









 本文是Python爬虫的基础教程,介绍了HTML网页结构,使用开发者工具查看网页源码,并通过Python读取网页内容。文章强调了编码问题在爬虫中的重要性,并预告将使用正则表达式和BeautifulSoup进行内容匹配。
本文是Python爬虫的基础教程,介绍了HTML网页结构,使用开发者工具查看网页源码,并通过Python读取网页内容。文章强调了编码问题在爬虫中的重要性,并预告将使用正则表达式和BeautifulSoup进行内容匹配。
之前在微信公众号上面看到一个关于python制作艺术签名,感觉很有意思哈~是利用python抓取了一个签名网站(具体的代码我发布在github上面啦,有兴趣的盆友可以去下载玩一玩)
一起再系统学习一下python网页爬虫,欢迎各位大佬交流~
- 一、了解网页:
在学习爬虫之前,首先要搞懂网页,而支撑起这些光鲜亮丽的网页就是一些代码,这些代码就是HTML,HTML是一种浏览器(谷歌,火狐,百度)看得懂的语言,所以HTML必定存在某些规律,搞清楚这些规律,就可以抓取我们想要的内容啦。其实构建网页的组件除了HTML之外还有CSS和Javascript。(后续会介绍,先学简单的)
- 二、网页的基本组成部分
首先我们可以使用开发者工具来搜索标记代码,在Chrome中选择“更多工具”->"开发者工具",就可以看到HTML的源码了。打开就是这样子,(我自己习惯用谷歌浏览器,这是blog的source code)
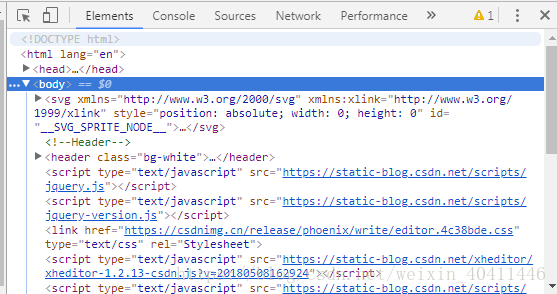

在 HTML 中, 基本上所有的实体内容, 都会有个 tag 来框住它. 而这个被 tag 住的内容, 就可以被展示成不同的形式, 或有不同的功能. 主体的 tag 分成两部分, head 和 body. 在 head 中, 存放这一些网页的网页的元信息, 比如说 title, 这些信息是不会被显示到你看到的网页中的. 这些信息大多数时候是给浏览器看, 或者是给搜索引擎的爬虫看.
(这里我用了莫烦python的一个例子)
而body 这部分才是你看到的网页信息. 网页中的 header, 视频, 图片和文字等都存放在这里. 这里的 <h1></h1> tag 就是主标题, 我们看到呈现出来的效果就是大一号的文字. <p></p> 里面的文字就是一个段落. <a></a>里面都是一些链接. 所以很多情况, 东西都是放在这些 tag 中的.
爬虫想要做的就是根据这些 tag 来找到合适的信息.
- 三、用Python登录网页
用 Python 来爬取这个网页的一些基本信息. 首先要做的, 是使用 Python 来登录这个网页, 并打印出这个网页 HTML 的 source code. 注意, 因为网页中存在中文, 为了正常显示中文, read() 完以后, 我们要对读出来的文字进行转换, decode()成可以正常显示中文的形式.!!!编码问题
这是我在python2.7上写的代码,python3.6同那个样适用。
import urllib2
import urllib
#if has Chinese ,apply decode()
html = urllib2.urlopen(
"https://morvanzhou.github.io/static/scraping/basic-structure.html"
).read().decode('utf-8')
print html输出结果如下:
<!DOCTYPE html>
<html lang="cn">
<head>
<meta charset="UTF-8">
<title>Scraping tutorial 1 | 莫烦Python</title>
<link rel="icon" href="https://morvanzhou.github.io/static/img/description/tab_icon.png">
</head>
<body>
<h1>爬虫测试1</h1>
<p>
这是一个在 <a href="https://morvanzhou.github.io/">莫烦Python</a>
<a href="https://morvanzhou.github.io/tutorials/data-manipulation/scraping/">爬虫教程</a> 中的简单测试.
</p>
</body>
</html>
哈哈,我们现在已经成功读取了网页,接下来我们想要提取信息们就要合理适用这些tag了。
- 四、匹配网页的内容
这里我们使用 Python 的正则表达式 RegEx 进行匹配文字, 筛选信息的工作. 对于初级的网页匹配, 我们使用正则完全就可以了, 高级一点或者比较繁琐的匹配, 我还是推荐使用 BeautifulSoup. 不急不急, 我知道你现在可能看不下去了,太长了, 马上就会学 beautiful soup 了. 但是现在我们还是使用正则来做几个简单的例子, 让你熟悉一下套路.
如果我们想用代码找到这个网页的 title, 我们就能这样写. 选好要使用的 tag 名称 <title>. 使用正则匹配.
import urllib2
import re
#if has Chinese ,apply decode()
html = urllib2.urlopen(
"https://morvanzhou.github.io/static/scraping/basic-structure.html"
).read().decode('utf-8')
res = re.findall(r"<title>(.+?)</title>",html)
#print html
print ("\nPage Title is :",res[0])我这里的输出出现了编码问题,希望有大神能够讲解一发,先看一下我的输出
('\nPage Title is :', 'Scraping tutorial 1 | \xe8\x8e\xab\xe7\x83\xa6Python')如果想要找到中间的那个段落 <p>, 我们使用下面方法, 因为这个段落在 HTML 中还夹杂着 tab, new line, 所以我们给一个 flags=re.DOTALL 来对这些 tab, new line 不敏感.(就在上一个代码的html后面“,flag=re.DOTALL”即可,我就不写了)
后面第二节就学BeautifulSoap.

















 4096
4096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









