







 本文深入浅出地介绍了哈希表(Hash Table)的概念和作用,通过生活中的通讯录例子帮助理解。讨论了哈希函数、哈希冲突及其解决方法,包括开放定址法和链地址法。接着,文章探讨了Python中字典(Dict)与哈希表的关系,指出Python 3.6之前和之后字典的底层实现变化,解释了字典为何无序以及3.6版本后的有序性改进。最后,强调了字典遍历顺序的重要性。
本文深入浅出地介绍了哈希表(Hash Table)的概念和作用,通过生活中的通讯录例子帮助理解。讨论了哈希函数、哈希冲突及其解决方法,包括开放定址法和链地址法。接着,文章探讨了Python中字典(Dict)与哈希表的关系,指出Python 3.6之前和之后字典的底层实现变化,解释了字典为何无序以及3.6版本后的有序性改进。最后,强调了字典遍历顺序的重要性。
摘要
首先说明,以下几类读者请自行对号入座:
- 刚接触编程并对底层原理知之甚少,但又想了解一下数据结构的读者,强烈建议阅读此篇;
- 计算机专业在读,对编程有一定了解,但对数据结构不够熟悉的读者,强烈建议阅读此篇;
- 传统运维想要快速上手自动化,没有精力对底层原理做深入了解的,请跳过此番外篇系列;
- 计算机专业出身并对数据结构有系统了解的读者,请跳过此系列番外篇。
我们在【自动化运维番外篇】数据结构-2 中讲Python中的列表类型与数据结构中的数组进行了详细的讲解和比较,相信大家在操作列表的时候应该都心里更有底了。
这篇我们就来着重讲解一下数据结构中的哈希表与Python中的字典类型,并且告诉大家为什么字典是无序的,顺带破除一下网上大部分博客对于这一知识点的误解。
哈希表(Hash Table)
百度百科:
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构。
它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录。
这加快了查找速度,这个映射函数称做散列函数,存放记录的数组称做散列表。
我觉得一般百度百科对专业名词做出的解释,都让人一脸懵X,本来想搞懂一个知识点,结果它一解释,不懂的知识点更多了。
因为我们完全不知道这个东西的用途,也就无法对其有准确的认知。
我下面用一个生活中最常用到的东西来给大家讲解一下哈希表。
【通讯录】
微信好友列表中好友排列就是一个按名字散列的通讯录,通讯录其实就是一个简易的哈希表。

大家可以假设如果没有按名字散列,那么微信好友的展示就只能按添加的先后顺序排列,这样我们在找某个好友时的效率就会很低,因为我们知道TA的名字,但不知道他保存在什么位置,只能从头翻到尾。
但如果我们按名称散列之后,我们就可以按照好友名称的拼音首字母很快的检索到好友。
这里取一个人名字的首字母,就是一种十分简单的哈希方法,而按名字哈希之后存放的容器就是一个表,我们上一讲中提到决定了数据顺序和位置关系的便是“数据结构“,那么上述的这种方式就是决定了我们好友数据的顺序和储存的位置关系,它就属于数据结构的一种:哈希表。
回过头来我们将百度百科的定义用微信好友的场景翻译一下就是:
散列表(Hash table,也叫哈希表),是根据首字母而直接访问好友位置的数据结构。
它通过计算一个关于名字首字母函数,将所需查询的好友映射到表中一个位置来访问记录。
这加快了查找速度,这个映射函数称做散列函数,存放记录的数组称做散列表。
这下是不是清晰很多了,当我们对哈希表的应用有了大致的了解之后,我们就该着重深入一下具体的实现方式。
【哈希函数】
上面我们提到关于名字首字母的函数可以称为哈希函数,而哈希函数的构造方法有很多中,哈希算法也是千变万化的,但大多都需要考虑以下五个因素:
- 计算散列地址所需要的时间(即hash函数本身不要太复杂)
- 关键字的长度
- 表长
- 关键字分布是否均匀,是否有规律可循
- 设计的hash函数在满足以上条件的情况下尽量减少冲突
所以哈希函数十分好理解,就是将我们要存储的元素按某种方式计算出一个值,这个值对应数组的某个位置,然后将这个元素存储进去。

比如我有一个上述元素的数组,哈希函数为:H(key) = key mod 11,现有17,60,29三个元素,分别做哈希之后,得到的下标分别就是6,5,7,所以将他们存储在数组的指定位置上,但是聪明的读者这时候就会有一个疑问,如果再存一个38怎么办,它对应的下标仍然是5,这就涉及到了哈希冲突。
【哈希冲突】
任何哈希函数,都会出现两个不同元素映射到同一个位置上的情况,这种情况叫做哈希冲突。
解决哈希冲突的方法一般有:开放定址法、链地址法(拉链法)、再哈希法等方法。
开放定址法
从发生冲突的那个单元起,按照一定的次序,从哈希表中找到一个空闲的单元。然后把发生冲突的元素存入到该单元的一种方法。开放定址法需要的表长度要大于等于所需要存放的元素。
在开放定址法中解决冲突的方法有:线性探查法、平方探查法、双散列函数探查法。
1 线行探查法
线行探查法是开放定址法中最简单的冲突处理方法,它从发生冲突的单元起,依次判断下一个单元是否为空,比如元素38,对11取余之后为5,但5位置已经被占了,那就继续看6,但6也被占了,以此类推,最终发现8位置是空的,所以存在8。

2 平方探查法
平方探查法即是发生冲突时,用发生冲突的单元d[i], 加上 1²、 2²等。即d[i] + 1²,d[i] + 2², d[i] + 3²…直到找到空闲单元。

3 伪随机数探测法
每次加上一个随机数,直到探测到空闲位置结束。

再哈希法
当通过哈希函数求得的哈希地址同其他关键字产生冲突时,使用另一个哈希函数计算,直到冲突不再发生。
链地址法
将所有产生冲突的关键字所对应的数据全部存储在同一个线性链表中。例如有一组关键字为{19,14,23,01,68,20,84,27,55,11,10,79},其哈希函数为:H(key)=key MOD 13,使用链地址法所构建的哈希表如下图所示:
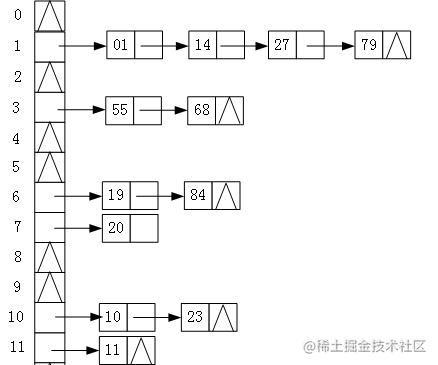
所以了解到哈希函数和哈希冲突之后,几乎就掌握了哈希表的基本原理,下面我们就看看Python中的字典和哈希表究竟有什么样的关系?
字典(Dict)
Python的字典格式就是键值类型,每个键对应一个值,使用的是伪随机数探测法解决哈希冲突。
但根据我们对数据结构中哈希表的学习来看,我们在遍历字典的时候并不会按我们存进去元素的顺序取出来的,这就是为什么说Python的字典是无序的,但为什么又说Python3.6之后又是有序的了呢,这就要看字典的底层实现了
【Python3.6之前】
字典的底层实现实际就是一张hash表,简单可以理解为一个列表,列表中的每一个元素又保存了三个元素,分别是哈希值(hash value)、键(key)和值(value)。
my_dict = {}
'''
这时的内存如下
entries = [
[--, --, --],
[--, --, --],
[--, --, --],
[--, --, --],
[--, --, --]
]
'''
当我们往字典里添加一个数据的时候
my_dict["test"] = "ethan" # 通过计算 hash("test") % 5 = -3002718498575948766 % 5 = 4
'''
这时的内存示意图如下
entries = [
[--, --, --],
[--, --, --],
[--, --, --],
[--, --, --],
[-3002718498575948766, 指向name的内存地址, 指向ehtan的内存地址],
[--, --, --]
]
'''
当我们要按test键对应的值时,同样会经过计算 hash(“test”) % 5,得到结果为4,然后从entries中读取4下标对应的值。
当我们继续往字典里添加数据时同理
my_dict["age"] = 18
my_dict["locate"] = "BJ"
'''
这时的内存示意图如下
entries = [
[--, --, --],
[-6504424719545881419, 指向locate的内存地址, 指向BJ的内存地址],
[-9004587017580859628, 指向age的内存地址, 指向18的内存地址],
[--, --, --],
[-3002718498575948766, 指向name的内存地址, 指向ehtan的内存地址],
[--, --, --]
]
'''
当要循环遍历字典的时候,Python底层会遍历这个二维数组,如果当前行有数据,那么就返回Key指针对应的内存里面的值。如果当前行没有数据,那么就跳过。所以总是会遍历整个二位数组的每一行。所以可以很直观的看到,遍历时候的顺序并不是我们插入时的顺序。
【Python3.6之后】
在Python3.6的版本之后,字典的底层实现发生了很明显的变化
my_dict = {}
'''
这时的内存示意图如下
indices = [None, None, None, None, None] 索引表
entries = [] 哈希表
'''
当我们插入数据时内存的变化如下
my_dict["age"] = 18
'''
# 使用hash("age") % 5 = 2, 所以在indices下标为2的位置存储0,这个0对应entries中实际元素存储的下标
这时的内存示意图如下
indices = [None, None, 0, None, None]
entries = [
[-9004587017580859628, 指向age的内存地址, 指向18的内存地址],
] 哈希表
'''
以此类推
my_dict["test"] = "ethan"
'''
# 使用hash("test") % 5 = 4, 所以在indices下标为4的位置存储1,这个1对应entries中实际元素存储的下标
这时的内存示意图如下
indices = [None, None, 0, None, 1]
entries = [
[-9004587017580859628, 指向age的内存地址, 指向18的内存地址],
[-3002718498575948766, 指向name的内存地址, 指向ehtan的内存地址],
] 哈希表
'''
当要读取test键对应的值时,hash(“test”) % 5 = 4,我们查找indices中下标为4的位置存的是1,这时候再去entries中取出下标为1的位置存放的元素。
当使用新的底层结构后发现,插入和索引依然有效,而且可以解决entries中存在空余空间的问题,并且在对字典进行遍历的时候,可以直接遍历entries,而entries中存储的顺序就是我们插入数据时的顺序。
总结
这一节我们主要由浅入深了解了数据结构中的哈希表的应用和底层的原理,并且对Python中的字典也做出了详细的解释,而且解决了一个很大的知识点,那就是字典有序性问题,所以如果读者朋友你的Python环境还在3.6版本之前,那就需要在写代码的时候格外注意这个问题了。
欢迎大家添加我的个人公众号【Python玩转自动化运维】加入读者交流群,获取更多干货内容


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









