







目录
2.2.2 AllocVirtualMemory--在当前进程虚拟地址空间申请内存块
1. 内存加载DLL概述
1.1 原理和步骤
基本原理:
在内存中直接加载DLL的本质就是解析PE格式并将DLL内容按照该格式要求存放到进程的虚拟地址空间的过程。
我们要做的就是模拟Windows的PE加载器,自己实现LoadLibrary函数的功能。
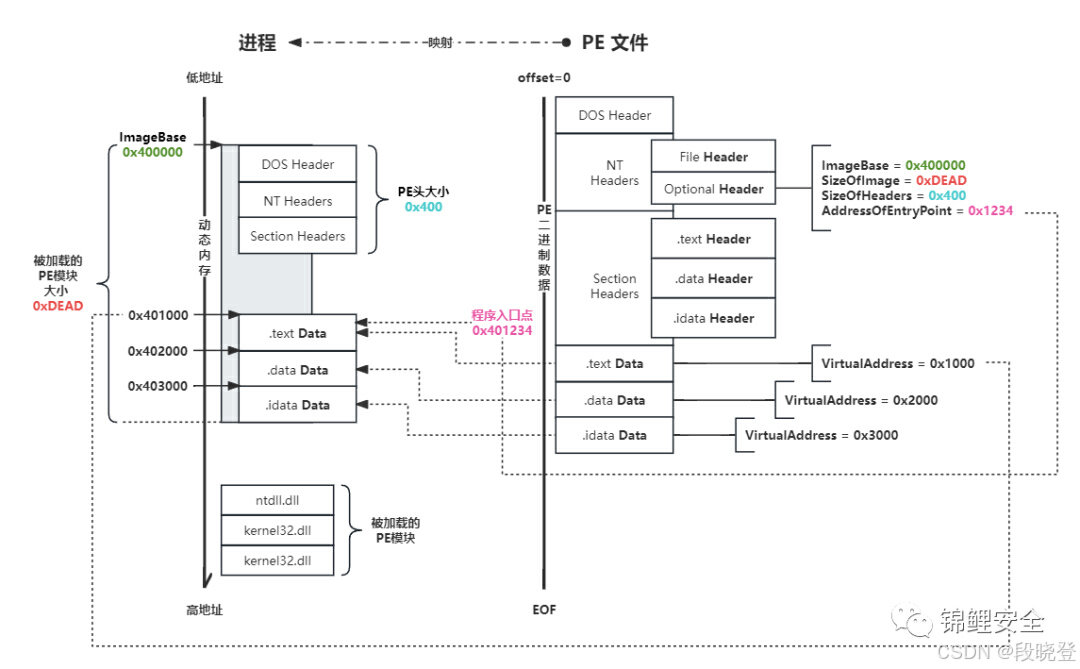
上图所示为操作系统将PE文件加载到内存中执行的过程:
- 左侧为进程执行时 PE 被加载到内存中的结构
- 右侧是 PE 文件的静态文件结构,即:磁盘存储时的结构
具体步骤:
第一步:在DLL文件中,根据PE结构获取其内存加载映像的大小:SizeOflmage,并在进程空间中给DLL申请合适大小的内存块
第二步:根据DLL中的PE结构获取其映像对齐大小SectionAlignment,然后把DLL文件数据按照SectionAlignment复制到上述申请的可读、可写、可执行的内存中
第三步:根据PE结构的重定位表,重新对重定位表进行修正。
第四步:根据PE结构的导入表,加载所需的DLL,并获取导入函数的地址并写入导入表中。
第五步:修改DLL的加载基址ImageBase。
第六步:根据PE结构获取DLL的入口地址,然后构造并调用DIMain函数,实现DLL加载。
1.2 基本概念
VA:Virtual Address,虚拟地址,代表着PE文件映射进内存之后的地址。
RVA:Reverse Virtual Address,相对虚拟地址,对于PE文件映射进内存之后相对基地址偏移。
FOA:File Offset Address,文件中的偏移(文件映射进内存后内存对齐并不一定与文件中一致,因此FOA不一定等于RVA)。
2. 在进程空间中给DLL申请合适大小的内存块
2.1 原理说明
直接将一个PE文件的内容读到内存中是无法运行的,必须经过拉伸,然后再做其它扩展处理才可以运行;
- 文件中的状态为文件映像;
- 内存中拉伸后的状态为内存映像;
PE文件被加载到虚拟地址空间时是连续的,可选PE头中的SizeOfImage参数指定了加载到内存中需要占用虚拟地址空间的大小。需要根据SizeOfImage的大小来申请空间。
2.2 代码示例
2.2.1 IsValidDLL--判断是否标准DLL文件

第一:检查PE文件的DOS header;
- 校验DOS头的e_magic参数是不是“MZ”,来判断是不是标准的PE文件。--所有PE文件的DOS头的e_magic都是一个常值:0x4D5A,即:字符串“MZ”。
第二:检查PE文件的NT header:
- 校验NT头的Signature参数是不是“PE00”,来判断是不是标准的PE文件。--所有PE文件的NT头的Signature都是一个常值:0x00004550,即:字符串“PE00”。
- 检查NT头的标准PE头FileHeader的Characteristics的字段属性是否含有IMAGE_FILE_DLL
- 检查NT头的可选PE头OptionalHeader的Magic是32位或64位。
- 0x010B表明这是一个32位文件,即:IMAGE_NT_OPTIONAL_HDR32_MAGIC
- 0x020B表明这是一个64位文件,即:IMAGE_NT_OPTIONAL_HDR64_MAGIC
2.2.2 AllocVirtualMemory--在当前进程虚拟地址空间申请内存块
PE文件被加载到虚拟地址空间时是连续的,可选PE头中的SizeOfImage参数指定了加载到内存中需要占用虚拟地址空间的大小。需要根据SizeOfImage的大小来申请空间。
根据SizeOflmage在当前进程虚拟地址空间中申请可读、可写、可执行的内存,那么这块内存的首地址就是DLL的加载基址。

3. 将DLL数据映射至申请好的内存
3.1 原理说明
3.1.1 区块对齐
根据PE文件结构可知,PE文件有两个对齐字段:
- FileAlignment:定义了磁盘区块的对齐值
- 在文件中,每一个区块从对齐值的倍数的偏移位置开始存放,但是区块的实际大小不一定刚好是这么多,所以在多余的地方一般以00h 来填充,这就是区块间的间隙。
- 例如:在PE文件中,一个典型的对齐值是200h 。这样,每个区块都将从200h 的倍数的文件偏移位置开始。假设第一个区块在400h 处,长度为90h,那么从文件400h 到490h 为这一区块的内容,而由于文件的对齐值是200h,所以为了使这一区块的长度为FileAlignment 的整数倍,490h 到 600h 这一个区间都会被00h 填充,这段空间称为区块间隙,下一个区块的开始地址为600h 。
- SectionAlignment:定义内存区块的对齐值
- PE 文件被映射到内存中时,区块总是至少从一个页边界开始。
- 一般在X86 系列的CPU 中,页是按4KB(1000h)来排列的;在IA-64 上,是按8KB(2000h)来排列的。所以在X86 系统中,PE文件区块的内存对齐值一般等于 1000h,每个区块按1000h 的倍数在内存中存放。
一般FileAlignment会比SectionAlignment要小,这样文件存储在磁盘上时会变小,以此节省磁盘空间。
3.1.2 文件偏移与RVA
在3.1.1中我们说过,PE文件为减少体积,磁盘对齐值不是一个内存页1000h,而是 200h。当这类PE文件被映射到内存后,同一数据相对于文件头的偏移量在内存中和磁盘上是不同的,这样就存在着文件偏移地址与内存虚拟地址的转换问题。--这就是为什么将DLL读入内存以后需要进行section数据的内存地址转换。
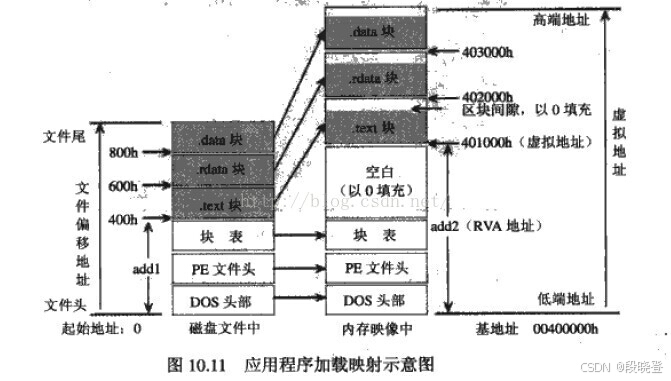
Windows 装载器在装载DOS头、PE文件头和节表部分时是不进行任何特殊处理的,而各区块section的数据映射到内存后,位置发生了改变。
转换需要前面提到的一个公式:设ΔK为相对虚拟地址RVA与文件偏移地址FileOffset的差值
VA = ImageBase + RVA
File Offset = RVA - ΔK
File Offset = VA - ImageBase - ΔK3.2 代码示例

4. 修改DLL重定位表信息
4.1 原理说明--基址重定位原理
4.1.1 基址说明
每个PE文件都有一个首选基地址:ImageBase,这个值是编译链接时链接器给设置的,它表示该模块被映射到进程地址空间时最佳的内存地址。
- 对于EXE,链接器会将它的首选基地址一般设为0x00400000
- 对于DLL,链接器会将它的首选基地址一般设为0x10000000
VS中设置如下:
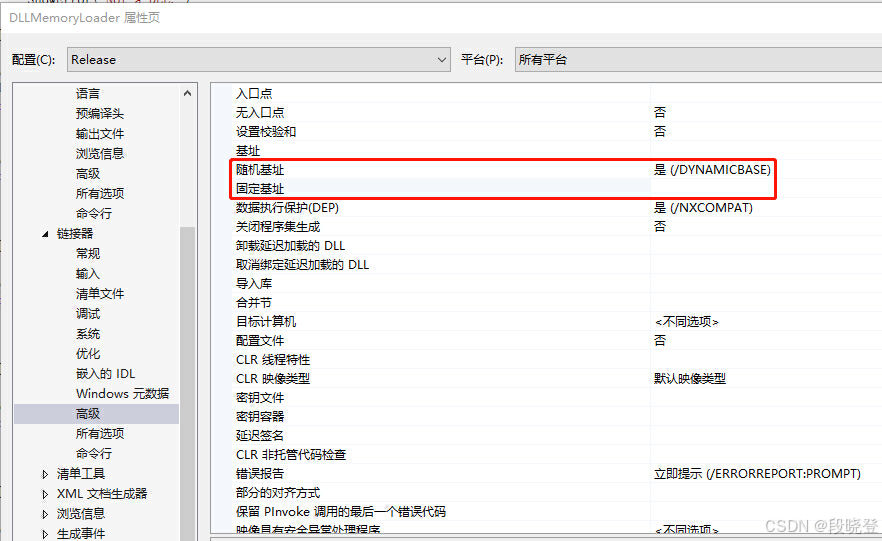
当它们被加载时,Windows加载器会读取首选基地址的值,并尝试把它们加载到相应位置。
对于可执行文件和DLL中的代码,它们运行时所引用的的数据的地址,在链接时就已经确定,但是前提是EXE或DLL被加载到它们的首选基地址处才是有效的。
例如:对于如下汇编代码:
MOV [0x00414540] 5它的意思是将5赋值给0x00414540处的内存地址,此地址已经是固定的,只有当EXE或DLL被加载到0x400000处时,0x00414540才是正确的。
然而并不是所有模块都会被载入到首选基地址处,一旦模块没有被加载到首选基地址处,在该模块中对于地址的引用都是错误的,这时候基址重定位就是必须的。
4.1.2 基址重定位
基址重定位就是当某模块未被加载到首选基地址时,Windows加载器会计算模块实际载入的地址跟首选基地址的差值,然后将这个差值加到原先机器指令所引用的地址,得到的就是模块中各机器指令所引用的数据在本进程地址空间的正确地址,最后Windows加载器会修正模块中对每个内存地址的引用。
4.1.3 重定位表
根据上述内容可以得知,重定位需要三个因素:
- 需要修正的地址
- 模块首选基地址
- 模块实际载入地址
其中,模块首选基地址在可选PE头(IMAGE_OPTIONAL_HEADER)的ImageBase字段定义;模块的实际载入地址在没有被Windows载入器加载时根本无从得知。所以在PE文件的重定位表(Base Relocation Table)中保存的就是文件中所有需要进行重定位修正的代码的地址。
重定位表是OptionalHeader中DataDirectory数组的第5项,由一系列以下结构组成:

其中:
- VirtualAddress 是 Base Relocation Table 的位置,它是一个 RVA 值,即:相对虚拟地址;
- SizeOfBlock 是 Base Relocation Table 的大小;
- TypeOffset 是一个数组,数组每项大小为两个字节(16位),它由高4位和低12位组成
- 高4位代表重定位类型:只有高四位为3时才进行重定位,即:格式为0x3XXX
- 低12位是重定位地址,即:相对于VirtualAddress的偏移量。它与 VirtualAddress 相加就是指向PE 映像中需要修改的那个代码的地址。
重定位表是按照一个物理页(4kb)进行存储的,就是说每一个4kb内存对应一个重定位表,一个重定位表只管自己当前物理页(4kb)的重定位。
每一个重定位表中包含(pReloc->SizeOfBlock - sizeof(IMAGE_BASE_RELOCATION)) / sizeof(WORD)个元素,每个元素2个字节(16位)。解释如下:
- SizeOfBlock是总的重定位块长度,减去sizeof(IMAGE_BASE_RELOCATION),得到真正需要重定位的内存长度;
- 然后除以sizeof(WORD),即:除以2,最终得到需要修正的重定位项的数量
- 除以2是因为重定位表的记录偏移的大小是2个字节,也就是16位
4.1.4 重定位过程
重定位过程分两层循环:
- 一个接一个的重定位表,最后一个重定位表的VirtualAddress与SizeOfBlock都为0
- 每个重定位表中的各个重定位项,即:2个字节的重定位项
具体重定位过程可以参看代码。
4.2 代码示例

5. 填写PE导入表
5.1 原理说明--PE文件导入表
5.1.1 导入表说明
导入表是为实现代码重用而设置的。通过分析导入表中的数据,可以获得PE文件调用了多少外部函数,以及这些外部函数都存在于哪些动态链接库里等信息。Windows加载器在运行PE时会将导入表中声明的动态链接库一并加载到进程的地址空间,并修正指令代码中调用的函数地址。
5.1.2 导入表的双桥结构
导入表大小为20字节,PE文件每依赖一个模块,就会对应一个导入表。导入表结束位置是20个字节的连续为0的数据为结束位置,也就是导入表最后一项都为0的时候,说明导入表结束了.
导入表是OptionalHeader中DataDirectory数组的第1项,由一系列以下结构组成:
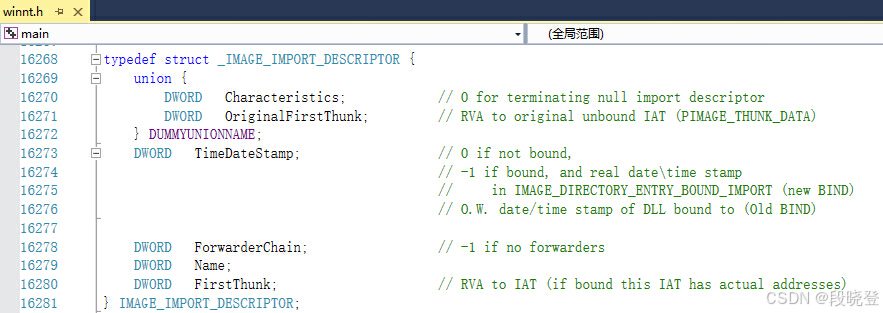
其中有三个重要成员:
- Name:描述库名(例如KERNEL32.DLL)的偏移量,它是一个RVA值,指向一个以\0结尾ASCII码字符串。
- OriginalFirstThunk:指向INT表,Improt Name Table,导入名称表;指向要从外部库导入的函数名的引用列表--桥1
- FirstThunk:指向IAT表,Improt Address Table,导入地址表;指向要从外部库导入的函数的地址列表--桥2
PE加载前:
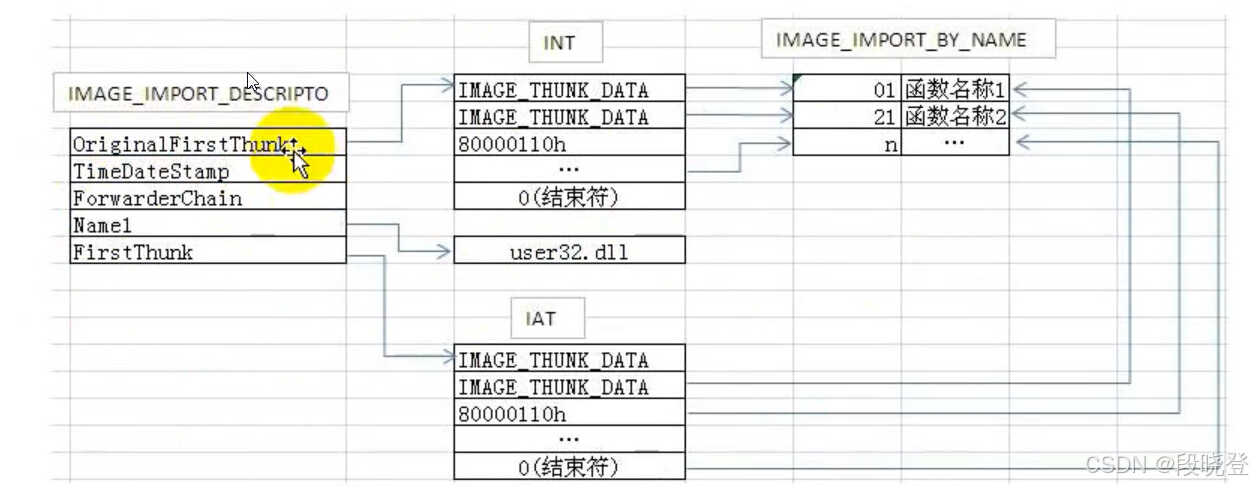
- 可以看到,PE加载前,IAT和INT是完全相同的,都指向导入函数的名称和序号信息
PE加载后:
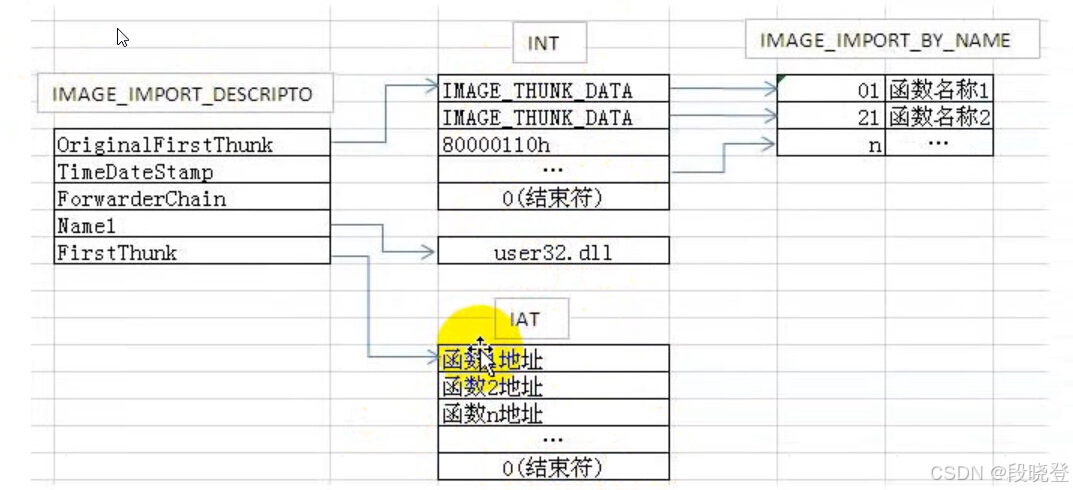
- PE加载后,系统会先根据结构体变量Name加载对应的dll,读取dll的导出表,对应原程序的INT表,获取指定函数的地址,贴在对应的IAT表上。即:GetProcAddress函数的功能
- 即:PE加载后,IAT表指向实际的导入函数地址
5.1.3 INT和IAT表结构
INT和IAT表中数据类型如下所示:
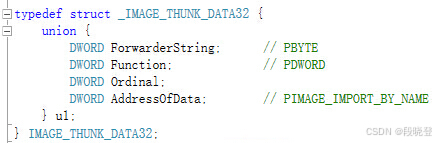
字段含义如下:
- ForwarderString:转发用,暂时不用考虑,
- Function:函数地址
- Ordinal:如果是按序号导入则有用
- AddressOfData:如果是按名称导入则有用
那到底应该是名字还是序号导入呢?可以通过Ordinal判断:
- 高位为1,则表示按名称导入,去掉高位就是函数序号
- 高位为0,则表示按序号导入,那么AddressOfData就是一个RVA偏移,指向IMAGE_IMPORT_BY_NAME结构,如下所示:

5.2 代码示例


6. 修改DLL的加载基址
6.1 原理说明
详见本文4.1.1节:基址说明。内存基址由可选PE头中的ImageBase字段定义。
6.2 代码示例
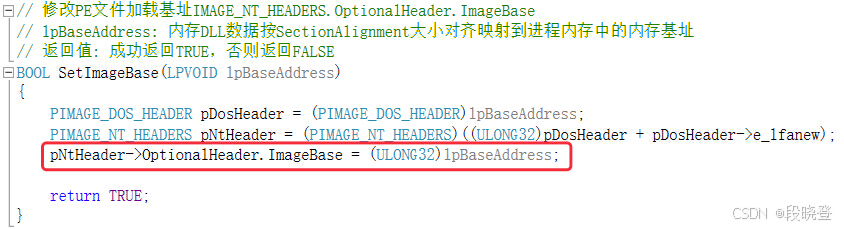
说明:
- 修改DLL的加载基址,本质就是将ImageBase字段指向申请的进程内存空间起始地址。
7. 调用DLL入口函数:DLLMain
7.1 原理说明
最后一步要做的就是调用DLL入口点DllMain(由可选PE头中的AddressOfEntryPoint字段定义),从而通知库有关附加到进程的信息。
7.2 代码示例
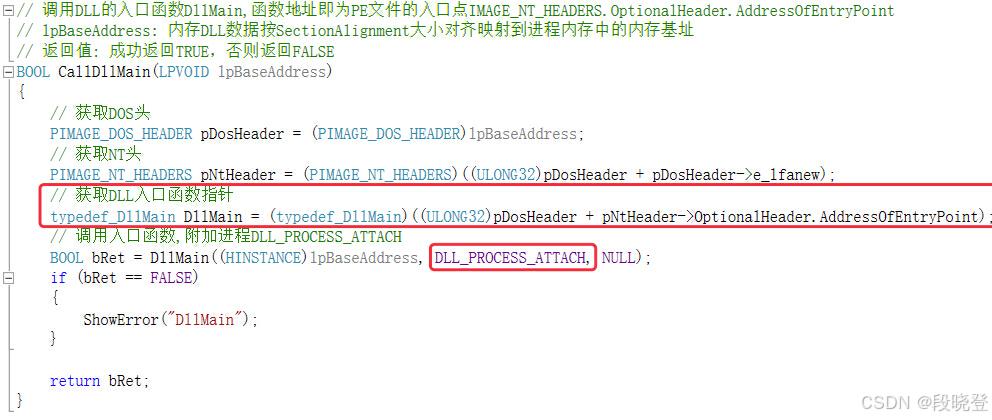
说明:
- 调用DllMain函数时,传入参数为DLL_PROCESS_ATTACH,表示是进程附加事件。
8. 导出表
8.1 原理说明
8.1.1 导出表说明
导出表中记录了DLL导出的函数信息,其中包括:函数序号、函数名称、函数地址等。
8.1.2 导出表结构
导出表是OptionalHeader中DataDirectory数组的第0项,由一系列以下结构组成:

函数导出时,可以按照名称导出,也可以按照序号导出。
导出函数个数:
- NumberOfFunctions:DLL导出的函数的总数
- NumberOfNames:DLL中按名称导出的函数个数
- NumberOfFunctions - NumberOfNames:DLL中按序号导出的函数个数
三张RVA表:
- AddressOfFunctions:保存DLL中所有导出函数的地址。
- AddressOfNames:保存DLL中所有导出函数的名称
- AddressOfNameOrdinals:保存DLL中所有导出函数的序号
8.1.3 调用导出函数
根据函数名称获取函数地址:
- 在AddressOfNames中找到对应的名字,如果它在AddressOfNames中是第二项,那么就从AddressOfNameOrdinals中取出第二项的值。
- 如果AddressOfNameOrdinals中第二项的值是2,那么表示函数入口地址保存在AddressOfFunctions这个数组中下标为2的项里,即第三项。
- 取出AddressOfFunctions中下标为2的的值,加上模块基址便是导出函数的地址。
根据函数序号获取函数地址:
- 如果函数是以序号导出的,那么查找的时候直接用序号减去Base,得到的值就是函数在AddressOfFunctions中的下标。
这里说一下为什么需要减去base。
例如某个DLL的def文件如下所示:
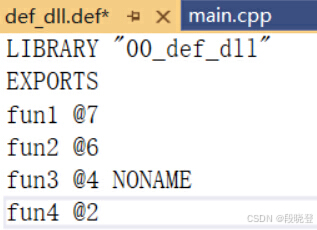
导出序号为 7 6 4 2,编译器不会从2开始放函数地址,因为会造成大量空间浪费。
如果从2开始放的地址数组是这样的:
| index | value |
| 0 | 0 |
| 1 | 0 |
| 2 | 函数地址 导出序号:2 |
| 3 | 0 |
| 4 | 函数地址 导出序号:4 |
| 5 | 0 |
| 6 | 函数地址 导出序号:6 |
| 7 | 函数地址 导出序号:7 |
如果函数的导出最小的序号减去base,则地址数组是这样的:
| index | value |
| 0 | 函数地址 :导出序号:2 |
| 1 | 0 |
| 2 | 函数地址 导出序号:4 |
| 3 | 0 |
| 4 | 函数地址 导出序号:6 |
| 5 | 函数地址 导出序号:7 |
所以函数地址在放到函数地址表里的时候,函数导出序号会减去base的值为下标存放
8.2 代码示例

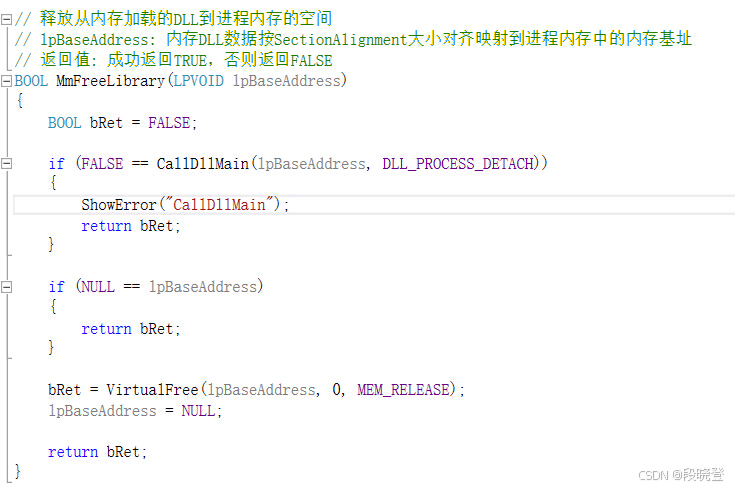
9. 释放DLL
9.1 原理说明
要释放内存加载的库,需要执行以下步骤
- 调用DLL入口点DllMain(由可选PE头中的AddressOfEntryPoint字段定义),从而通知DLL有关分离到进程的信息。
- 释放分配的内存
9.2 代码示例
10. 完整代码
代码可以用于内存加载32位和64位的dll。
github地址:https://github.com/duanxiaodeng/SomethingAboutWindows.git


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









