




 本文探讨了逻辑回归(LR)与多层感知器(MLP)的区别。LR是线性模型,参数数量与特征个数直接相关,而MLP作为非线性模型,能拟合更复杂的函数,参数个数通常较多。当MLP只有一层且只有一个神经元时,它就等同于LR。
本文探讨了逻辑回归(LR)与多层感知器(MLP)的区别。LR是线性模型,参数数量与特征个数直接相关,而MLP作为非线性模型,能拟合更复杂的函数,参数个数通常较多。当MLP只有一层且只有一个神经元时,它就等同于LR。
1、LR是MLP的一种特殊情况,即:MLP只有一层,且只有一个神经元,则是LP。
2、LR是线性模型,MLP是非线性模型。MLP拟合的更加复杂。
3、LR逻辑回归的参数数量和特征的个数是一样的,或者是特征个数加一; 而MLP的参数个数,一般情况下比较多,单层的MLP是参数个数是m*n的。
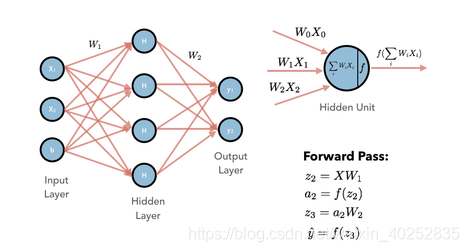

1、LR是MLP的一种特殊情况,即:MLP只有一层,且只有一个神经元,则是LP。
2、LR是线性模型,MLP是非线性模型。MLP拟合的更加复杂。
3、LR逻辑回归的参数数量和特征的个数是一样的,或者是特征个数加一; 而MLP的参数个数,一般情况下比较多,单层的MLP是参数个数是m*n的。
 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























