







 本文深入探讨了数据库中的窗口函数,包括其语法规则、各种函数类型如排位函数、聚合函数、偏移函数和分布函数的使用。通过实例展示了如何在不减少数据行数的情况下实现分组、排序、累计和统计等功能。窗口函数在数据查询和分析中发挥着重要作用,能够高效地处理复杂的数据操作需求。
本文深入探讨了数据库中的窗口函数,包括其语法规则、各种函数类型如排位函数、聚合函数、偏移函数和分布函数的使用。通过实例展示了如何在不减少数据行数的情况下实现分组、排序、累计和统计等功能。窗口函数在数据查询和分析中发挥着重要作用,能够高效地处理复杂的数据操作需求。
想象这样一种场景,既想保留所有数据,又想得到按某几列分组的聚合值,或者再对数据进行排序,要如何实现呢?这时候开窗函数就有了用武之地,聚合函数每组只保留一个值,而开窗函数可以在不减少原表行数的情况下,实现分组和排序的功能。
语法规则
窗口函数 over (partition by <用于分组的列名> order by <用于排序的列名> [desc] <倒序排列>)
排位函数
括号里留空,不写参数
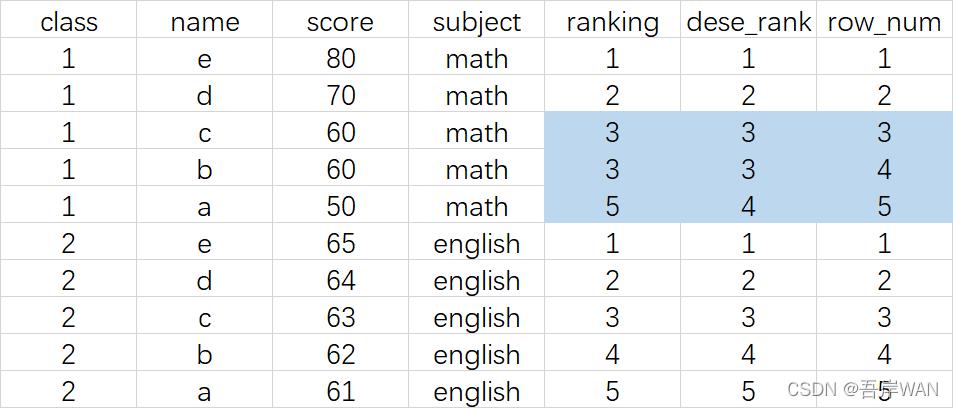
- rank() 相等的值排名相同,但若有相等的值,则序号从1到n不连续。如果有两个人都排在第3名,则没有第4名。
- dense_rank() 相等的值排名相同,但序号从1到n连续。如果有两个人都排在第3名,则第五个人排在第4名。
- row_number() 相等的值对应的排名不同,序号从1到n连续。可以理解为行号。
select *,
rank() over (partition by class order by score desc) as ranking,
dense_rank() over (partition by class order by score desc) as dese_rank,
row_number() over (partition by class order by score desc) as row_num
from test.demo_windows;
聚合函数
sum(),count(),max(),min(), avg() 等
聚合函数作为窗口函数相当于截止到当前数据的累计值
select *,
sum(score) over (partition by class order by score desc) as current_sum,
avg(score) over (partition by class order by score desc) as current_avg,
count(score) over (partition by class order by score desc) as current_count,
max(score) over (partition by class order by score desc) as current_max,
min(score) over (partition by class order by score desc) as current_min
from test.demo_windows;
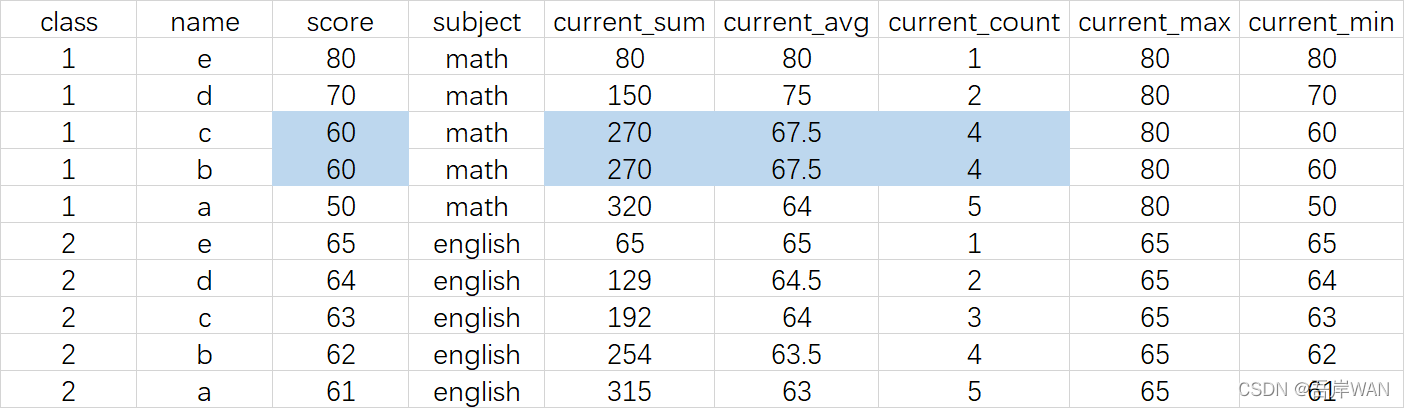
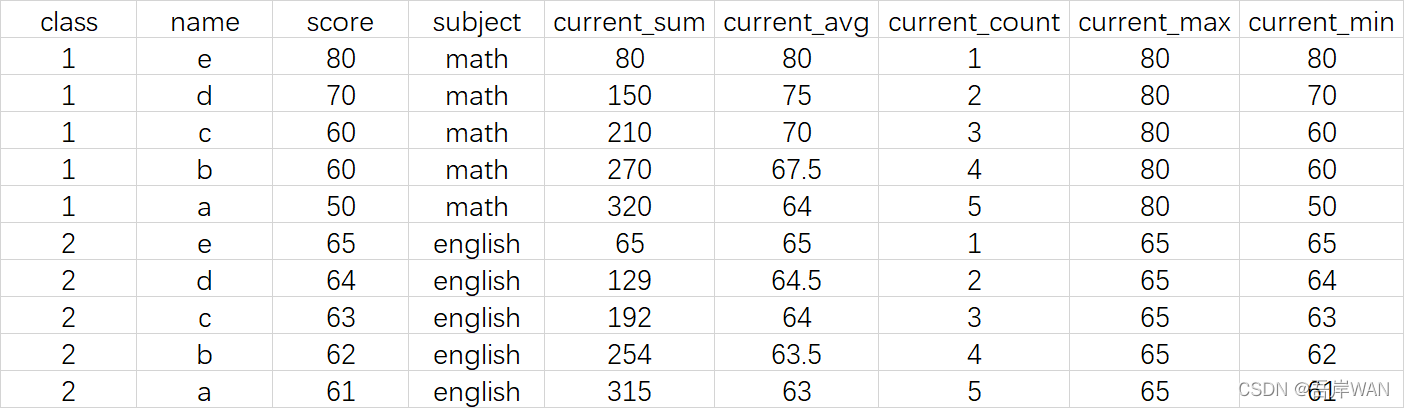
从上图的结果我们可以发现,当order by 排序的字段相同时,相同的数据会一起计算出来,要注意计算的是截止到当前值而不是当前行。如果要实现逐行累计,则需要添加语句:
rows between unbounded preceding and current row
表明范围,从第一行到当前行
select *,
sum(score) over (partition by class order by score desc rows between unbounded preceding and current row) as current_sum,
avg(score) over (partition by class order by score desc rows between unbounded preceding and current row) as current_avg,
count(score) over (partition by class order by score desc rows between unbounded preceding and current row) as current_count,
max(score) over (partition by class order by score desc rows between unbounded preceding and current row) as current_max,
min(score) over (partition by class order by score desc rows between unbounded preceding and current row) as current_min
from test.demo_windows;
偏移函数
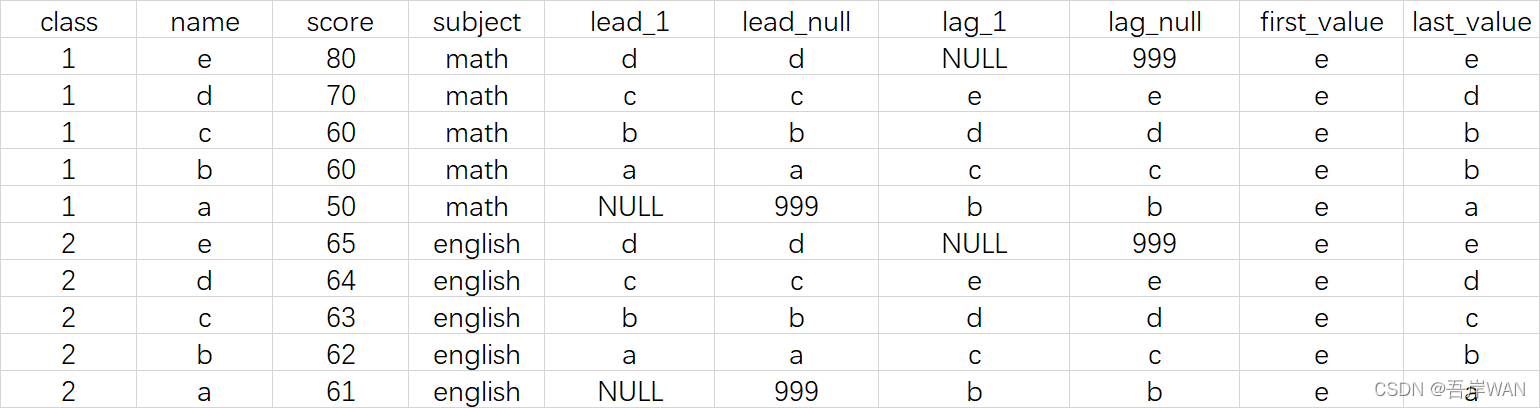
- lead(col,n,默认值) :用于统计窗口内往下第n行值。第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值,当往下第n行为NULL时取默认值,如不指定则为NULL。
- lag(col,n,默认值) :与lead相反,用于统计窗口内往上第n行值。
- first_value():取分组内排序后,截止到当前行,第一个值
- last_value(): 取分组内排序后,截止到当前行,最后一个值
select *,
lead(name,1) over (partition by class order by score desc) as lead_1,
lead(name,1,999) over (partition by class order by score desc) as lead_null,
lag(name,1) over (partition by class order by score desc) as lag_1,
lag(name,1,999) over (partition by class order by score desc) as lag_null,
first_value(name) over (partition by class order by score desc) as first_value,
last_value(name) over (partition by class order by score desc) as last_value
from test.demo_windows ;
分布函数
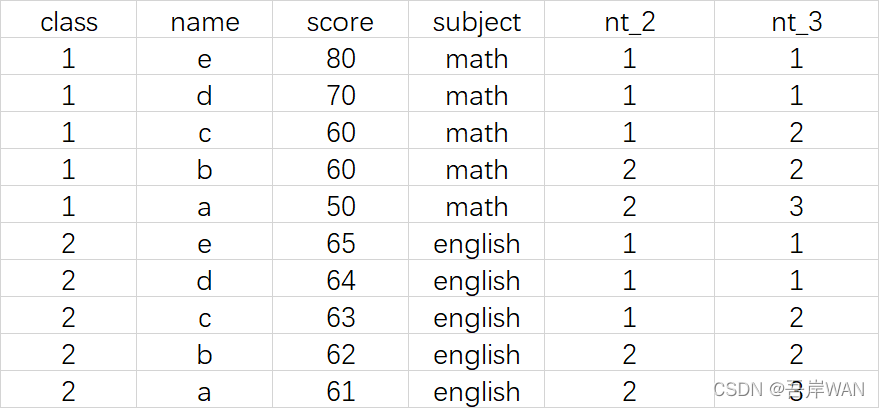
- ntile(n) 用于将分组数据按照顺序切分成n片,返回当前切片值,如果切片不均匀,默认增加第一个切片的分布,各个切片能放的数据条数最多相差1。
按分位数统计的时候可以用,比如取销量前四分之一的数据,筛选ntile(4) = 1 即为想要的结果
select *,
ntile(2) over (partition by class order by score desc) as nt_2,
ntile(3) over (partition by class order by score desc) as nt_3
from test.demo_windows ;
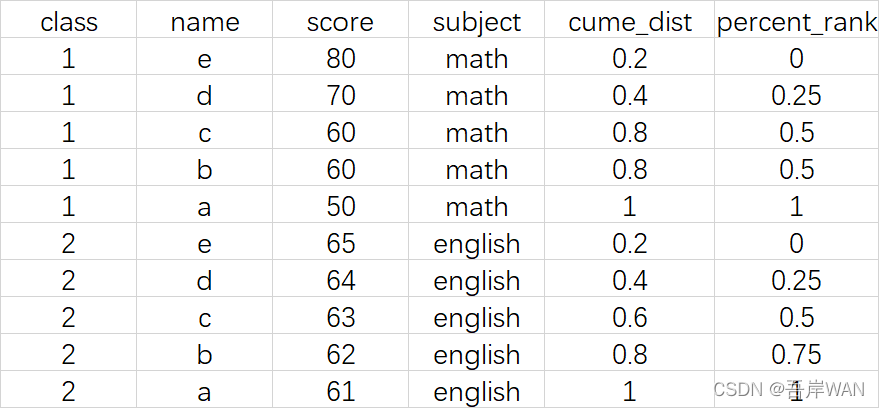
- CUME_DIST() 小于等于当前值的行数/分组内总行数;如果是降序排列,则统计大于等于当前值的行数/总行数。
- PERCENT_RANK() 分组内当前行的RANK值-1/分组内总行数-1。
select *,
cume_dist() over (partition by class order by score desc) as cume_dist,
percent_rank() over (partition by class order by score desc) as percent_rank
from test.demo_windows ;
参考文章:
https://zhuanlan.zhihu.com/p/92654574
https://blog.youkuaiyun.com/dingchangxiu11/article/details/83145151


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









