







DeepCTR源码解读(二)
2.1 deepctr概览
基于tensorflow的deepctr包含的各个模块如下图所示:
其中,feature_column.py和inputs.py用于构造特征列和处理输入;models模块则包含了各个CTR算法,比如FM、DFM、DIN等,我们可以直接调用这些方法用在具体任务上;layers继承自tf.keras.layers.Layer,因此它与keras Layers有相同的属性和方法,可以用layers模块构建自己的模型。
接下来我们了解下这几个关键模块的作用。
2.2 特征列模块
feature_columns.py
该模块包含3个类和4个方法,如下图所示:

这个模块是用于构造特征列的,输入神经网络的特征大致可以分为三种:类别特征、数值特征和序列特征,因此feature_column.py中的类SparseFeat、DenseFeat、VarLenSparseFeat就是用来处理这三种特征的。我们只需要将原始特征转化为这三种特征列,之后就可以得到通用的特征输入,从而可调用models中的任意模型开始训练。
a. SparseFeat
SparseFeat用于处理类别特征,如性别、国籍等类别特征,将类别特征转为固定维度的稠密特征。
- 函数解析
SparseFeat(name, vocabulary_size, embedding_dim, use_hash, dtype, embeddings_initializer, embedding_name, group_name, trainable)
class SparseFeat(namedtuple('SparseFeat',
['name', 'vocabulary_size', 'embedding_dim', 'use_hash', 'dtype', 'embeddings_initializer',
'embedding_name',
'group_name', 'trainable'])):
'''
处理类别特征,将其转为固定维度的稠密特征
参数:
name:生成的特征列的名字
vocabulary_size:不同特征值的个数或当use_hash=True时的哈希空间
embedding_dim:嵌入向量的维度
use_hash:是否使用哈希编码,默认False
dtype:默认int32
embeddings_initializer:嵌入矩阵初始化方式,默认随机初始化
embedding_name:默认None,其名字与name保持一致
group_name:特征列所属的组
traninable:嵌入矩阵是否可训练,默认True
'''
__slots__ = ()
def __new__(cls, name, vocabulary_size, embedding_dim=4, use_hash=False, dtype="int32", embeddings_initializer=None,
embedding_name=None,
group_name=DEFAULT_GROUP_NAME, trainable=True):
if embedding_dim == "auto":
embedding_dim = 6 * int(pow(vocabulary_size, 0.25))
if embeddings_initializer is None:
embeddings_initializer = RandomNormal(mean=0.0, stddev=0.0001, seed=2020)
if embedding_name is None:
embedding_name = name
return super(SparseFeat, cls).__new__(cls, name, vocabulary_size, embedding_dim, use_hash, dtype,
embeddings_initializer,
embedding_name, group_name, trainable)
def __hash__(self):
return self.name.__hash__()
- 函数示例
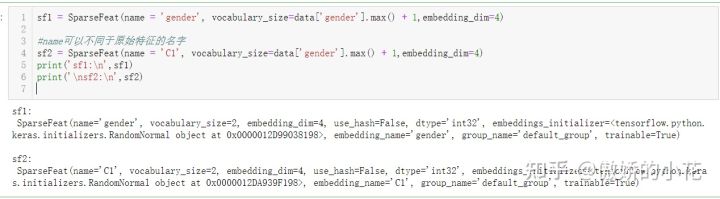
我们对类别特征——gender(female、male),构造一个SparseFeat实例:
b.DenseFeat
将稠密特征转为向量的形式,并使用transform_fn 函数对其做归一化操作或者其它的线性或非线性变换。
- 函数解析
DenseFeat(name, dimension, dtype, transform_fn)
class DenseFeat(namedtuple('DenseFeat', ['name', 'dimension', 'dtype', 'transform_fn'])):
"""
将稠密特征转为向量的形式,并使用transform_fn 函数对其做归一化操作或者其它的线性或非线性变换
Args:
name: 特征列名字
dimension: 嵌入特征维度,默认是1
dtype: 特征类型,default="float32",
transform_fn: 转换函数,可以是归一化函数,也可以是其它的线性变换函数,以张量作为输入,经函数处理后,返回张量
比如: lambda x: (x - 3.0) / 4.2)
"""
__slots__ = ()
def __new__(cls, name, dimension=1, dtype="float32", transform_fn=None):
return super(DenseFeat, cls).__new__(cls, name, dimension, dtype, transform_fn)
def __hash__(self):
return self.name.__hash__()
- 函数示例
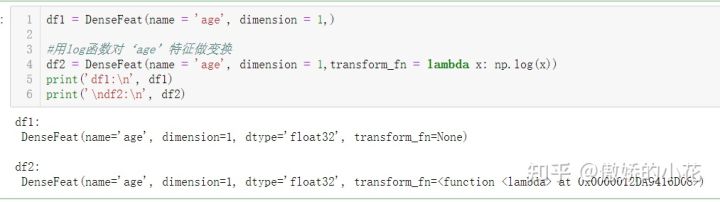
我们为数值特征——age构造一个DenseFeat对象:
c.VarLenSparseFeat
处理类似文本序列的可变长度类型特征。
- 函数解析
VarLenSparseFeat ( sparsefeat, maxlen, combiner, length_name, weight_name, weight_norm )
class VarLenSparseFeat(namedtuple('VarLenSparseFeat',
['sparsefeat', 'maxlen', 'combiner', 'length_name', 'weight_name', 'weight_norm'])):
'''
处理可变长度的SparseFeat,比如文本序列特征,对文本分词后,每个样本的文本序列包含的词数量是不统一的。
参数:
sparsefeat:属于SparseFeat的实例
maxlen:所有样本中该特征列的长度最大值
combiner:池化方法(mean,sum,max),默认是mean
length_name:特征长度名字,如果是None的话,表示特征中的0是用来填充的
weight_name:默认None,如果不为空,那么序列特征会与weight_name的权重特征进行相乘
weight_norm:是否对权重分数做归一化,默认True
'''
__slots__ = ()
def __new__(cls, sparsefeat, maxlen, combiner="mean", length_name=None, weight_name=None, weight_norm=True):
return super(VarLenSparseFeat, cls).__new__(cls, sparsefeat, maxlen, combiner, length_name, weight_name,
weight_norm)
#因为传入的对象类型是SparseFeat,因此SparseFeat有的属性VarLenSparseFeat都有
@property
def name(self):
return self.sparsefeat.name
@property
def vocabulary_size(self):
return self.sparsefeat.vocabulary_size
@property
def embedding_dim(self):
return self.sparsefeat.embedding_dim
@property
def use_hash(self):
return self.sparsefeat.use_hash
@property
def dtype(self):
return self.sparsefeat.dtype
@property
def embeddings_initializer(self):
return self.sparsefeat.embeddings_initializer
@property
def embedding_name(self):
return self.sparsefeat.embedding_name
@property
def group_name(self):
return self.sparsefeat.group_name
@property
def trainable(self):
return self.sparsefeat.trainable
def __hash__(self):
return self.name.__hash__()
feature_columns.py还包含了四个函数:
'''
作用:获取所有特征列的名字,以列表形式返回
'''
def get_feature_names(feature_columns):
features = build_input_features(feature_columns) #为特征列构造keras tensor
return list(features.keys()) #返回特征列的names
'''
作用:为所有的特征列构造keras tensor,结果以OrderDict形式返回
'''
def build_input_features(feature_columns, prefix=''):
input_features = OrderedDict()
for fc in feature_columns:
if isinstance(fc, SparseFeat): #判断fc是否属于SparseFeat实例
input_features[fc.name] = Input(
shape=(1,), name=prefix + fc.name, dtype=fc.dtype) #Input()函数用于构造keras tensor
elif isinstance(fc, DenseFeat):
input_features[fc.name] = Input(
shape=(fc.dimension,), name=prefix + fc.name, dtype=fc.dtype)
elif isinstance(fc, VarLenSparseFeat):
input_features[fc.name] = Input(shape=(fc.maxlen,), name=prefix + fc.name,
dtype=fc.dtype)
if fc.weight_name is not None:
input_features[fc.weight_name] = Input(shape=(fc.maxlen, 1), name=prefix + fc.weight_name,
dtype="float32")
if fc.length_name is not None:
input_features[fc.length_name] = Input((1,), name=prefix + fc.length_name, dtype='int32')
else:
raise TypeError("Invalid feature column type,got", type(fc))
return input_features
'''
作用:获取linear_logit(线性变换)的结果
'''
def get_linear_logit(features, feature_columns, units=1, use_bias=False, seed=1024, prefix='linear',
l2_reg=0):
linear_feature_columns = copy(feature_columns)
#将SparseFeat和VarLenSparseFeat的embedding_dim强制置换为1
for i in range(len(linear_feature_columns)):
if isinstance(linear_feature_columns[i], SparseFeat):
linear_feature_columns[i] = linear_feature_columns[i]._replace(embedding_dim=1,
embeddings_initializer=Zeros())
if isinstance(linear_feature_columns[i], VarLenSparseFeat):
linear_feature_columns[i] = linear_feature_columns[i]._replace(
sparsefeat=linear_feature_columns[i].sparsefeat._replace(embedding_dim=1,
embeddings_initializer=Zeros()))
#获取用于线性变换的embedding list
linear_emb_list = [input_from_feature_columns(features, linear_feature_columns, l2_reg, seed,
prefix=prefix + str(i))[0] for i in range(units)]
#获取DenseFeat的数值特征
_, dense_input_list = input_from_feature_columns(features, linear_feature_columns, l2_reg, seed, prefix=prefix)
linear_logit_list = []
for i in range(units):
if len(linear_emb_list[i]) > 0 and len(dense_input_list) > 0: #既有稀疏类别特征也有稠密特征的情况
sparse_input = concat_func(linear_emb_list[i]) #将所有稀疏特征列的嵌入向量进行拼接
dense_input = concat_func(dense_input_list) #将所有稠密特征列的数值特征进行拼接
linear_logit = Linear(l2_reg, mode=2, use_bias=use_bias, seed=seed)([sparse_input, dense_input]) #将sparse_input和dense_input拼接后进行线性变换
elif len(linear_emb_list[i]) > 0: #仅有稀疏类别特征的情况
sparse_input = concat_func(linear_emb_list[i])
linear_logit = Linear(l2_reg, mode=0, use_bias=use_bias, seed=seed)(sparse_input)
elif len(dense_input_list) > 0: #仅有稠密数值特征的情况
dense_input = concat_func(dense_input_list)
linear_logit = Linear(l2_reg, mode=1, use_bias=use_bias, seed=seed)(dense_input)
else:
# raise NotImplementedError
return add_func([])
linear_logit_list.append(linear_logit)
return concat_func(linear_logit_list) #将所有logit结果拼接后返回
'''
为所有特征列创建嵌入矩阵,并分别返回包含SparseFeat和VarLenSparseFeat的嵌入矩阵的字典,以及包含DenseFeat的数值特征的字典
具体实现是通过调用inputs中的create_embedding_matrix、embedding_lookup、varlen_embedding_lookup等函数完成
'''
def input_from_feature_columns(features, feature_columns, l2_reg, seed, prefix='', seq_mask_zero=True,
support_dense=True, support_group=False):
sparse_feature_columns = list(
filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if feature_columns else []
varlen_sparse_feature_columns = list(
filter(lambda x: isinstance(x, VarLenSparseFeat), feature_columns)) if feature_columns else []
embedding_matrix_dict = create_embedding_matrix(feature_columns, l2_reg, seed, prefix=prefix,
seq_mask_zero=seq_mask_zero)
group_sparse_embedding_dict = embedding_lookup(embedding_matrix_dict, features, sparse_feature_columns)
dense_value_list = get_dense_input(features, feature_columns)
if not support_dense and len(dense_value_list) > 0:
raise ValueError("DenseFeat is not supported in dnn_feature_columns")
sequence_embed_dict = varlen_embedding_lookup(embedding_matrix_dict, features, varlen_sparse_feature_columns)
group_varlen_sparse_embedding_dict = get_varlen_pooling_list(sequence_embed_dict, features,
varlen_sparse_feature_columns)
group_embedding_dict = mergeDict(group_sparse_embedding_dict, group_varlen_sparse_embedding_dict)
if not support_group:
group_embedding_dict = list(chain.from_iterable(group_embedding_dict.values()))
return group_embedding_dict, dense_value_list
2.3 输入模块
inputs.py
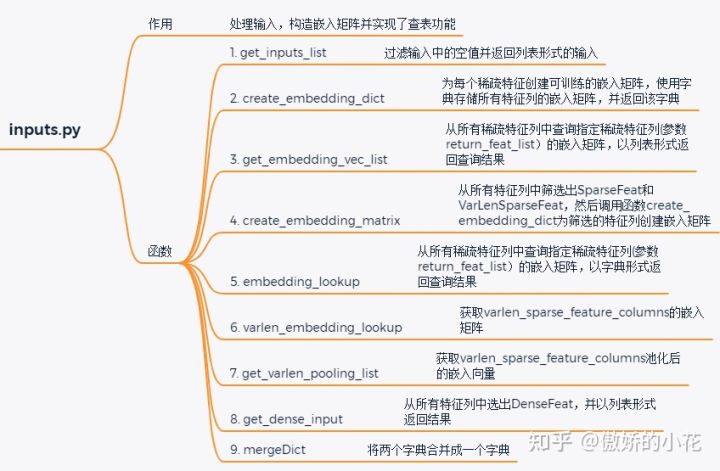
SparseFeat和VarLenSparseFeat对象需要创建嵌入矩阵,嵌入矩阵的构造和查表等操作都是通过inputs.py模块实现的,该模块包含9个方法,每个方法的具体功能如下图所示:
下面分别介绍每个函数的作用:
1. get_inputs_list
- filter函数过滤输入中的空值
- map函数是取每个元素x的value
- chain构建了一个迭代器,循环处理输入中的每条样本
- 最后返回一个list
'''
作用:过滤输入中的空值并返回列表形式的输入
'''
def get_inputs_list(inputs):
return list(chain(*list(map(lambda x: x.values(), filter(lambda x: x is not None, inputs)))))
2. create_embedding_dict
'''
作用:为每个稀疏特征创建可训练的嵌入矩阵,使用字典存储所有特征列的嵌入矩阵,并返回该字典
'''
def create_embedding_dict(sparse_feature_columns, varlen_sparse_feature_columns, seed, l2_reg,
prefix='sparse_', seq_mask_zero=True):
sparse_embedding = {}
#处理稀疏特征
for feat in sparse_feature_columns:
# 为每个稀疏特征初始化一个vocabulary_size x embedding_dim 大小的嵌入矩阵
emb = Embedding(feat.vocabulary_size, feat.embedding_dim,
embeddings_initializer=feat.embeddings_initializer,
embeddings_regularizer=l2(l2_reg),
name=prefix + '_emb_' + feat.embedding_name)
# 令该嵌入矩阵可训练
emb.trainable = feat.trainable
#添加到字典中
sparse_embedding[feat.embedding_name] = emb
#处理可变长度稀疏特征,处理方法同上
if varlen_sparse_feature_columns and len(varlen_sparse_feature_columns) > 0:
for feat in varlen_sparse_feature_columns:
# if feat.name not in sparse_embedding:
emb = Embedding(feat.vocabulary_size, feat.embedding_dim,
embeddings_initializer=feat.embeddings_initializer,
embeddings_regularizer=l2(
l2_reg),
name=prefix + '_seq_emb_' + feat.name,
mask_zero=seq_mask_zero)
emb.trainable = feat.trainable
sparse_embedding[feat.embedding_name] = emb
return sparse_embedding
3.get_embedding_vec_list
'''
作用:从所有稀疏特征列中查询指定稀疏特征列(参数return_feat_list)的嵌入矩阵,以列表形式返回查询结果
关键参数:
embedding_dict:type:dict;存储着所有特征列的嵌入矩阵的字典
input_dict:type:dict;存储着特征列和对应的嵌入矩阵索引的字典,在没有使用hash查询时使用
sparse_feature_columns:type:list;所有稀疏特征列
return_feat_list:需要查询的特征列,默认为空,为空则返回所有稀疏特征列的嵌入矩阵,不为空则仅返回该元组中的特征列的嵌入矩阵
'''
def get_embedding_vec_list(embedding_dict, input_dict, sparse_feature_columns, return_feat_list=(), mask_feat_list=()):
embedding_vec_list = []
for fg in sparse_feature_columns:
feat_name = fg.name
if len(return_feat_list) == 0 or feat_name in return_feat_list:
if fg.use_hash:
lookup_idx = Hash(fg.vocabulary_size, mask_zero=(feat_name in mask_feat_list))(input_dict[feat_name])
else:
lookup_idx = input_dict[feat_name]
embedding_vec_list.append(embedding_dict[feat_name](lookup_idx))
return embedding_vec_list
4.create_embedding_matrix
'''
作用:从所有特征列中筛选出SparseFeat和VarLenSparseFeat,然后调用函数create_embedding_dict为筛选的特征列创建嵌入矩阵
'''
def create_embedding_matrix(feature_columns, l2_reg, seed, prefix="", seq_mask_zero=True):
from . import feature_column as fc_lib
sparse_feature_columns = list(
filter(lambda x: isinstance(x, fc_lib.SparseFeat), feature_columns)) if feature_columns else []
varlen_sparse_feature_columns = list(
filter(lambda x: isinstance(x, fc_lib.VarLenSparseFeat), feature_columns)) if feature_columns else []
sparse_emb_dict = create_embedding_dict(sparse_feature_columns, varlen_sparse_feature_columns, seed,
l2_reg, prefix=prefix + 'sparse', seq_mask_zero=seq_mask_zero)
return sparse_emb_dict
示例如下,从结果中可以看出该函数可以所有特征列中筛选出SparseFeat元素:
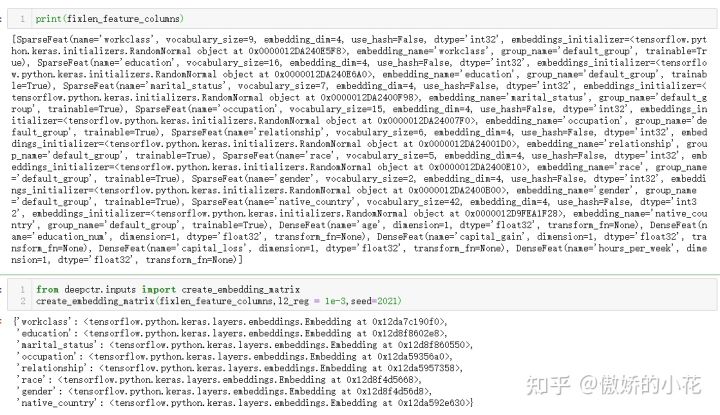
5. embedding_lookup
'''
作用:从所有稀疏特征列中查询指定稀疏特征列(参数return_feat_list)的嵌入矩阵,以字典形式返回查询结果
参数:
sparse_embedding_dict:存储稀疏特征列的嵌入矩阵的字典
sparse_input_dict:存储稀疏特征列的名字和索引的字典
sparse_feature_columns:稀疏特征列列表,元素为SparseFeat
return_feat_list:需要查询的稀疏特征列,如果元组为空,默认返回所有特征列的嵌入矩阵
mask_feat_list:用于哈希查询
to_list:是否以列表形式返回查询结果,默认是False
'''
def embedding_lookup(sparse_embedding_dict, sparse_input_dict, sparse_feature_columns, return_feat_list=(),
mask_feat_list=(), to_list=False):
group_embedding_dict = defaultdict(list) #存储结果的列表
for fc in sparse_feature_columns: # 遍历查找
feature_name = fc.name
embedding_name = fc.embedding_name
if (len(return_feat_list) == 0 or feature_name in return_feat_list):
if fc.use_hash: #获取哈希查询的索引
lookup_idx = Hash(fc.vocabulary_size, mask_zero=(feature_name in mask_feat_list))(
sparse_input_dict[feature_name])
else: #从sparse_input_dict中获取该特征列的索引
lookup_idx = sparse_input_dict[feature_name]
group_embedding_dict[fc.group_name].append(sparse_embedding_dict[embedding_name](lookup_idx))
if to_list: # 如果为真,则将结果转为列表形式返回
return list(chain.from_iterable(group_embedding_dict.values()))
return group_embedding_dict
6.varlen_embedding_lookup
'''
作用:获取varlen_sparse_feature_columns的嵌入矩阵
'''
def varlen_embedding_lookup(embedding_dict, sequence_input_dict, varlen_sparse_feature_columns):
varlen_embedding_vec_dict = {}
for fc in varlen_sparse_feature_columns:
feature_name = fc.name
embedding_name = fc.embedding_name
if fc.use_hash:
lookup_idx = Hash(fc.vocabulary_size, mask_zero=True)(sequence_input_dict[feature_name])
else:
lookup_idx = sequence_input_dict[feature_name]
varlen_embedding_vec_dict[feature_name] = embedding_dict[embedding_name](lookup_idx)
return varlen_embedding_vec_dict
7.get_varlen_pooling_list
'''
作用:获取varlen_sparse_feature_columns池化后的嵌入向量
'''
def get_varlen_pooling_list(embedding_dict, features, varlen_sparse_feature_columns, to_list=False):
pooling_vec_list = defaultdict(list)
for fc in varlen_sparse_feature_columns:
feature_name = fc.name
combiner = fc.combiner
feature_length_name = fc.length_name
if feature_length_name is not None: # length_name不为空,说明该特征列不存在用0填充的情况
if fc.weight_name is not None: # weight_name不为空,说明序列需要进行权重化操作
seq_input = WeightedSequenceLayer(weight_normalization=fc.weight_norm)(
[embedding_dict[feature_name], features[feature_length_name], features[fc.weight_name]]) #需要对查找结果做权重化操作再得到seq_input
else: # weight_name为空,说明序列不需要进行权重化操作
seq_input = embedding_dict[feature_name] #直接从嵌入矩阵里找到对应结果,赋值给seq_input
vec = SequencePoolingLayer(combiner, supports_masking=False)(
[seq_input, features[feature_length_name]]) #池化操作,因为没有填充,所以supports_masking=False,即池化时不需要mask掉填充的部分
else: #length_name为空,说明该特征列存在用0填充的情况,因此在权重化操作和池化操作时都要令supports_masking=True,即mask掉填充的部分
if fc.weight_name is not None:
seq_input = WeightedSequenceLayer(weight_normalization=fc.weight_norm, supports_masking=True)(
[embedding_dict[feature_name], features[fc.weight_name]])
else:
seq_input = embedding_dict[feature_name]
vec = SequencePoolingLayer(combiner, supports_masking=True)(
seq_input)
pooling_vec_list[fc.group_name].append(vec)
if to_list:
return chain.from_iterable(pooling_vec_list.values())
return pooling_vec_list
8.get_dense_input
'''
作用:从所有特征列中选出DenseFeat,并以列表形式返回结果
'''
def get_dense_input(features, feature_columns):
from . import feature_column as fc_lib
#筛选出DenseFeat元素
dense_feature_columns = list(
filter(lambda x: isinstance(x, fc_lib.DenseFeat), feature_columns)) if feature_columns else []
dense_input_list = []
#循环对各个DenseFeat元素执行transform_fn函数
for fc in dense_feature_columns:
if fc.transform_fn is None:
dense_input_list.append(features[fc.name])
else:
transform_result = Lambda(fc.transform_fn)(features[fc.name])
dense_input_list.append(transform_result)
return dense_input_list
9. def mergeDict
'''
作用:将a、b两个字典合并
'''
def mergeDict(a, b):
c = defaultdict(list)
for k, v in a.items():
c[k].extend(v)
for k, v in b.items():
c[k].extend(v)
return c
原文链接:
DeepCTR源码解读(二)mp.weixin.qq.com
想了解更多算法学习笔记,欢迎关注公众号:【AI干货铺】

















 3442
3442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









