







书籍推荐
Apache Kafka源码剖析,Kafka技术内幕
kafka 要点 0.10版本
生产者发送消息流程
服务端写数据流程
服务端元数据管理流
消费者消费数据流程
生产者发送消息流程
1 获取元数据信息 (才能分区计算后知道消息写入哪些分区)
kafka生产者有3个必选的属性之一bootstrap.servers
该属性指定broker的地址清单,地址的格式为host:port。
清单里不需要包含所有的broker地址,生产者会从给定的broker里查找到分区对应的leader partition的broker地址
默认配置每5分钟自动更新一次元数据
2 发送 (Kafka采用异步)
同步发送
发送消息后等待服务端响应才会继续发送
异步发送
一直发送,消息响应结果交给回调函数处理
一次可以发送的数据最大默认1mb,公司经验可以改为10mb(因为kafka很多消息合并为一条减少网络压力)
额外一些启动参数配置:
发送缓存大小默认128k,接收32k
可以设置压缩格式(提高cpu压力,一次发送更多数据)
默认空闲网络连接9分钟,超过则关闭网络连接
默认producer可以忍受发送给5个broker没有响应(这种情况重试发送会导致乱序,所以需要保证发送有序时该参数得改为1)
简单流程图
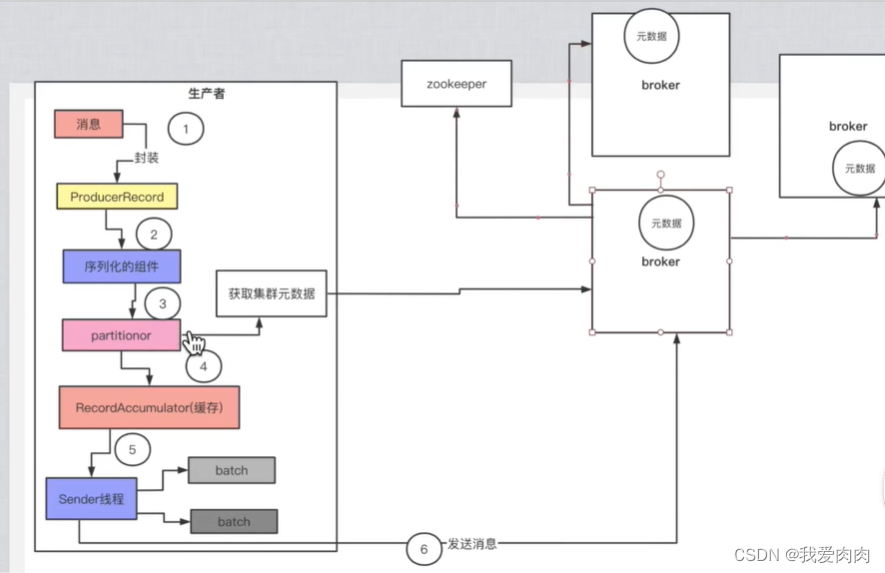
略微详细的流程图
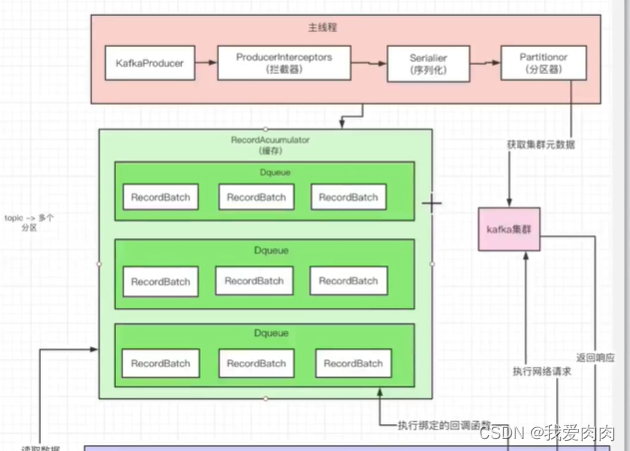
元数据封装信息
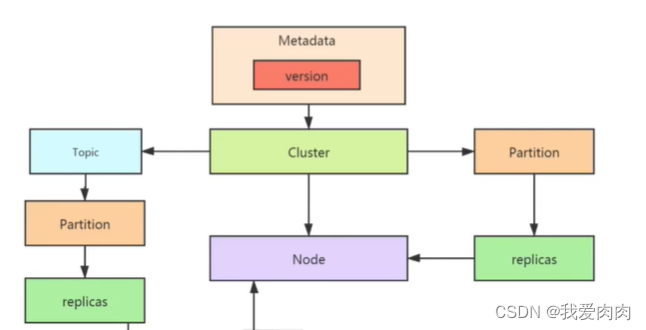
元数据更新流程
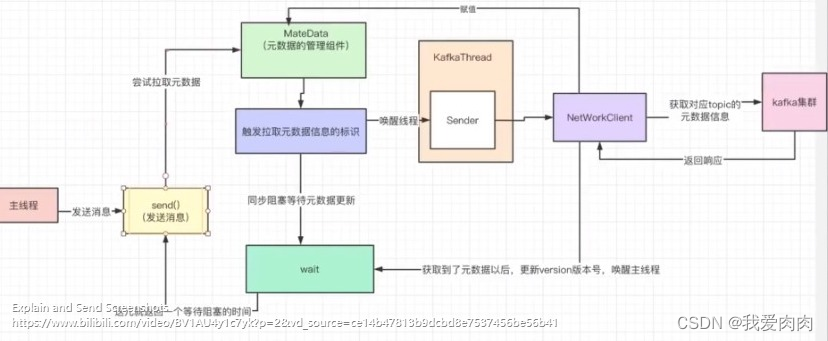
Kafka 缓存RecordAccmulator封装消息
1 同步等待元数据拉取
sender线程真正发送网络请求获取元数据,版本号+1。之后唤醒主线程完成元数据更新
通过比较元数据版本号大小来判定是否获取到最新元数据
2 对元数据key/value序列化
3 计算分区号
- 看消息是否主动分配分区号(一般没有),如有则不用再计算
- 分区器分区
不指定key:轮询的方式,对可用的分区数取模
指定key:对key hash取值,再对可用分区取模
4 校验如果一条消息大小超过设定值则报异常,默认1mb
5 根据元数据信息,封装分区对象
6 给每条消息绑定回调函数,异步
7 消息放入accmulator(32mb的内存)
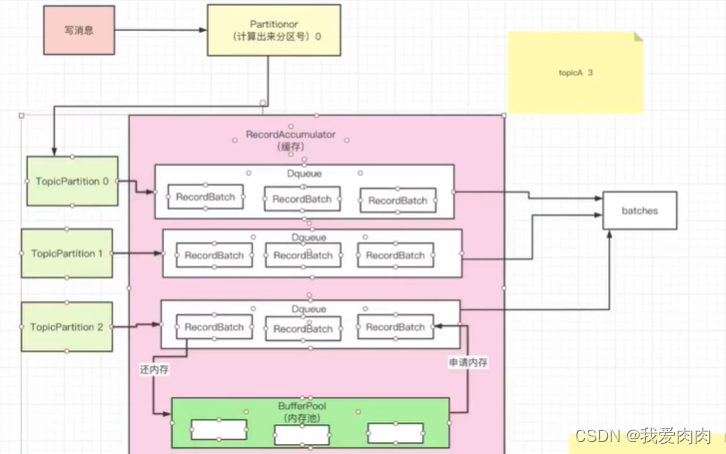
内存结构 ConcurrentHashMap<TopicPartition, Deque<RecordBatch>> batches = new CopyOnWriteMap<>()
1 由accmulator获取各个分区为key对应的value数据队列,图上的Deque<RecordBatch>
2 Dequeue中peekLast获取队列批次RecordBatch写入消息(第一次peek是获取失败的,需要自己创建RecordBatch批次)
3 计算一个批次的大小,在消息大小和批次累计消息大小中取大值,默认批次大小16k,消息积压达到16kb就会发送
(如果一个消息大小超过16k,则直接发送,也就是一条一条发送,不是批量,如果失去了批量特性则影响性能,最好调整16k配置)
4 根据批次大小申请内存,封装批次插入队列,发送
Kafka 自定义实现高性能CopyOnWriteMap
缓存内存结构 ConcurrentHashMap<TopicPartition, Deque<RecordBatch>> batches = new CopyOnWriteMap<>()
volatile Map<K,V> map,通过volatile线程安全的不上锁读,读性能很好
map写方法加了synchronized锁,方法内new新map内存空间,新map内写数据,然后新map直接覆盖
写流程在新内存中,通过开辟新内存空间实现读写分离
该场景如果少读多写,性能很差。适合多读少写场景
JUC只有CopyOnWriteArrayList,kafka自己设计了CopyOnWriteMap来提高缓存并发性能,面对多读少写
假设一个topic 100个分区,每秒写入一万的消息,则缓存就是插入100次数据,每个队列只插入一次。但是每秒要读取一万次
因为会高频的读取出来一个TopicPartition对应的Deque数据结构,来对这个队列进行入队出队等操作
Kafka 数据写入缓存对应批次的分段加锁
dp 单独设计读多写少的设计结构,对应分区的队列
队列有批次则直接获取,无批次则线程根据计算的批次大小申请内存,封装批次插入队列,释放锁
能不上锁则不上锁,能逻辑拆分分段上锁则分段

Kafka 内存池设计
0.10版本之后才有
分配内存
一个队列,队列内封装一块一块的内存
RecordAccmulator缓存默认32mb,由 内存池 + 可用内存组成
一开始内存池为空,可用内存为32mb。当内存不断被申请使用后回收到内存池,可用内存不断变小
当内存不足时,则放入waiters队列等待内存,先一点一点分配内存,然后不断while循环持续分配释放出来的内存直到完全符合内存需求
释放内存
判断批量内存是否为配置的批次大小(16k),是16k则clear buffer并将内存放入内存池。
内存是一块一块16k使用,16k释放的,不需要关心碎片化
Why 比较批次16k大小才释放?
为了提高批次内存使用率,内存用满16k才释放,不浪费空间。如果内存分配不统一16k,内存利用率会降低
如果批次大小不是16k,则代表内存没有最大化利用率,这种情况判定为性能很差的内存,则放入可用内存,等待垃圾回收
所以内存池设计是为了减少触发垃圾回收的概率。合理使用的内存块则放入内存池,不合理使用的内存块则放入可用内存,最后GC可用内存
所以内存批次发送的大小参数配置很重要,默认16k,代表数据累计满16k则发送一次。消息如果不能正常累计到16k则会很大的影响性能,需要优化调整参数。例如当一条消息大于16k,则不会批量发送,一次只会发送一条大消息,增加网络压力。并且也不会判定为符合要求的内存块,不会放入内存池中,会直接放入可用内存,无法通过内存池来优化full GC问题
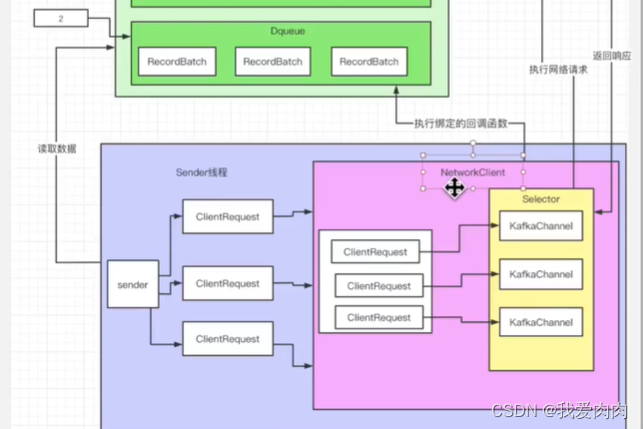
Kafka 消息批次发送
Sender线程按照broker分组,同一个broker的不同partition会分为同一组发送,来减小网络压力
发送条件:
消息批次默认配置最多等待100ms则发送,哪怕还没满16k(满足16k/内存不足也直接发送消息批次)
生产者:缓存多个连接,数量就是broker节点数量
kafka selector是基于java NIO selector封装实现的,一个selector绑定多个kafkaChannel,也就是多个连接
每个往broker发送消息的连接,参数默认配置最多容忍5个请求发送出去但没有响应
Why不用Netty
更灵活,但模仿了Netty设计理念


















 1086
1086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











