







 本文详细介绍了如何在单机环境中部署Hadoop的伪分布式版本,包括环境配置、JDK设置、SSH免密钥、Hadoop安装包配置、启动服务等步骤。在部署过程中,强调了Java环境、主机名同步、SSH公钥私钥的生成以及Hadoop配置文件的修改,以确保无密码远程登录和顺利启动服务。最后,展示了Hadoop的数据存储情况和如何查看存储信息。
本文详细介绍了如何在单机环境中部署Hadoop的伪分布式版本,包括环境配置、JDK设置、SSH免密钥、Hadoop安装包配置、启动服务等步骤。在部署过程中,强调了Java环境、主机名同步、SSH公钥私钥的生成以及Hadoop配置文件的修改,以确保无密码远程登录和顺利启动服务。最后,展示了Hadoop的数据存储情况和如何查看存储信息。
伪分布式也可以成为单机版,意思就是说 hadoop集群中的所有角色均在一台机器上配置。
hadoop是java编写的所以需要jvm去执行也就是需要jdk,当机器多了以后我们跑到每一台电脑上去进行配置非常麻烦,hadoop为我们准备了脚本,我们执行脚本去登录别的机器的账号,就可以完成相应的配置。脚本不会访问etc下的profile文件。所以我们要在脚本中也配置jdk的路径和jkd下bin目录的路径。至于ssh 就是远程登录时使用的传输协议。毕竟ssh有公钥和私钥,对于这种用户名和密码高度机密的安全性还是有保证的。
搭建步骤思路
一:操作系统环境
- 依赖软件ssh、jdk
- 环境的配置
· java_home
· 免密钥
- 集群时间同步
- hosts,hostname
二:hadoop部署
- /opt/hadoop
- 配置文件修改
· java_home
- 角色在哪里启动
具体搭建步骤
jdk使用的是 jdk-7u67-linux-x64.rpm
rpm -i jdk-7u67-linux-x64.rpm
cd /usr/java/jdk1.7.0_67
在profile文件中配置环境变量
vi /etc/profile 最后两行加上如下内容
export JAVA_HOME=/usr/java/jdk1.7.0_67
export PATH=$PATH:$JAVA_HOME/bin
执行脚本,并使用jps命令查看java进程
. /etc/profile
jps使用ssh 登录 localhost然后再退出,这步不做 root目录下没有 .ssh 文件,想要查看.ssh需要用 ll -a ,该文件是隐藏的
ssh localhost
exit生成ssh的公钥和私钥
ssh-keygen -t dsa -P '' -f ./.ssh/id_dsa将公钥暴露给自己(因为是伪分布式版) ,从而通过ssh远程登录的时候不需要密码
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys解压hadoop安装包,然后将hadoop的主目录、bin、sbin目录配置到 /etc/profile 中
tar -xf hadoop-2.6.5.tar.gz
export HADOOP_PREFIX=/opt/hadoop/hadoop-2.6.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin
更改 hadoop主目录下的 etc目录下的hadoop目录下的 hadoop-env.sh 、mapred-env.sh 和 yarn-env.sh中的 JAVA_HOME
为如下
export JAVA_HOME=/usr/java/jdk1.7.0_67
进入 hadoop主目录下的ect/hadoop下的 core-site.xml
在 configuration 标签中配置如下内容
<configuration>
<property>
<name>fs.defaultFS</name> # 配置NameNode位置
<value>hdfs://node001:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name> # 配置NameNode源文件存储位置
<value>/var/zzh/hadoop/local</value> # 这个目录必须为空,也可以不存在,会自动创建
</property>
</configuration>
注意 node01 是该虚拟机的主机名
[root@node001 hadoop]# cat /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=node001
[root@node001 hadoop]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.46.21 node001
192.168.46.22 node002
192.168.46.23 node003
192.168.46.24 node004
然后继续在该目录下配置 副本个数和 secondNameNode,由于我们是为伪分布式版所以副本个数为1
vi hdfs-site.xml <configuration>
<property>
<name>dfs.replication</name>
<value>1</value> # 副本个数
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node001:50090</value> # secondNameNode 地址
</property>
</configuration>
再打开 slaves 配置DateNode
vi slaves [root@node001 hadoop]# cat slaves
node01
到此已配置完成
执行
hdfs namenode -format
进行格式化
[root@node001 current]# pwd
/var/zzh/hadoop/local/dfs/name/current
可以看到我之前配置NameNode存储源文件的目录已经帮我创建好了,并为我们创建了其他目录。
启动服务
start-dfs.sh 如果启动服务出现如下警告内容
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
在hadoop的存储文件目录下创建个用户目录
[root@node001 /]# hdfs dfs -mkdir -p /user/root
传个文件
[root@node001 hadoop]# hdfs dfs -put hadoop-2.6.5.tar.gz /user/root
实际存储位置如下
/var/zzh/hadoop/local/dfs/data/current/BP-2092721427-192.168.46.21-1538257004531/current/finalized/subdir0/subdir0
zzh/hadoop/ 这两层目录是上面我在配置文件中配置的。后面的都是自动生成的
通过
http://ip地址:50070 可以查看hadoop的存储信息
hadoop默认将我们上传的文件以128M为大小分成多个块,如下刚上传的hadoop被分为两个块
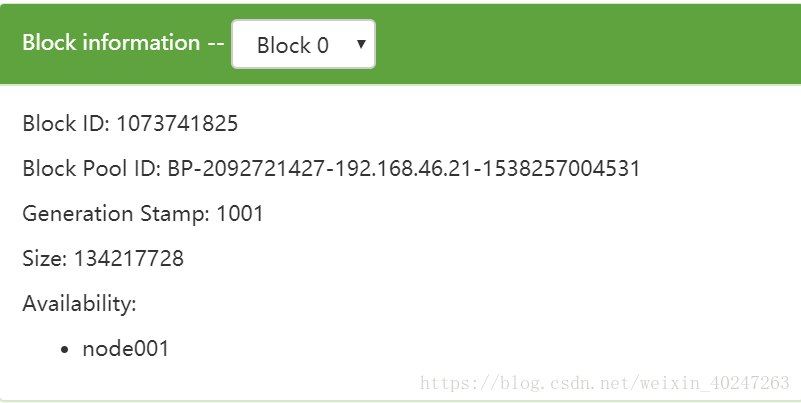
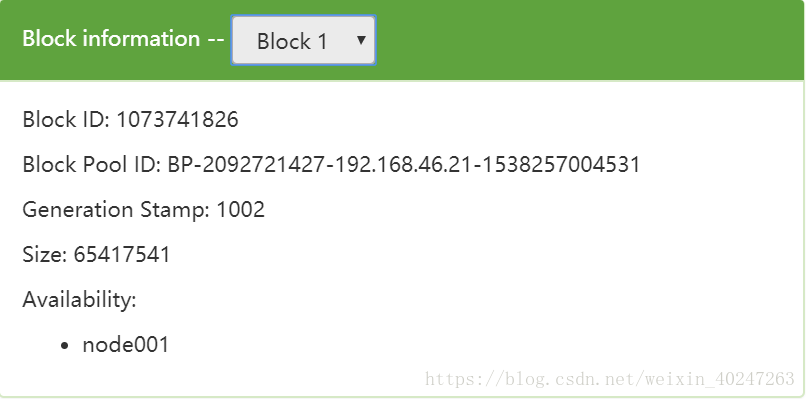
我们还可以执定每个块大小
[root@node001 subdir0]# ll -h
total 194M
-rw-r--r--. 1 root root 128M Sep 30 10:21 blk_1073741825
-rw-r--r--. 1 root root 1.1M Sep 30 10:21 blk_1073741825_1001.meta
-rw-r--r--. 1 root root 63M Sep 30 10:21 blk_1073741826
-rw-r--r--. 1 root root 500K Sep 30 10:21 blk_1073741826_1002.meta
-rw-r--r--. 1 root root 1.6M Sep 30 10:32 test.txt
[root@node001 subdir0]# hdfs dfs -D dfs.blocksize=1048576 -put test.txt
如上,我将 1.6M 的文件上传到 hadoop
存储情况如下
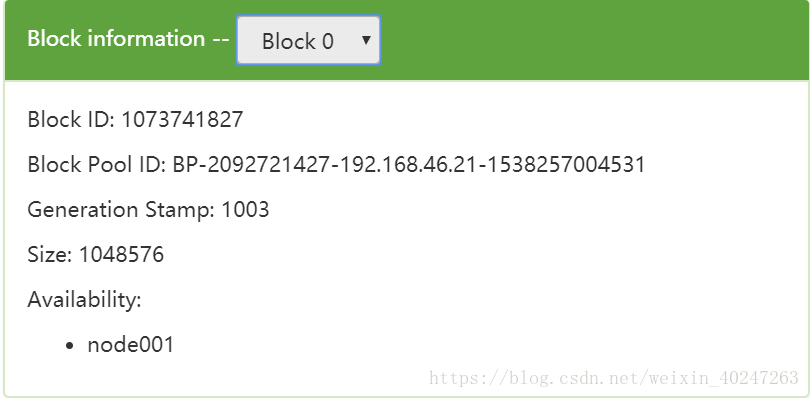

可以看出 hadoop 是以字节为单位来分割文件从而存储的 ,所以上层在使用hadoop时如果上传文件包含中文字符需要自己规避中文被以字节切割产生的乱码问题。

















 5949
5949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









