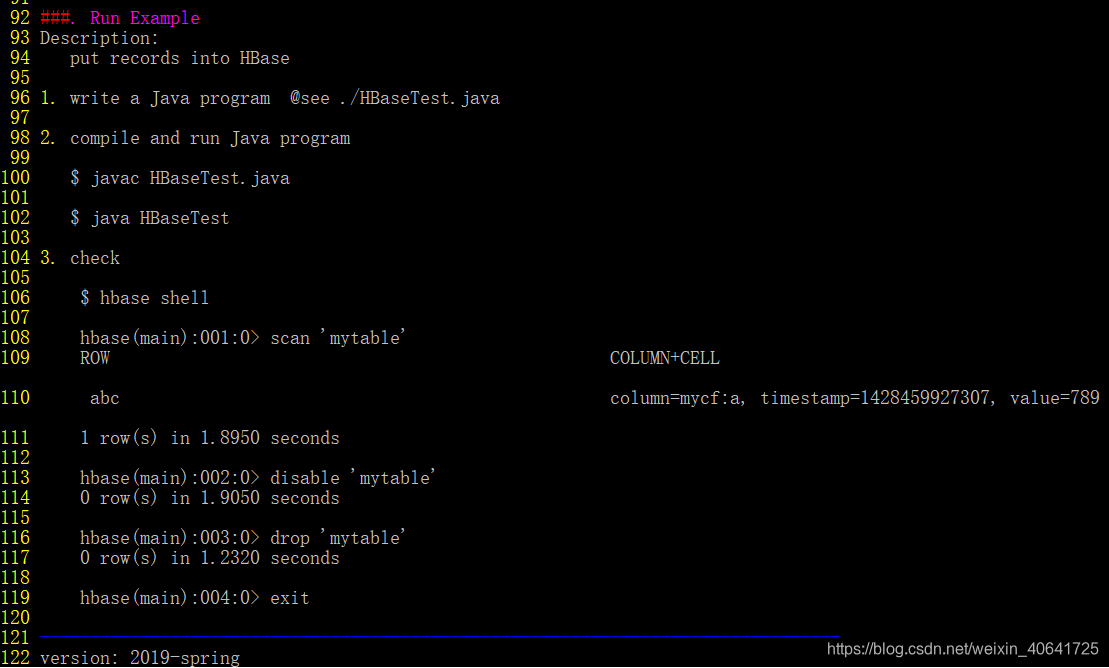
在这个过程中,了解了linux系统的一些指令,另外因为嫌麻烦没有尝试把docker用在别的IDE中,就直接在容器中使用vim写了,调试起来太费劲了。但也了解了一些vim的使用方法。在对两个文件HDFStest和HbaseTest进行了解读之后,就开始实现groupby的功能了。代码如下
import java.io.*;
import java.net.URI;
import java.util.*;
import java.net.URISyntaxException;
import java.util.HashMap;
import java.io.IOException;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.log4j.*;
public class Hw1Grp2{
public static void main(String[] args) throws MasterNotRunningException, ZooKeeperConnectionException, IOException{
/*code example:java Hw1Grp2 R=/hw1/lineitem.tbl groupby:R2 'res:count,avg(R3),max(R4)'
args[0]:R=/hw1/lineitem.tbl
args[1]:groupby:R2
args[2]:res:count,avg(R3),max(R4)
Part 1 :We need to analyze the command and extract the number of columns in it
*/
String filename=StringUtils.substringAfter(args[0], "=");
int key_columns= Integer.parseInt(StringUtils.substringAfter(args[1], "R"));
String temp=StringUtils.substringAfter(args[2], ":");
String[] func=temp.split(",");
Map<String, Integer> funcAndnum = new HashMap<String, Integer>(); ;
for(int i=0;i<func.length;i++){
if(func[i].equals("count")){
funcAndnum.put(func[i],key_columns);
}
else{
funcAndnum.put(StringUtils.substringBefore(func[i], "("), Integer.parseInt(StringUtils.substringBetween(func[i],"R", ")")));
}
}
Set<String> k=funcAndnum.keySet();
Iterator<String> it = k.iterator();
while(it.hasNext()){
String key = it.next();
int value =funcAndnum.get(key);
System.out.println("key:"+key+"---value:"+value);
}
/*
key:avg---value:2
key:max---value:3
key:count---value:0
get a map:func and row_num
*/
//Part 2: we should create hashtable to record function's value,and use map<funcAndnum> to decide which row is needed
Map<String,Integer> count_value =new HashMap<String,Integer>();
Map<String,Float> sum_value= new HashMap<String,Float>();
Map<String,Float> avg_value= new HashMap<String,Float>();
Map<String,Integer> max_value= new HashMap<String,Integer>();
// give -1 as initial number to recorde whether function is used or not,if used,give the row_num
int countColumns=-1;
int avgColumns =-1;
int maxColumns =-1;
//use sum to compute avg;
int sumColumns=-1;
if(funcAndnum.containsKey("count")){
countColumns= funcAndnum.get("count");
}
if(funcAndnum.containsKey("max")){
maxColumns=funcAndnum.get("max");
}
if(funcAndnum.containsKey("avg")){
avgColumns=funcAndnum.get("avg");
sumColumns=funcAndnum.get("avg");
}
//in order to ensure that functional changes can be addressed
//Part 3:read file from HDFS and split row with |,and put each row's infomation in function map.
if (args.length <= 0) {
System.out.println("Usage: HDFSTest <hdfs-file-path>");
System.exit(1);
}
String file = filename; //filename is arg[0] except R
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(file), conf);
Path path = new Path(file);
FSDataInputStream in_stream = fs.open(path);
BufferedReader in = new BufferedReader(new InputStreamReader(in_stream));
String s;
while ((s=in.readLine())!=null) {
String[] columns=s.split("\\|");
if(countColumns!=-1){
if(count_value.containsKey(columns[key_columns])){
count_value.put(columns[key_columns],count_value.get(columns[key_columns])+1);
}
else{
count_value.put(columns[key_columns], 1);
}
}
//if compute avg,must use sum
if(sumColumns!=-1){
if(sum_value.containsKey(columns[key_columns])){
sum_value.put(columns[key_columns],sum_value.get(columns[key_columns])+Float.parseFloat(columns[sumColumns]));
}
else{
sum_value.put(columns[key_columns],Float.parseFloat(columns[sumColumns]));
}
}
if(maxColumns!=-1){
if(max_value.containsKey(columns[key_columns])){
if(max_value.get(columns[key_columns])<Integer.parseInt(columns[maxColumns])){
max_value.put(columns[key_columns],Integer.parseInt(columns[maxColumns]));
}
}
else{
max_value.put(columns[key_columns],Integer.parseInt(columns[maxColumns]));
}
}
}
//use sum and count to compute avg
//map should be changed to set for iteration
//attention:if command only have count,don't have avg,this part do not run.use if()
if(avgColumns!=-1){
Set<String> sumset =sum_value.keySet();
Iterator<String> ss =sumset.iterator();
while(ss.hasNext()){
String key = ss.next();
//compute avg and Keep two decimal places,we can also use class DecimalFormat,but format saved as String.
float avgnum=(float)Math.round(sum_value.get(key)/count_value.get(key)*100)/100;
avg_value.put(key,avgnum);
}
}
/* testing code:print all key-value in Map avg
Set<String> avgset = avg_value.keySet();
Iterator<String> as = avgset.iterator();
while(as.hasNext()){
String key = as.next();
float value =avg_value.get(key);
System.out.println("key:"+key+"---value:"+value);
}
*/
// now we have got max,cout,avg map,put it into Hbase
//Part 4: create Hbase tabel and put
Logger.getRootLogger().setLevel(Level.WARN);
// create table descriptor
String tableName= "Result";
HTableDescriptor htd = new HTableDescriptor(TableName.valueOf(tableName));
// create column descriptor
HColumnDescriptor cf = new HColumnDescriptor("res");
htd.addFamily(cf);
// configure HBase
Configuration configuration = HBaseConfiguration.create();
HBaseAdmin hAdmin = new HBaseAdmin(configuration);
if (hAdmin.tableExists(tableName)) {
System.out.println("Table already exists");
hAdmin.disableTable(tableName);
hAdmin.deleteTable(tableName);
System.out.println("Table already deleted");
hAdmin.createTable(htd);
System.out.println("table "+tableName+ " created successfully");
}
else {
hAdmin.createTable(htd);
System.out.println("table "+tableName+ " created successfully");
}
hAdmin.close();
HTable table = new HTable(configuration,tableName);
//use a iterator to get key
Set<String> countset=count_value.keySet();
Iterator<String> diff =countset.iterator();
while(diff.hasNext()){
String key= diff.next();
if(countColumns!=-1){
Put put = new Put(key.getBytes());
put.add("res".getBytes(),"count".getBytes(),(count_value.get(key).toString()).getBytes());
table.put(put);
}
if(avgColumns!=-1){
Put put = new Put(key.getBytes());
put.add("res".getBytes(),("avg(R"+avgColumns+")").getBytes(),(avg_value.get(key).toString()).getBytes());
table.put(put);
}
if(maxColumns!=-1){
Put put = new Put(key.getBytes());
put.add("res".getBytes(),("max(R"+maxColumns+")").getBytes(),(max_value.get(key).toString()).getBytes());
table.put(put);
}
}
System.out.println("write Hbase over! very successful!");
}
}
代码写完之后,提供了一个测试程序,可以用docker cp命令拷贝到虚拟机当中,用 tar xzf hw1-check-v1.1.tar.gz解压,找到其中的README.txt,完成其中步骤,就可以对3个测试完成作业1的检查。
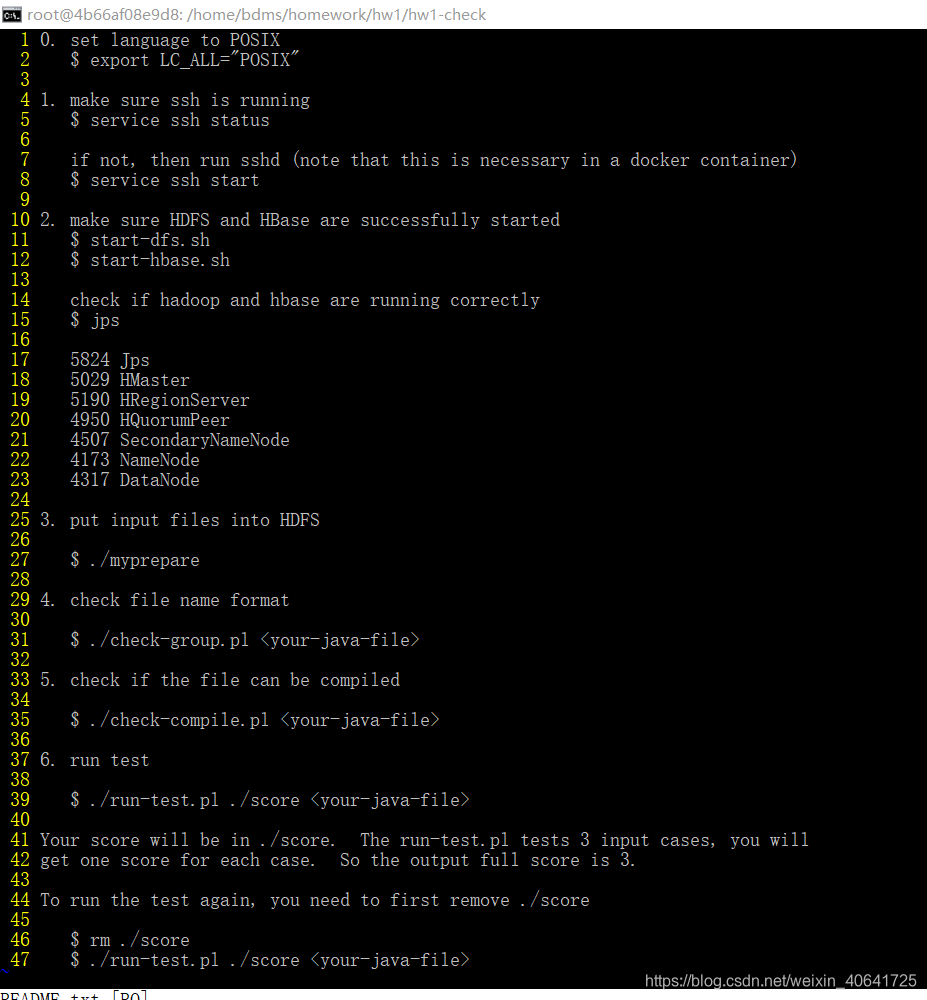
解压之后打开hw1-check,并且check file name format:good!

check if the file can be compiled:good!

run test,之后view score,3 is good!

最后把文件从docker中导到自己的电脑上去。
任务完成!keep going!

















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









