






文章目录
为什么要有虚拟内存
- 进程地址空间不隔离,没有权限保护。由于程序都是直接访问物理内存,所以一个进程可以修改其他进程的内存数据甚至修改内核地址空间中的数据。
- 内存使用效率低。当内存空间不足时,要将其他程序暂时拷贝到硬盘,然后将新的程序装入内存运行。由于大量的数据装入装出,内存使用效率会十分低下。
- 程序运行的地址不确定。因为内存地址是随机分配的,所以程序运行的地址也是不确定的。
内存管理架构
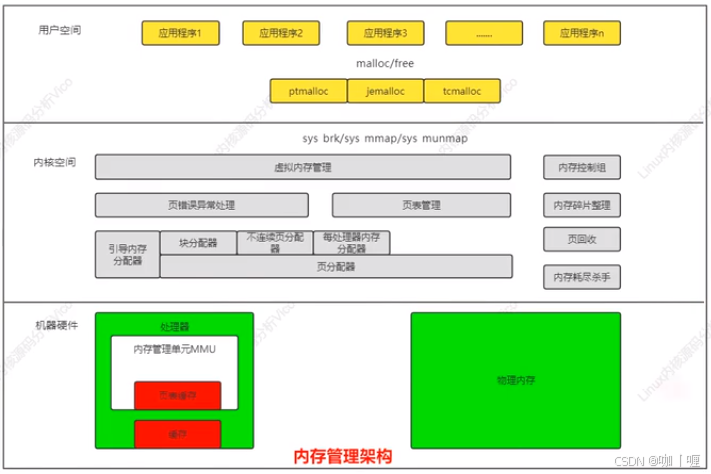
1、用户空间
应用程序使用malloc()申请内存空间,使用free()释放内存空间。
2、内核空间
1)内核空间的基本功能
虚拟内存管理:负贵从进程的虚拟地址空间分配虚拟页,sys_brk用来扩大或收缩堆,sys_mmap用来在内存映射区域分配虚拟页sys_munmap用米释放虚拟页。内核使用延迟分配物理内存的策略,进程第一次访问虚拟页的时候,触发页错误异常,页错误异常处理程序从页分配器申请物理页,在进程的页表中把虚拟页映射到物理页。
页分配器负责分配物理页,页分配器是伙伴分配器,内核空间提供把页划分成小内存块分司的块分配器,提供分配内存的接口kmalloc()和释放内存的借口kfree(),支持3种分配器:slab分配器、slub分配器和slob分配器。在内核初始化的过程中,页分配器还没有准备好,需要使用临时的引导内存分配器分配内存,
2)内核空间的扩展功能
不连续页分配器提供分配内存的接口vmalloc和释放内存的接口vfree,在内存碎片化的时候,申请连续物理页的成功率很低,可以申请不连续的物理页,映射到连续的虚拟页,即虚拟地址连续页物理地址不连续,每处理器内存分配器用来为每处理器变量分司内存。
连续内存分配器用来给驱动程序预留一段连续的内存,当驱动程序不用的时候,可以给进程便用;当驱动程序需要使用的时候,把进程占用的内存通过回收或迁移的方式让出来,给驱动程序使用,内存控制组用来控制进程占用的内存资源。
3、硬件层面
处理器包含一个称为内存管理单元(MMU,Memory Management Uint)的部件,负责把虚拟地址转换成物理地址。内存管理 单元包含一个页表缓存(TLB,TranslationLookaside Bufer)的部件。保存最近使用过的页表映射,避免每次把虚拟地址转换物理地址都需要查询内存中页表。
为了解决处理器的执行速度和内存的访问速度不匹配的问题,在处理器和内存之间增加缓存。缓存通常分为一级缓存和二级缓存,为了支持并行地取指令和取数据,一级缓存分为数据缓存和指令缓存。
虚拟地址空间
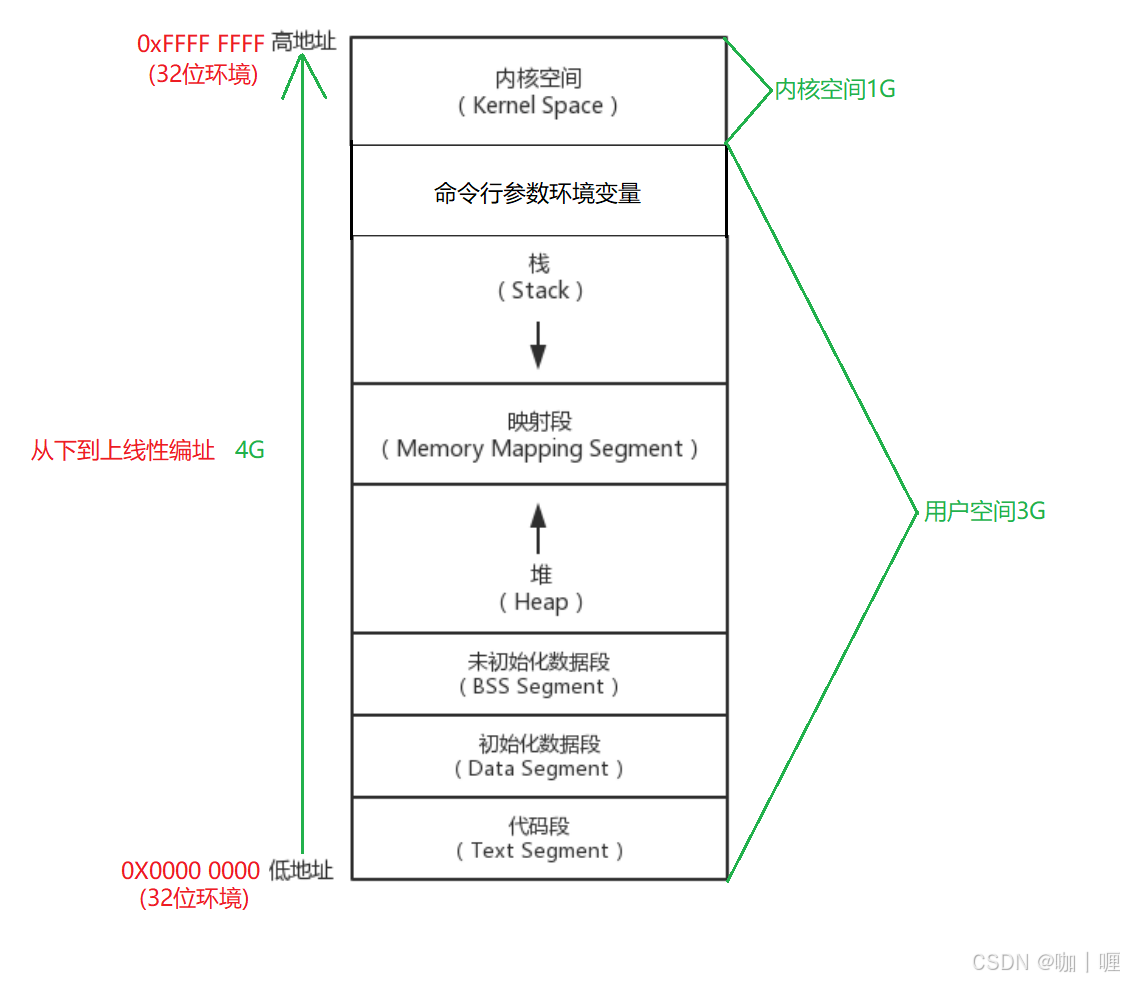
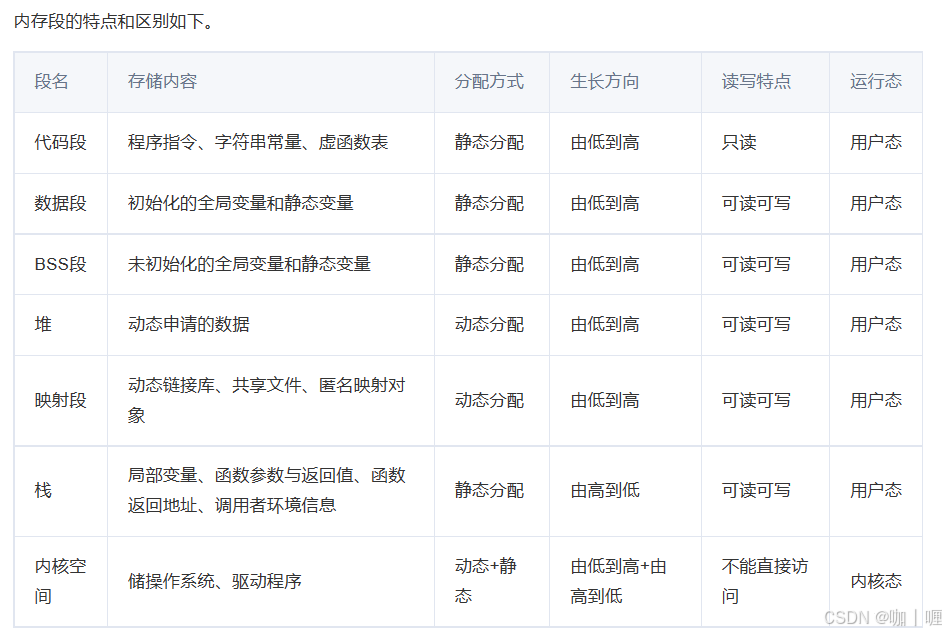
内核地址空间
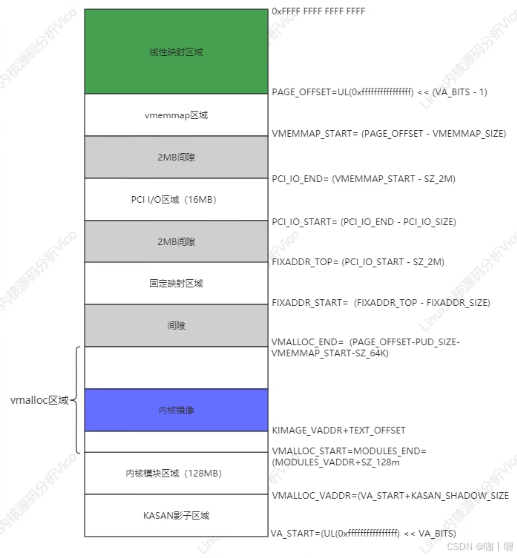
内存映射
Linux把虚存空间分成若干个大小相等的存储分区,Linux把这样的分区叫做页。为了换入、换出的方便,物理内存也就按也得大小分成若干个块。由于物理内存中的块空间是用来容纳虚存页的容器,所以物理内存中的块叫做页框。操作系统虚拟内存到物理内存的映射表,就被称为页表。页与页框是Linux实现虚拟内存技术的基础。

物理内存和虚拟内存被分成了页框与页之后,其存储单元原来的地址都被自然地分成了两段,并且这两段各自代表着不同的意义:高位段分别叫做页框码和页码,它们是识别页框和页的编码;低位段分别叫做页框偏移量和页内偏移量,它们是存储单元在页框和页内的地址编码。
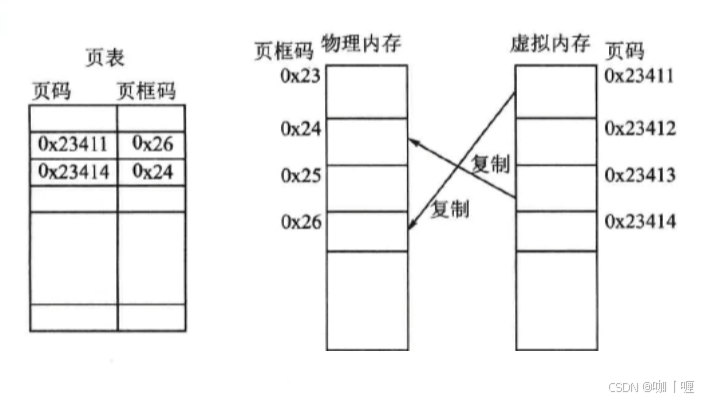
为了使系统可以正确的访问页在对应页框中的映像,在把一个页映射到某个页框上的同时,就必须把页码和存放该页映像的页框码填入一个叫做页表的表项中,这个页表就是映射记录表。
TLB
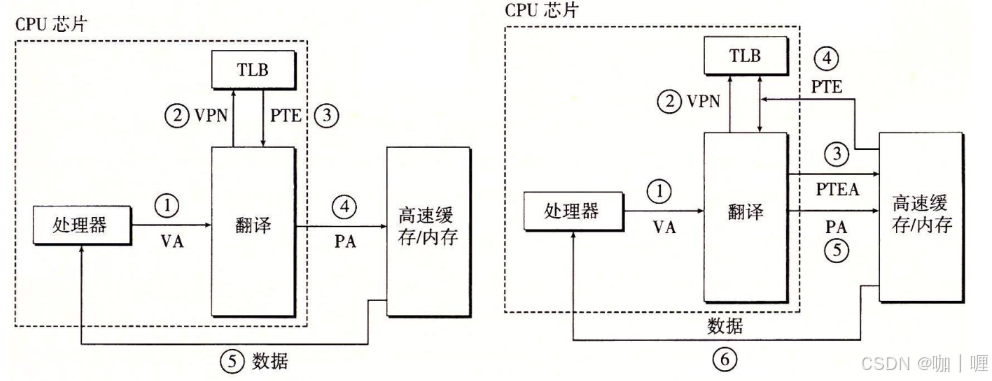
由于 CPU 首先接到的是由程序传来的虚拟内存地址,所以CPU必须先到物理内存中取页表,然后对应程序传来的虚拟页面号,在表里找到对应的物理页面号,最后才能访问实际的物理内存地址,也就是说整个过程中 CPU 必须访问两次物理内存。
为了减少因为 MMU 导致的处理器性能下降,引入了 TLB(Translation Lookaside Buffer,转换后援缓存器)。简单地说,TLB 就是页表的 Cache,其中存储了当前最可能被访问到的页表项,其内容是部分页表项的一个副本。只有在 TLB 无法完成地址翻译任务时,才会到内存中查询页表,这样就减少了页表查询导致的处理器性能下降。
TLB工作的基本原理:
- 当 CPU 执行指令时,会生成虚拟地址。这个虚拟地址包含了一个页号和一个页内偏移量。
- CPU 首先检查 TLB 是否包含了虚拟页号和物理页号的映射关系。如果 TLB 中有,那么 CPU 可以直接从 TLB 中获取物理页号。
- 如果 TLB 中没有虚拟页号和物理页号的映射关系,就称为 TLB 缺失(TLB miss)。在这种情况下,CPU 需要访问页表来查找这个映射关系。如果有相应的映射关系,则称为 TLB 命中(TLB Hit)。
- CPU 将虚拟页号发送到 MMU,MMU 会根据页表的内容找到对应的物理页号。
- 一旦找到了物理页号,CPU 会将这个映射关系加载到 TLB 中,以便以后的访问可以直接从 TLB 中获取物理页号。
- CPU 将从 TLB 中获取的物理页号与页内偏移量组合成物理地址,然后进行内存访问。
伙伴算法
Linux内核中的伙伴系统(Buddy System)是一种内存分配算法,它主要用于管理物理内存的分页。伙伴算法旨在减少内存碎片,提高内存分配和释放的效率。在Linux内核中,伙伴系统通常用于分配小块连续的物理内存。解决外部内存碎片化。
基本原理
分块管理:内存被分为一系列大小相等的块(pages),每个块的大小通常是2的幂次方,例如4KB、8KB、16KB等。
双向链表:每个块大小都有一个双向链表,用于管理该大小的空闲块。例如,所有大小为2n的块都放在一个链表中。
分配:当请求一个大小为2n的内存块时,系统首先检查是否有足够大的块直接满足请求。如果没有,系统会尝试从更大的块中分割出一个2n的块。例如,如果请求一个8KB的块,而系统中只有16KB的块,系统会将16KB的块分割成两个8KB的块,其中一个用于满足请求,另一个留在链表中。
释放:当内存块被释放时,如果该块的大小与链表中其他块的大小相同,它可以合并回链表中。如果释放的块大小大于链表中的其他块,它可能会与相邻的块合并以形成一个更大的块。
优势
减少碎片:通过精确控制内存块的分割和合并,伙伴算法可以有效地减少内存碎片。
快速分配和释放:由于内存块的管理是通过链表实现的,分配和释放操作可以非常快速地完成。
slab算法
内核本身有很多数据结构时时刻刻都需要分配或者释放,这些数据的大小又往往小于 4KB 大小,一般只有几个几十个字节这样的大小。而且大多数情况下,需要的内存大小都不是按页对齐的。比方最常用到的 task_struct(进程描述符)结构体和 mm_struct(内存描述符)结构体。这样一来如果所有的这些数据结构都按照页来分配存储和管理,那么内存中将会有大量的内存碎片。解决内部内存碎片化。
基本概念
slab层把不同的对象划分为所谓的高速缓存(cache)组,其中每个高速缓存都存放不同类型的对象。
每种对象类型对应一个高速缓存(cache)。例如一个高速缓存存放task_struct结构体而另外一个高速缓存存放struct_inode结构体。
每个高速缓存由多个slab组成。slab由一个或者多个物理上连续的页组成。每个页分配成多个对象。
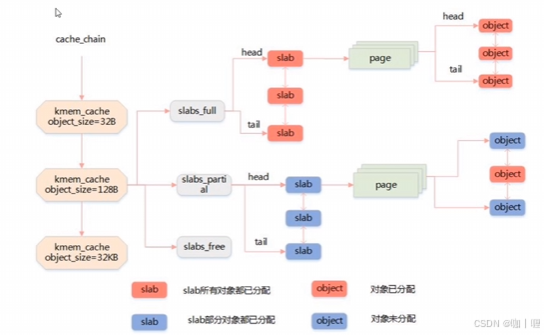
cache_chain
最高层是 cache_chain,这是一个 slab 缓存的链接列表。可以用来查找最适合所需要的分配大小的缓存(遍历列表)。cache_chain 的每个元素都是一个 kmem_cache 结构的引用(称为一个 cache)。它定义了一个要管理的给定大小的对象池。
kmem_cache
/*
* Slab cache management.
*/
struct kmem_cache {
// slab cache 的管理标志位,用于设置 slab 的一些特性
// 比如:slab 中的对象按照什么方式对齐,对象是否需要 POISON 毒化,是否插入 red zone 在对象内存周围,是否追踪对象的分配和释放信息 等等
slab_flags_t flags;
// slab 对象在内存中的真实占用,包括为了内存对齐填充的字节数,red zone 等等
unsigned int size; /* The size of an object including metadata */
// slab 中对象的实际大小,不包含填充的字节数
unsigned int object_size;/* The size of an object without metadata */
// slab 对象池中的对象在没有被分配之前,我们是不关心对象里边存储的内容的。
// 内核巧妙的利用对象占用的内存空间存储下一个空闲对象的地址。
// offset 表示用于存储下一个空闲对象指针的位置距离对象首地址的偏移
unsigned int offset; /* Free pointer offset */
// 表示 cache 中的 slab 大小,包括 slab 所需要申请的页面个数,以及所包含的对象个数
// 其中低 16 位表示一个 slab 中所包含的对象总数,高 16 位表示一个 slab 所占有的内存页个数。
struct kmem_cache_order_objects oo;
// slab 中所能包含对象以及内存页个数的最大值
struct kmem_cache_order_objects max;
// 当按照 oo 的尺寸为 slab 申请内存时,如果内存紧张,会采用 min 的尺寸为 slab 申请内存,可以容纳一个对象即可。
struct kmem_cache_order_objects min;
// 向伙伴系统申请内存时使用的内存分配标识
gfp_t allocflags;
// slab cache 的引用计数,为 0 时就可以销毁并释放内存回伙伴系统重
int refcount;
// 池化对象的构造函数,用于创建 slab 对象池中的对象
void (*ctor)(void *);
// 对象的 object_size 按照 word 字长对齐之后的大小
unsigned int inuse;
// 对象按照指定的 align 进行对齐
unsigned int align;
// slab cache 的名称, 也就是在 slabinfo 命令中 name 那一列
const char *name;
};
slabs_full、slabs_partial、slabs_empty
每个缓存都包含了一个 slabs 列表,这是一段连续的内存块(通常都是页面)。其中每个 kmem_cache 有三条链表:
- slabs_full 表示该链表中每个 slab 的 object 对象都已经分配完了。
- slabs_partial 表示该链表中的 slab 的 object 对象部分分配完了。
- slabs_empty 表示该链表中的 object 对象全部没有分配出去(空 slab,未分配)
对象的分配和释放都是在 slab 中进行的,所以 slab 可以在三条链表中移动,如果 slab 中的 object 都分配完了,则会移到 full 链表中;如果分配了一部分 object,则会移到 partial 链表中;如果所有 object 都释放了,则会移动到 empty 链表中;其中当系统内存紧张的时候,slabs_empty 链表中的 slab 可能会被返回给系统。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









