






 本文详细介绍了MySQL的全局事务标识符(GTID)特性,包括GTID的概念、生命周期、维护以及如何处理GTID冲突。GTID提供了一种在集群中唯一标识事务的方法,简化了主从复制和故障转移,同时在MySQL Group Replication中起到关键作用。通过理解GTID的工作原理,DBA可以更高效地管理数据库集群。
本文详细介绍了MySQL的全局事务标识符(GTID)特性,包括GTID的概念、生命周期、维护以及如何处理GTID冲突。GTID提供了一种在集群中唯一标识事务的方法,简化了主从复制和故障转移,同时在MySQL Group Replication中起到关键作用。通过理解GTID的工作原理,DBA可以更高效地管理数据库集群。
GTID入门篇
GTID是全局事物标识符,是mysql5.6版本在主从复制方面推出的重量级特性。有了gtid,一个事物在集群中就不在孤独,在每一个节点中,都存在具有相同标识符的兄弟们和它作伴,同一个事物中就不在孤独,在每一个节点中,都存在具有相同标识符的兄弟们和它作伴,同一个事物,在同一个节点中出现多次的情况,也不会重现了,gtid的出现,直接的效果就是,每一个事物在集群中具有了唯一性的意义,这在运维方面意义非凡,给每个DBA带来了很大的便利性,再也不需要为了不断地找点而烦恼了。
- 根据GTID可以快速地知道事物最初是在哪个实例上提交的。
- 基于GTID搭建主从复制更简单,确保每个事物只会被执行一次。
- 基于GTID复制,可以方便地实现replication的failover,因为不用像传统复制模式那样去找master_log_file和master_log_pos.
- mysql group replication的节点间复制完全依赖gtid,并且在group replication集群节点进行recovery重新加入到集群中的操作中,会选择一个节点作为donor,然后基于purged的GTID开始同步数据。
- 同样是在mysqlgroupreplication中,集群使用GTID来表示事物,或者叫冲突验证,用于跟踪每个实例上提交的事物,确定哪些事物可能有冲突。
- GTID的引入让每一个事物在集群事物的海洋中有了秩序,使得DBA在运维中做集群变迁时更加方便,能够做到心中有数。
GTID概念
什么是GTID
每提交一个事物,当前执行线程都会拿到一个唯一标识符,此标识符不仅对其源mysql实例是唯一的,而且在给定的复制环境中的所有mysql实例中也是唯一的,所有事物与其GTID中间都是一一对应的,GTID的格式如下,
GTID=SOURCE_ID:SEQUENCE_ID,
GTID由两部分组成,source_id和sequence_id,source_id是源服务器唯一标识,通常使用服务器的server_uuid来表示source_id,sequence_id是在事物提交时由系统顺序分配的一个序列号,相同source_id值的事物对应的sequence_id在binlog文件中是递增且连续有序。
可以通过showmasterstatus或showslavestatus查看当前实例执行过的GTID信息,它以集合的方式呈现。
mysql> show master status\G
*************************** 1. row ***************************
File: mysql-bin.000001
Position: 32372
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 807de6b3-c4d3-11e7-954f-000c29b46750:1-69
1 row in set (0.00 sec)
本实例中source_id为807de6b3-c4d3-11e7-954f-000c29b46750,总共提交了69个事物。
GTID始终保存在主从实例中,可以通过检查二进制日志来确定事物的来源,此外,一旦在给定的mysql实例中提交了事物,具有相同GTID的事物便会被该台服务器忽略,而且在主实例上提交的事物在从库上只可以应用一次,这有助于保持主从的一致性。
GTID生命周期
GTID的生命周期如下:
1.master产生GTID。
在master上执行一个事物,master将会产生一个GTID信息,并保存到binlog中。
2.发送binlog信息到从库上。
将二进制日志信息发送到SLAVE所在的服务器上,并且存储到relay log中,SLAVE读取GTID并设置其gtid_next的值为GTID值,从而告知SLAVE必须使用此GTID记录下一个事物。
3.SLAVE执行GTID
SLAVE首先验证其是否已经在自己的二进制日志中使用过该GTID号,如果未使用过,SLAVE首先读取和检查事物的GTID,应用其事物,并将事物写入二进制日志。SLAVE首先读取和检查事物的GTID,在提交事物前,SLAVE不仅要保证SLAVE没有应用具有该GTID的事物,并且还要保证没有其他会话已经读取了该GTID但尚未提交,即不允许多个客户端应用相同的事物。
4.SLAVE不生成GTID
由于gtid_next不为空,SLAVE不会尝试为该事物生成新的GTID,而是从gtid_next中读取GTID值并写入二进制日志中,来表示一个事物的GTID值,之后在集群中都会始终对应这个GTID值,且不会发生变化,起到了身份证标签的作用。
GTID的维护
gtid_executed表
在mysql5.7版本及以上的版本中,mysql库中新增了表gtid_executed,表结构如下所示,该表中的每一行表示一个GTID或GTID集合,包括source_uuid,集合开始和结束的事物ID。
mysql> show create table mysql.gtid_executed\G
*************************** 1. row ***************************
Table: gtid_executed
Create Table: CREATE TABLE `gtid_executed` (
`source_uuid` char(36) NOT NULL COMMENT 'uuid of the source where the transaction was originally executed.',
`interval_start` bigint(20) NOT NULL COMMENT 'First number of interval.',
`interval_end` bigint(20) NOT NULL COMMENT 'Last number of interval.',
PRIMARY KEY (`source_uuid`,`interval_start`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
mysql> select * from mysql.gtid_executed;
+--------------------------------------+----------------+--------------+
| source_uuid | interval_start | interval_end |
+--------------------------------------+----------------+--------------+
| 807de6b3-c4d3-11e7-954f-000c29b46750 | 1 | 15 |
| d915aee5-d6bd-11e7-ac78-000c29491195 | 1 | 2 |
+--------------------------------------+----------------+--------------+
2 rows in set (0.00 sec)
只有gtid_mode=on或者on_permissive时,GTID才会保存在mysql.gtid_executed表中。gtid存储在该表中,不会考虑是否启用了二进制日志。
*当未启用binlog时,每个事物都会记录到gtid_executed表中。
*当启用binlog时,每个事物不仅会记录到gtid_executed表中,而且当binlog rotate或服务器关闭时,服务器会将GTID信息写入到新的二进制日志,如果服务器异常关闭,GTID不会被存入mysql.gtid_executed表中,那么在这种情况下,mysql在恢复时,会将这些GTID信息添加到表中,并写入到gtid_executed系统变量中。
(注)reset master操作会清空gtid_executed表。
gtid_executed表压缩
随着数据库的不断更新,mysql.executed表会存入很多GTID信息,并且这些事务ID会构成一个序列,如下:
mysql> select * from mysql.gtid_executed;
+--------------------------------------+----------------+--------------+
| source_uuid | interval_start | interval_end |
+--------------------------------------+----------------+--------------+
| 807de6b3-c4d3-11e7-954f-000c29b46750 | 1 | 15 |
| d915aee5-d6bd-11e7-ac78-000c29491195 | 1 | 2 |
+--------------------------------------+----------------+--------------+
可以通过事务的间隔来代替原来的每个GTID信息,来缩减磁盘空间的消耗。
当mysql启用GTID时,服务器会定期对mysql。gtid_executed表执行雷士的压缩,可以通过设置executed_gtids_comperiod变量来控制在压缩表之前允许的事务数,从而控制压缩率。该变量的默认值是1000,表示表的压缩在没1000个事物之后执行,设置为0 表示不执行压缩。
(注)当binlog开启,且executed_gtids_compression_period值为使用时,mysqlbinlog轮换会引起gtid_executed表的自动压缩。
mysql中有一个单独的后台线程来执行gtid_executed表压缩的操作,线程信息如下:
mysql> select * from performance_schema.threads where name like '%gtid%'\G
mysql> select * from performance_schema.threads where name like '%gtid%'\G
*************************** 1. row ***************************
THREAD_ID: 26
NAME: thread/sql/compress_gtid_table
TYPE: FOREGROUND
PROCESSLIST_ID: 1
PROCESSLIST_USER: NULL
PROCESSLIST_HOST: NULL
PROCESSLIST_DB: NULL
PROCESSLIST_COMMAND: Daemon
PROCESSLIST_TIME: 75277707
PROCESSLIST_STATE: Suspending
PROCESSLIST_INFO: NULL
PARENT_THREAD_ID: 1
ROLE: NULL
INSTRUMENTED: YES
HISTORY: YES
CONNECTION_TYPE: NULL
THREAD_OS_ID: 12431
1 row in set (0.00 sec)
该线程睡眠直到执行了gtid_executed_compression_period事务后,唤醒该线程执行gtid_executed表的压缩,然后继续睡眠,如此循环,当禁用二进制日志并且将此变量设置为0时,该线程永远不会被唤醒。
如何跳过一个GTID?
在复制中偶尔会遇到主键冲突或从库找不到该条记录等错误,那么如何解决呢?
在传统的复制模式中,经常通过设置sql_slave_skip_counter参数跳过一个事件。
但在GTID模式中,修改该参数会报错。
在GTID模式的复制情况下,如果SLAVE发生错误,则可以通过跳过该事物的方式回复主从复制
如下:出错位置为:如下:log mysql-bin.000001, end_log_pos 1878,起始位置为: Exec_Master_Log_Pos: 1642;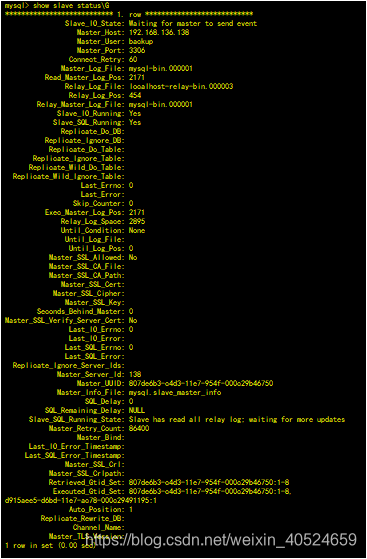
那么根据如上信息去查找主上的binlog并解析:
mysqlbinlog -vv --base64-output=decode-rows mysql-bin.000001 >1.txt
less 1.txt
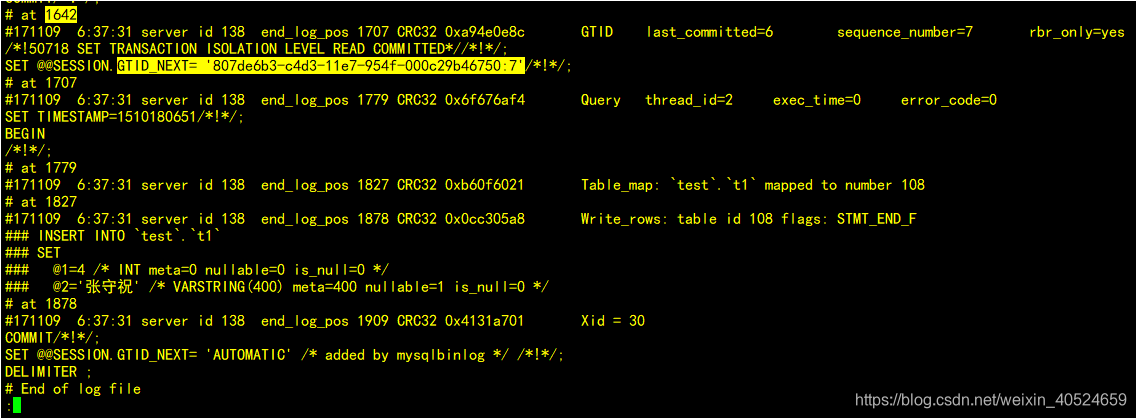
可以看到发生冲突的事务号为807de6b3-c4d3-11e7-954f-000c29b46750:7,当然也可以在从服务器直接show slave status,结果中通过比对的方式找到冲突的位置,严谨起见,通过对binlog内容分析得知冲突事物是插入了一条数据,主键为4.在从库中查看这条记录是否真的存在。
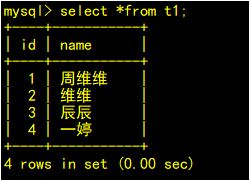
果然,发现SLAVE中已经存在这条记录了。这时,可以通过跳过该事务的方式来放弃该事务在slave上的执行,使SLAVE能够正常运行。基于GTID的复制,跳过一个事物,需要利用一个空事物来完成。
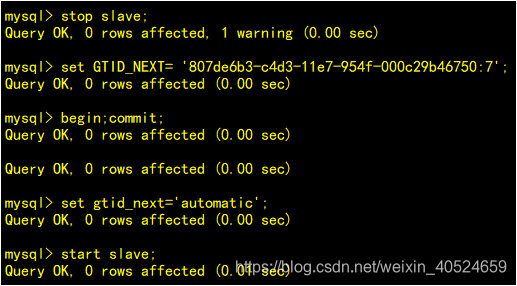
在备机查看已经同步了新的数据,并且主备状态正常。
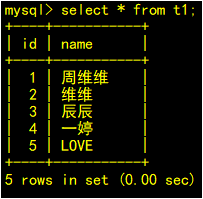
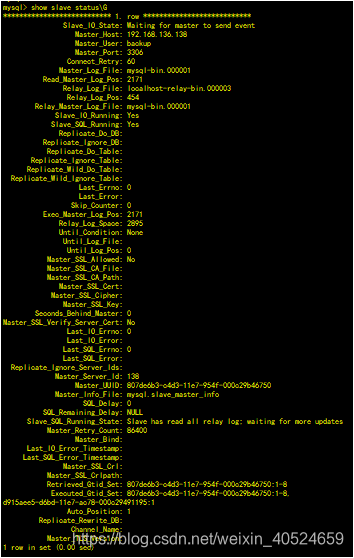
综上,备机已经跳过一个事务,同步关系已经恢复正常,其实数据还是不一致的,如果删除数据时,因为找不到对应的记录,而导致复制中断,该如何处理?如果是其他的错误呢,又该如何处理?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









