







 本文详细介绍了HBase中的数据备份方法,包括使用HBase提供的类进行全量及增量备份,以及利用snapshot快照进行高效数据迁移的步骤。通过实例展示了如何创建、恢复、删除和迁移快照。
本文详细介绍了HBase中的数据备份方法,包括使用HBase提供的类进行全量及增量备份,以及利用snapshot快照进行高效数据迁移的步骤。通过实例展示了如何创建、恢复、删除和迁移快照。
HBase的数据备份
1.1 基于HBase提供的类对表进行备份
-
使用HBase提供的类把HBase中某张表的数据导出到HDFS,之后再导出到测试hbase表中。
-
(1) 从hbase表导出到HDFS
[hadoop@node01 shells]$ hbase org.apache.hadoop.hbase.mapreduce.Export myuser /hbase_data/myuser_bak -
(2) 文件导入hbase表
hbase shell中创建备份目标表
create 'myuser_bak','f1','f2' -
将HDFS上的数据导入到备份目标表中
hbase org.apache.hadoop.hbase.mapreduce.Driver import myuser_bak /hbase_data/myuser_bak/* -
补充说明
以上都是对数据进行了全量备份,后期也可以实现表的增量数据备份,增量备份跟全量备份操作差不多,只不过要在后面加上时间戳。
例如:
HBase数据导出到HDFShbase org.apache.hadoop.hbase.mapreduce.Export test /hbase_data/test_bak_increment 开始时间戳 结束时间戳
1.2 基于snapshot快照对表进行备份
-
通过snapshot快照的方式实现HBase数据的迁移和拷贝。这种方式比较常用,效率高,也是最为推荐的数据迁移方式。
-
HBase的snapshot其实就是一组metadata信息的集合(文件列表),通过这些metadata信息的集合,就能将表的数据回滚到snapshot那个时刻的数据。
- 首先我们要了解一下所谓的HBase的LSM类型的系统结构,我们知道在HBase中,数据是先写入到Memstore中,当Memstore中的数据达到一定条件,就会flush到HDFS中,形成HFile,后面就不允许原地修改或者删除了。
- 如果要更新或者删除的话,只能追加写入新文件。既然数据写入以后就不会在发生原地修改或者删除,这就是snapshot做文章的地方。做snapshot的时候,只需要给快照表对应的所有文件创建好指针(元数据集合),恢复的时候只需要根据这些指针找到对应的文件进行恢复就Ok。这是原理的最简单的描述,下图是描述快照时候的简单流程:
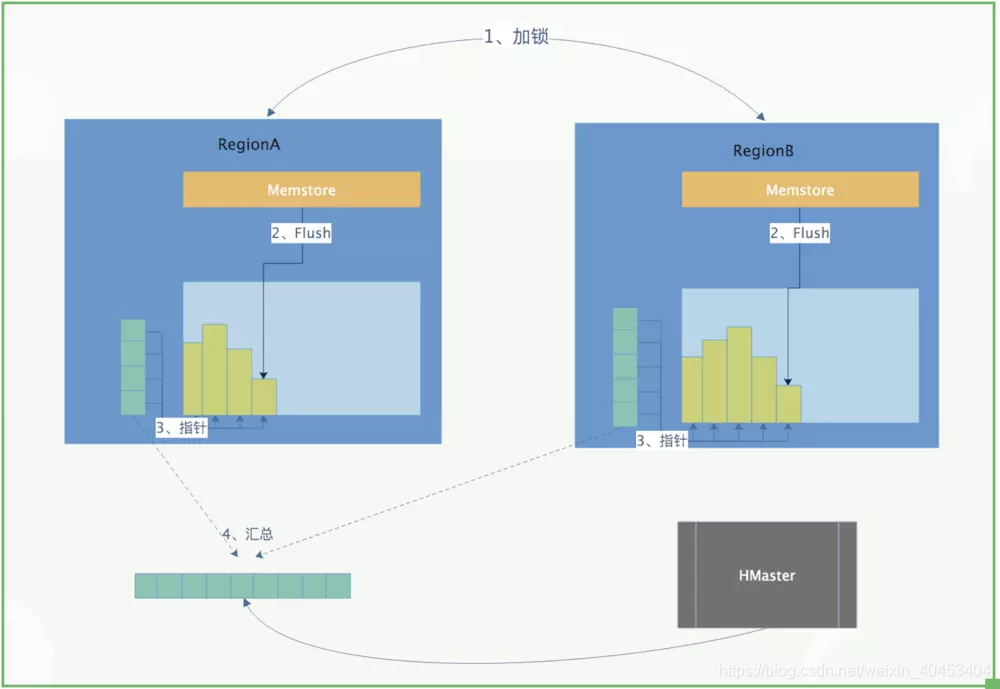
1.3 快照实战
- 1、创建表的snapshot
snapshot 'tableName', 'snapshotName'
- 2、查看snapshot
list_snapshots
查找以test开头的snapshot
list_snapshots 'test.*'
- 3、恢复snapshot
ps:这里需要对表进行disable操作,先把表置为不可用状态,然后在进行进行restore_snapshot的操作
disable 'tableName'
restore_snapshot 'snapshotName'
enable 'tableName'
- 4、删除snapshot
delete_snapshot 'snapshotName'
- 5、迁移 snapshot
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-snapshot snapshotName \
-copy-from hdfs://src-hbase-root-dir/hbase \
-copy-to hdfs://dst-hbase-root-dir/hbase \
-mappers 1 \
-bandwidth 1024
例如:
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-snapshot test \
-copy-from hdfs://node01:8020/hbase \
-copy-to hdfs://node01:8020/hbase1 \
-mappers 1 \
-bandwidth 1024
注意:这种方式用于将快照表迁移到另外一个集群的时候使用,使用MR进行数据的拷贝,速度很快,使用的时候记得设置好bandwidth参数,以免由于网络打满导致的线上业务故障。

- 6、将snapshot使用bulkload的方式导入
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles \
hdfs://dst-hbase-root-dir/hbase/archive/datapath/tablename/filename \
tablename
例如:
创建一个新表
create 'newTest','f1','f2'
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles hdfs://node1:9000/hbase1/archive/data/default/test/6325fabb429bf45c5dcbbe672225f1fb newTest
dIncrementalHFiles hdfs://node1:9000/hbase1/archive/data/default/test/6325fabb429bf45c5dcbbe672225f1fb newTest
##

















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









