







摘要
卷积神经网络(CNN)最近已证明在计算成像应用中具有卓越的质量。因此,它们具有极大的潜力来革新相机和显示器上的图像管线。但是,由于传统的CNN加速器具有相当大的DRAM带宽和功耗,因此难以在边缘支持超高分辨率视频。因此,引入进一步的内存和计算效率高的微体系结构对于加快这一即将到来的革命至关重要。在本文中,我们通过考虑推理量低,网络模型,指令集和处理器设计共同优化硬件来实现此目标。性能和图像质量。我们应用了基于块的推断低值,它可以消除特征图的所有DRAM带宽,并因此提出了一种面向硬件的网络模型ERNet,以基于硬件约束来优化图像质量。然后,我们设计了一种粗粒度的指令集体系结构FBISA,以通过大规模并行性支持耗电的卷积。最后,我们实现了嵌入式处理器eCNN,该处理器具有灵活的处理体系结构,可适应ERNet和FBISA。布局结果表明,它仅支持DDR-400且平均消耗6.94W的功率即可支持高质量ERNets的超分辨率和高达4K Ultra-HD 30 fps的降噪。相比之下,最新的Dify使用双通道DDR3-2133,消耗54.3W功率以支持全高清30 fps的低质量VDSR。最后,我们还将提供高性能样式转换和对象识别的应用示例,以证明eCNN的灵活性。
说明
尽管有潜力在边缘设备上启用下一代图像流水线,但很少讨论用于计算成像的面向硬件的模型。已经提出了几种用于深度神经网络的硬件加速器。例如,DaDianNao,Cambricon-ACC ,TPU ,和DNPU ,设计用于通用推理。
但是,这些加速器并未针对计算成像进行优化,也未针对高分辨率视频进行了优化,特别是在DRAM带宽和计算能力方面。最近,Dify [41]通过利用激活差异中的位稀疏性来减少DRAM访问和计算能力,从而解决了这个问题。但是,全高清视频仍需要许多Dify磁贴和高端DRAM设置。
给定CNN模型的推断低点确定了加速器的数据重用方案,从而确定了其内存访问效率。对于块之间的重叠特征,选择了一种重用方案以融合多达五个CNN层。但是,行缓冲区的大小将随模型深度,图像宽度和通道数线性增加。例如,要支持全高清分辨率的VDSR ,将需要9.3MB的SRAM。对于图像处理应用,片上SRAM大小和片上DRAM带宽之间的相似折衷也已得到广泛研究。在这项工作中,我们旨在实现最高4K Ultra-HD(UHD)30 fps的高质量边缘推理能力,可用于计算成像任务。特别是,我们将低端DRAM设置作为目标,以实现嵌入式设备上的经济高效和高效节能的集成。我们发现,直接加速具有广泛功能和深层功能的最新模型很难实现这一具有挑战性的目标。取而代之的是,我们扩展了设计空间,以结合考虑低位推理,模型结构,指令集和处理器设计,以优化硬件性能和图像质量。
提出一个基于块的截尾金字塔推断低位,它可以通过将特征图存储在片上块缓冲器中来消除特征图的所有DRAM带宽。为了避免大量的片上存储,我们选择重新计算相邻块之间的重叠结果。块缓冲区的大小与模型宽度成正比,重新计算的开销几乎随模型深度成倍增加。结果,这两个因素违背了简单地添加更多功能和更多层以提高模型质量的经验法则。相反,我们提出了一种新颖的ERNet模型来在这些硬件约束下优化CNN。然后,我们构建功能块指令集体系结构(FBISA)以支持高度并行的卷积。它以单指令多数据(SIMD)的方式指定块缓冲区级别的操作。此外,它为程序员和编译器提供了基于不同约束优化计算量低的灵活性。最后,我们实现了一个嵌入式CNN处理器eCNN,它具有高度并行的过滤器和本地分布的参数,可以灵活地适应ERNet和FBISA。本文工作
- 我们提出了一种基于块的低带宽,以实现具有低DRAM带宽的高分辨率推断,并分析其计算和带宽开销。
- 我们提出了一种基于硬件的ERNet,可基于硬件约束来优化图像质量,并建立用于模型优化和动态定点精度的训练程序。
- 我们设计了具有并行参数位流的粗粒度FBISA,以高效,灵活地提供大量的计算并行性。
- 我们设计了一个嵌入式处理器eCNN,以使用81,920个乘法器的高度并行卷积支持FBISA。
- 我们训练ERNets以获得图像超分辨率(SR)和8位精度的降噪。特别是,当eCNN分别提供Full HD和4K UHD 30fps时,四倍SR的质量可以在PSNR上胜过VDSR 0.57 dB和0.44dB。
- 布局结果表明,eCNN在40 nm技术上可以达到41 TOPS(每秒每秒操作次数)。它支持高达4K UHD 30 fps的高质量ERNets,同时消耗6.94W的功耗并使用DDR-400。相比之下,Dify消耗54.3W功率,并以FullHD 30 fps对VDSR使用双通道DDR3-2133。
- FBISA兼容模型也可以很好地支持计算机视觉任务,例如样式转换和对象识别。
动机
CNN加速器的最新研究主要集中在对象识别/检测网络上。因此,没有考虑将计算成像网络的两个特定特征进行优化:
1)特征图的空间分辨率未主动降低采样率;
2)模型不是很稀疏。前者导致显着高的存储带宽,而后者则带来了对计算能力的极高需求。
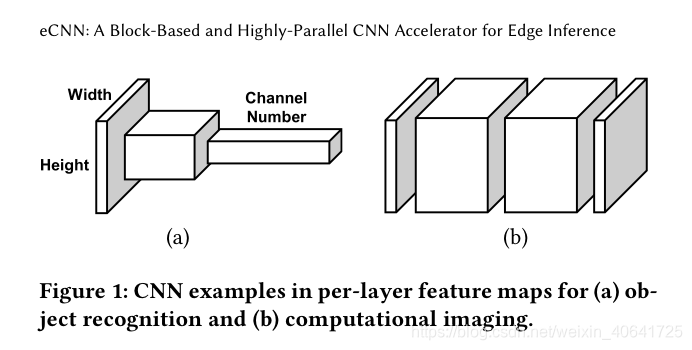
图1(a)所示为对象识别的积极下采样。它可以提取高级特征,还可以减少更深层中的特征图(长方体的体积)的数据量。因此,大多数传统的加速器可以将基于帧的推理降低到较低水平,以有限的DRAM带宽逐层执行卷积。但是,此低值将为计算成像网络带来大量的DRAM带宽。这是因为需要高分辨率的特征图来生成纹理细节,并且只允许进行适度的下采样。以图1(b)中没有下采样的普通网络为例,除输入和输出图像外,其对应于特征图的DRAM带宽可以推导为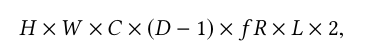
其中H代表图像高度,W代表图像宽度,C代表特征通道(模型宽度)的数量,D代表模型深度,f R代表帧速率,L代表每个特征的位长,写因数2每层功能映射到DRAM,然后加载回下一层。因此,使用16位功能时,20层64通道VDSR将需要303 GB / s的内存带宽用于全高清30 fps。即使采用最先进的压缩技术,Dify仍需要双通道DDR3-2133(34 GB / s)才能满足此Full-HD规范。
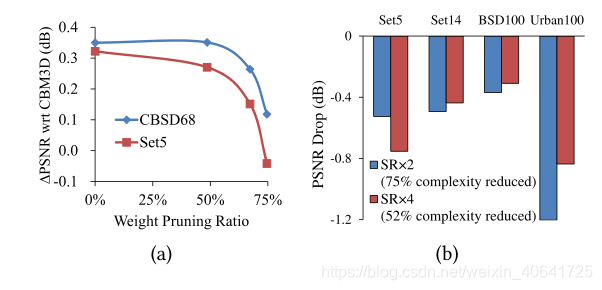
另一方面,稀疏的对象识别模型已被用于开发许多节省复杂度的技术,例如权重修剪和深度卷积。但是,计算成像网络依赖于各种参数来提取局部特征并生成ine纹理。它们的图像质量与模型大小高度相关,因此稀疏技术可能会导致严重的性能下降。图2显示了两个这样的示例。一个是去噪DnERNet模型的修剪权重(第7节)。当修剪75%的权重时,对于两个数据集(CBSD68 [43]和Set5 [7]),其在基准CBM3D [14]上的PSNR增益下降0.2-0.4 dB,甚至可能变为负数。另一个例子是对EDSR基线模型使用深度卷积[36]。尽管可以节省52-75%的复杂度,但是对于四个数据集(Set5,Set14 [61],BSD100 [43]和Urban100 [25]),质量下降的幅度为0.3-1.2 dB,从而使保存不合理。因此,我们需要面对计算成像CNN的计算需求。此外,高分辨率图像生成将使这一需求更具挑战性。例如,VDSR已经对全高清实时应用要求高达83 TOPS,而对于4K UHD则需要332 TOPS。(两个例子说明一味降低复杂度会让模型质量变差)
巨大的DRAM带宽和计算能力的问题促使我们找到一种用于超高分辨率CNN加速的新颖方法。在下文中,我们将提出基于块的推理低点和面向硬件的ERNet,以解决内存问题。粗粒度的FBISA和相应的高度并行的eCNN处理器将解决计算问题。
基于块的推理流程
为了减少这些开销,我们随后提出了截断的金字塔推断(输出块大于一个像素),如下所述。为了分析这种推断的开销较低,我们以图中的普通网络为例。它仅由CONV3×3层组成,因此接收场直接与深度D关联。随着卷积进入更深(上)层,有效区域将变小,成为截顶金字塔。例如,xi×xi输入块将生成xo×xo输出块,其中xo = xi-2D。当深度(接收量)增加时,将需要更多的输入块,因此需要更多的DRAM带宽,因为对于相同的输入块大小,生成的输出像素更少。可以通过归一化带宽比(NBR)来评估此带宽开销,该归一化带宽比等于所有输入和输出块的带宽超过输出图像的带宽:
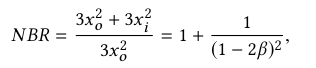
其中考虑了RGB图像,β是深度输入比D / xi。类似地,相邻块之间也存在用于重新计算的特征的计算开销。可以用归一化计算比(NCR)来评估它,它表示这种基于块的计算复杂度要比基于帧的计算复杂度低(本征):

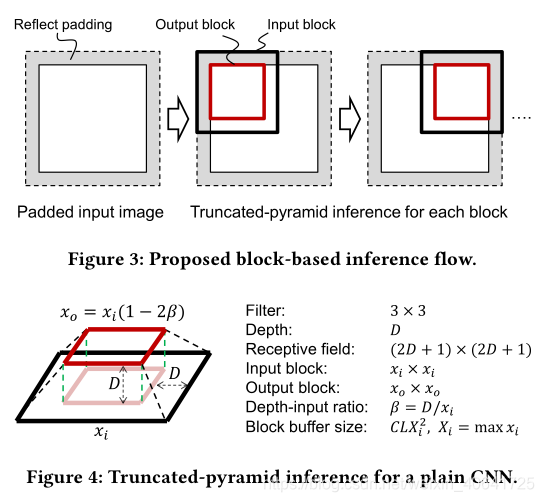
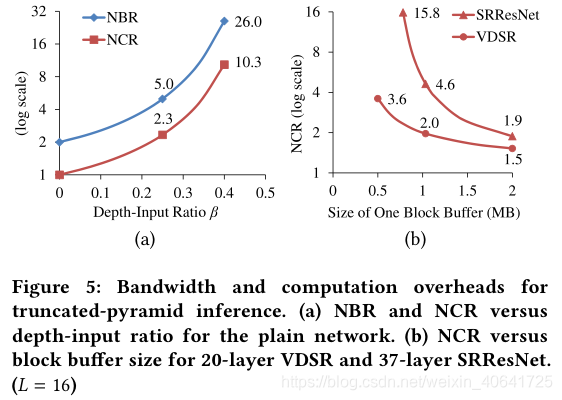
如图5(a)所示,这两个比率都相对于深度输入比率β迅速增长,并且对于xo = 0,即当无有效输出像素时,它们最终变为无穷大。如果β不太接近0.5,则与我们节省的带宽相比,诱导的带宽开销通常是可以接受的。例如,对于大的β= 0.4,NBR为26倍,而基于帧的低的带宽开销可以基于(1)推导为2C(D -1)3,对于VDSR则高达811倍。但是,计算开销确实成为基于块的低端算法的主要副作用。当β接近0.4时,我们将把90%的计算能力用于特征重新计算。为了避免这种情况,我们将需要采用更大的块缓冲区来减小更深层网络的β。上述普通示例的评估可以扩展到更复杂的模型,并且关于带宽和计算开销的结论是相似的。大多数最先进的网络都具有3×3(或更大)滤波器的深层和较宽的特征图通道,例如C≥64。因此,他们将需要CLX 2i大小的大型块缓冲区以减少NCR,或者使用小缓冲区节省面积时会产生较大的计算开销。注意,在输入层和输出层之间进行切换通常需要一个以上的块缓冲区,这使得面积成本更加严峻。图5(b)显示了VDSR在NCR和块缓冲区大小之间的权衡,以及最先进的SRResNet [35],其性能比VDSR高0.6 dB [36]。使用1MB块缓冲垫将20层VDSR的NCR很好地控制为2倍。但是具有类似NCR的37层SRResNet需要大约2MB。使用较小的缓冲垫来节省SRResNet的面积将使NCR迅速升空。因此,在基于块的低功耗的情况下,很难实现低NCR并同时将小型缓冲器用于深层高质量网络。在下文中,我们将在模型构建之初就考虑这些硬件约束,并相应地引入ERNet,以实现此目标。
ERnet
我们将首先介绍ERNet的基本构建模块,然后介绍模型优化的过程。我们还将讨论我们为动态定点精度采用的量化方法。
模型结构
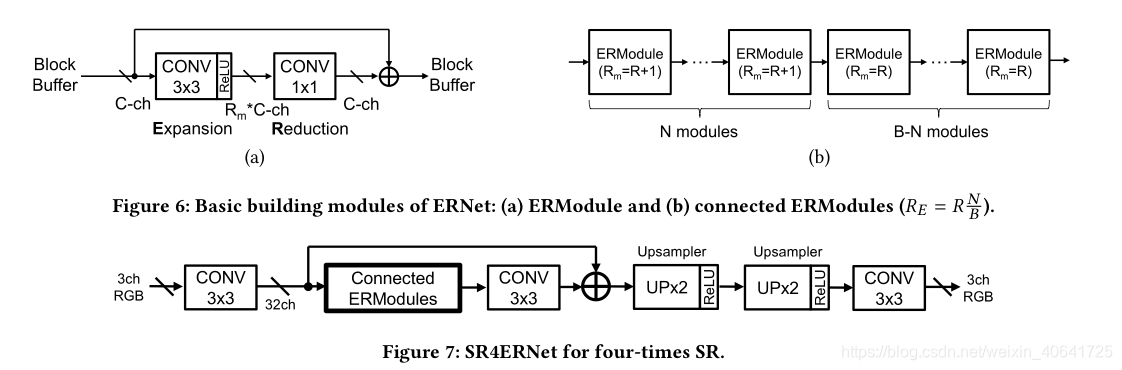
考虑一个可以使用小型块缓冲区的瘦网络。为了在不扩大NCR和缓冲区面积的情况下增加其容量,我们通过临时扩展模型宽度来探索模型构建的另一个方向。这是通过图6(a)所示的ERModule实现的。它使用CONV3×3层将模型宽度扩大Rm倍,然后使用CONV1×1减少模型宽度。添加了剩余连接以进行可靠的训练。所有操作均在内部执行,而无需访问块缓冲区。因此,我们可以将复杂度注入ERModule中,以在相同的块缓冲区大小和模型深度的情况下提高图像质量。我们仅考虑Rm的整数扩展比以确保较高的硬件利用率。为了增加模型的灵活性,我们通过连接B ERModule进一步构建了一个更大的构建块,如图6(b)所示。可以为第N个模块分配递增的Rm = R +1,以使总膨胀率RE为分数R N/B。因此,我们现在有两个模型超参数来构建网络:B用于增加深度,RE用于泵送复杂性。图7显示了用于执行四次SR的模型示例SR4ERNet。它基本上用ERModules代替了SRResNet [35]或EDSR基线[36]中的剩余块。它以宽度和高度为1/4的小图像开始,并使用两个像素集的上采样器恢复全分辨率。此外,我们将通道号从64减少到32,以节省块缓冲区的面积。
模型优化
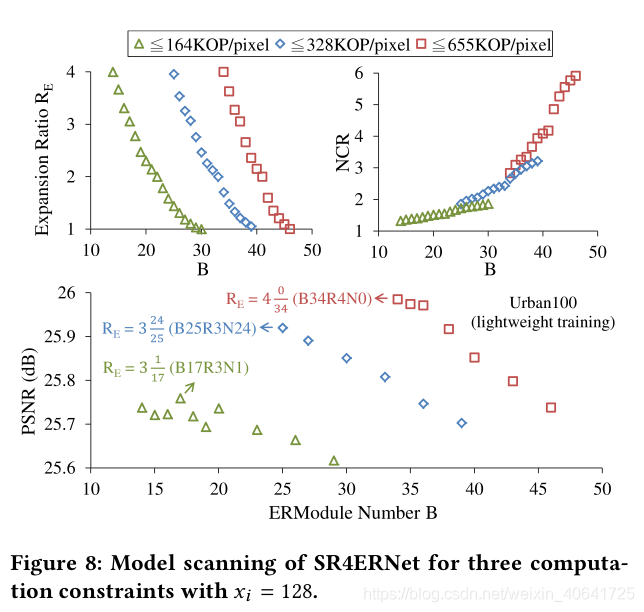
这里考虑的主要硬件约束是整体计算复杂度,即NCR×(内部复杂度),因为带宽开销通常很小。每个复杂性目标将对应一个实时吞吐量,我们的目标是在这种限制下优化图像质量。我们的模型选择过程可以使用SR4ERNet进行说明,如图8所示。我们假设输入块的大小为128×128,并考虑三个计算约束:164、328和655 KOP /像素(每个输出像素一万次操作)。首先,我们在每个约束条件下得出每个模块编号B的最大可能扩展率RE,然后选择RE≤4作为系统上限。如图8顶部所示,由于NCR的快速增加,随着模型深度随着B的增加,RE将迅速减小。在655 KOP /像素的情况下,NCR可以高达2.8-5.9×,相应的固有复杂度低至223-107 KOP /像素。请注意,较深的网络由于其固有的复杂性较低,因此不一定现在会表现更好。然后,我们使用轻量级训练设置(例如使用更小的补丁和更少的小批量。之后,我们使用验证数据集测试它们的图像质量,并为每个约束选择最佳模型,如图8的底部所示。最后,我们将通过对它们进行完整的设置再训练来进一步完善最佳模型。在此示例中,使用更薄,更不复杂的网络,最高质量的SR4ERNet-B34R4N0甚至可以比SRResNet超出0.04 dB。
动态定点精度
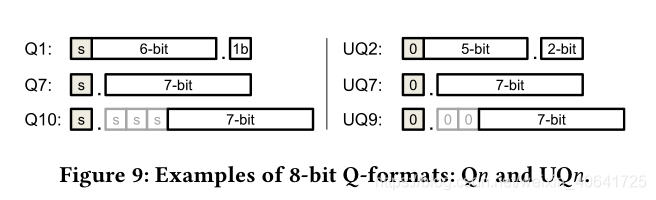
我们对小数采用固定点Q格式,Qn和UQn分别代表有符号和无符号值,n是最后一个有效位的小数位。我们采用动态定点精度来优化图像质量,因此每个卷积层分别具有自己的权重,偏差和特征输出的Q格式。然后,我们建立了一个两阶段的过程,即量化和微调。
量化阶段是确定每种Q格式的最佳分数精度。有了对应的浮点值的Ω个,我们可以使用L1-norm 或L2-norm 优化错误:
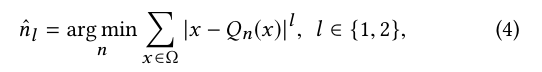
量化函数Qn(·)对精度n进行削波和舍入。参数的值分布是直接从滑动点模型导出的,特征图的值分布是通过在训练数据集上进行推理来收集的。由于这种8位量化会导致高达3.69 dB的PSNR损失以进行去噪和SR,因此我们在文献中使用了ine-tuning方法来调整这些量化参数。为了更准确地计算梯度,我们为模型的Qn(·)的修剪行为添加了修剪的ReLU(整流线性单位)函数。结果,固定点ERNet的PSNR平均降低仅为0.08 dB。
FBISA
我们设计了SIMD指令集FBISA,以支持全卷积网络的截断金字塔推论。为了增加其灵活性,我们还包括零填充推断类型以及上采样器和下采样器的变体。 FBISA通过功能块之间的粗粒度指令以及内部将依次引入的参数存储器来提供大量并行操作。
指令系统
图10示出了指令格式。操作码可以指定具有特定属性的卷积任务,例如推断类型和块大小。特征和参数分别有两种操作数,它们也有自己的属性,尤其是对于Q格式。对于功能操作数,有两种强制类型可以通知卷积的源(src)和目的地(dst)。此外,还设计了两个补充代码(srcS / dstS)以支持指令之间的特征累积,例如跳过/残余连接或部分和。最后,参数操作数指定在何处访问操作码的参数存储器中的相应权重和偏差。对于这些操作数,我们使用命名表达式而不是常规的有序表达式来提高可读性。
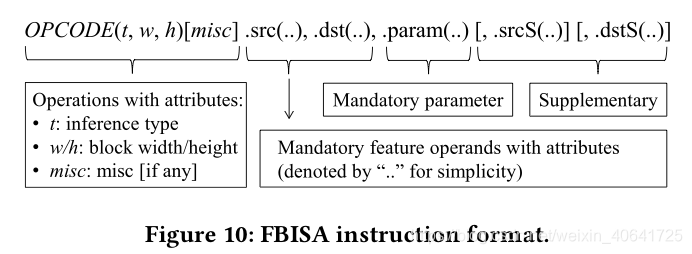
操作码主要在使用目的上有所不同,因此在输出的后处理上也有所不同。
关于特征操作数,我们应用两种策略来提供高效的数据移动,以实现高度并行的卷积。
首先,它们是基于块缓冲区(BB)而不是常规的小寄存器或向量来指定的。因此,一条指令的内部空间总和可以在硬件优化的数据路径中累积,而无需访问大型SRAM或DRAM,后者通常是带宽受限且耗电的。另一个优点是我们可以使用小型程序,而不必使用复杂的编译器。例如,高质量的SR4ERNet-B34R4N0仅使用45行指令。
第二种策略是不使用常规的负载存储指令来读取和写入外部功能。相反,我们将操作数DI和DO设计为分别用于数据输入和输出的虚拟块缓冲区。它们可以通过FIFO接口实现,并以与普通块缓冲区相同的方式流式传输数据。因此,可以针对仅计算指令集完全优化处理器管线。此策略还将FBISA与主内存中的数据结构分离,以实现更好的系统集成可移植性。
参数格式

















 1457
1457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









