




选用昨天kmeans得到的效果进行聚类,进而推断出每个簇的实际含义
一、数据预处理
# 先运行之前数据预处理的代码 (不包含划分数据集)
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。
import warnings
warnings.filterwarnings("ignore")
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data = pd.read_csv('data.csv') #读取数据
# 先筛选字符串变量
discrete_features = data.select_dtypes(include=['object']).columns.tolist()
# Home Ownership 标签编码
home_ownership_mapping = {
'Own Home': 1,
'Rent': 2,
'Have Mortgage': 3,
'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)
# Years in current job 标签编码
years_in_job_mapping = {
'< 1 year': 1,
'1 year': 2,
'2 years': 3,
'3 years': 4,
'4 years': 5,
'5 years': 6,
'6 years': 7,
'7 years': 8,
'8 years': 9,
'9 years': 10,
'10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)
# Purpose 独热编码,记得需要将bool类型转换为数值
data = pd.get_dummies(data, columns=['Purpose'])
data2 = pd.read_csv("data.csv") # 重新读取数据,用来做列名对比
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in data.columns:
if i not in data2.columns:
list_final.append(i) # 这里打印出来的就是独热编码后的特征名
for i in list_final:
data[i] = data[i].astype(int) # 这里的i就是独热编码后的特征名
# Term 0 - 1 映射
term_mapping = {
'Short Term': 0,
'Long Term': 1
}
data['Term'] = data['Term'].map(term_mapping)
data.rename(columns={'Term': 'Long Term'}, inplace=True) # 重命名列
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() #把筛选出来的列名转换成列表
# 连续特征用中位数补全
for feature in continuous_features:
mode_value = data[feature].mode()[0] #获取该列的众数。
data[feature].fillna(mode_value, inplace=True) #用众数填充该列的缺失值,inplace=True表示直接在原数据上修改。
# 最开始也说了 很多调参函数自带交叉验证,甚至是必选的参数,你如果想要不交叉反而实现起来会麻烦很多
# 所以这里我们还是只划分一次数据集
from sklearn.model_selection import train_test_split
X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列删除
y = data['Credit Default'] # 标签
# # 按照8:2划分训练集和测试集
# X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集
二、聚类
标准化数据
from sklearn.preprocessing import StandardScaler
# 标准化数据(聚类前通常需要标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)进行K-Means聚类
import numpy as np
import pandas as pd
# 画图
import matplotlib.pyplot as plt
import seaborn as sns
# KMeans聚类
from sklearn.cluster import KMeans
# 数据降维和可视化
from sklearn.decomposition import PCA
# 评估指标 轮廓系数、ch指数、db指数
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
# 评估不同k值下的指标
k_range = range(2, 11) # 测试 k 从 2 到 10
inertia_values = [] # 存储每个 k 值对应的 SSE(Inertia)
silhouette_scores = [] # 存储每个k值对应的轮廓系数
ch_scores = [] # 存储每个k值对应的CH系数
db_scores = [] # 存储每个k值对应的DB系数
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=42) # 初始化KMeans模型
kmeans_labels = kmeans.fit_predict(X_scaled) # 训练模型并获取聚类标签
inertia_values.append(kmeans.inertia_) # 计算并存储每个k值的惯性(肘部法则)
silhouette = silhouette_score(X_scaled, kmeans_labels) # 轮廓系数
silhouette_scores.append(silhouette)
ch = calinski_harabasz_score(X_scaled, kmeans_labels) # CH 指数
ch_scores.append(ch)
db = davies_bouldin_score(X_scaled, kmeans_labels) # DB 指数
db_scores.append(db)
print(f"k={k}, 惯性:{kmeans.inertia_:.2f}, 轮廓系数:{silhouette:.3f}, CH指数:{ch:.2f}, DB指数:{db:.3f}")
# 提示用户选择 k 值
selected_k = 3 # 这里选择3后面好分析,也可以根据图选择最佳的k值
# 使用选择的 k 值进行 KMeans 聚类
kmeans = KMeans(n_clusters=selected_k, random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
X['KMeans_Cluster'] = kmeans_labels
# 使用 PCA 降维到 2D 进行可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# KMeans 聚类结果可视化
plt.figure(figsize=(6, 5))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=kmeans_labels, palette='viridis')
plt.title(f'KMeans Clustering with k={selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()
# 打印 KMeans 聚类标签的前几行
print(f"KMeans Cluster labels (k={selected_k}) added to X:")
print(X[['KMeans_Cluster']].value_counts())输出:
k=2, 惯性:218529.50, 轮廓系数:0.320, CH指数:479.34, DB指数:3.222
k=3, 惯性:207982.87, 轮廓系数:0.209, CH指数:441.88, DB指数:2.906
k=4, 惯性:200477.28, 轮廓系数:0.220, CH指数:399.12, DB指数:2.441
k=5, 惯性:192940.36, 轮廓系数:0.224, CH指数:384.19, DB指数:2.042
k=6, 惯性:185411.81, 轮廓系数:0.227, CH指数:380.64, DB指数:1.733
k=7, 惯性:178444.49, 轮廓系数:0.130, CH指数:378.31, DB指数:1.633
k=8, 惯性:174920.27, 轮廓系数:0.143, CH指数:352.31, DB指数:1.817
k=9, 惯性:167383.96, 轮廓系数:0.150, CH指数:364.27, DB指数:1.636
k=10, 惯性:159824.84, 轮廓系数:0.156, CH指数:378.43, DB指数:1.502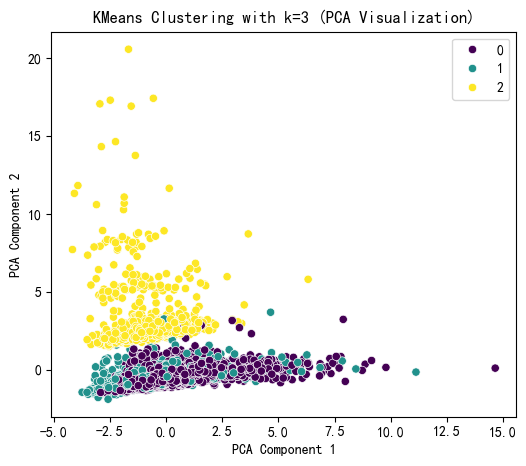
KMeans Cluster labels (k=3) added to X:
KMeans_Cluster
0 5205
1 1381
2 914
Name: count, dtype: int64现在需要给这个簇赋予实际的含义,一般当你赋予实际含义的时候,你需要根据某几个特征来赋予,但是源数据特征很多,如何选择特征呢?有2种思路:
法一:最开始聚类的时候,就选择了你最后用来确定簇含义的特征,那么你最后确定簇含义的特征就是这几个特征,而非全部。
- 比如你想聚类消费者购买习惯,那么他过去的消费记录、购买记录、购买金额等等,这些特征都与消费者购买习惯有关,你可以只使用这些特征来确定簇含义,一些其他的特征,如消费者年龄,工作行业则不考虑。(适用于你本身就有构造某些明确含义的特征的情况。)
法二:最开始用全部特征来聚类,之后把其余特征作为 x,聚类得到的簇类别作为标签构建监督模型,进而根据重要性筛选特征,来确定要根据哪些特征赋予簇含义。(适用于你想构造什么,目前还不清楚。)
三、寻找各簇的含义
运用 方法二
1、以聚类特征作为标签训练模型
X1 = X.drop('KMeans_Cluster',axis=1) # 删除聚类标签列
y1 = X['KMeans_Cluster'] # 作为标签
# 构建随机森林模型,再用shap重要性来筛选重要特征
import shap
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
model = RandomForestClassifier(n_estimators=100, random_state=42) # 随机森林模型,100棵决策树
model.fit(X1, y1) # 直接用全部数据进行训练2、利用shap可视化寻找重要特征
shap.initjs()
# 初始化 SHAP 解释器
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X1)
shap_values.shape # (样本数, 特征数, 类别数)输出:
(7500, 31, 3)注:由上步输出可得聚类特征下有3种类别。
shap 重要性条形图
# shap 重要性条形图
print('--- shap 重要性条形图 ---')
shap.summary_plot(shap_values[:, :, 0], X1, plot_type="bar", show=False)
plt.title('SHAP Feature Importance (Bar Plot)')
plt.show()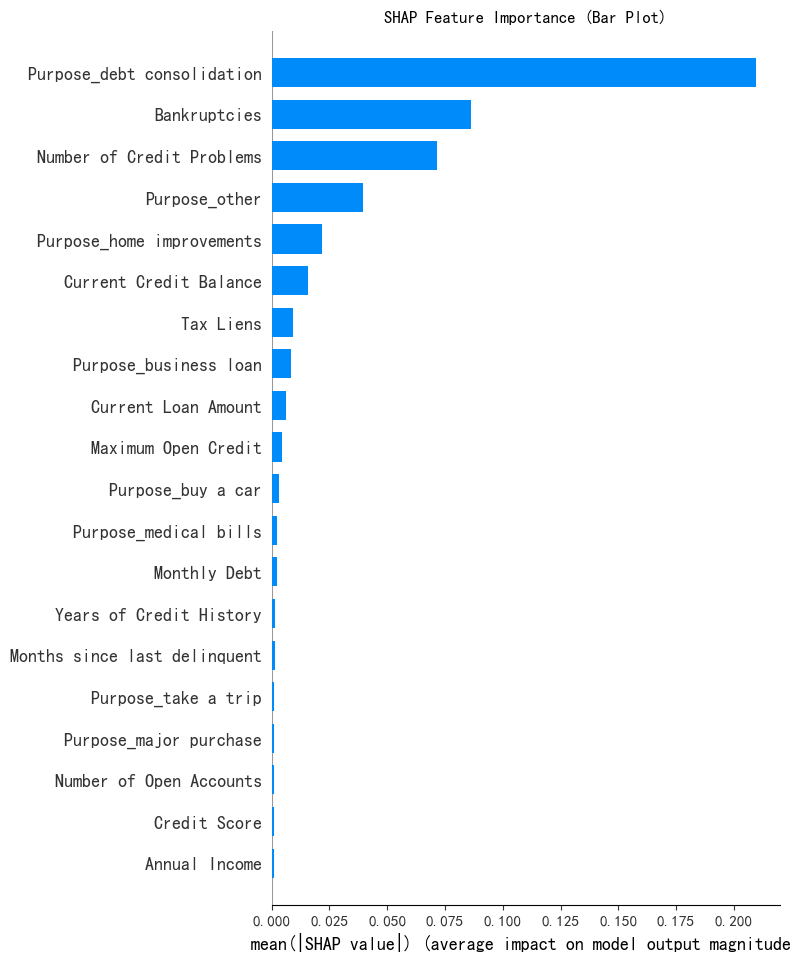
易得,前四个重要特征为:'Purpose_debt consolidation', 'Bankruptcies', 'Number of Credit Problems', 'Purpose_other'
3、各簇与重要特征图像
判断一下最重要的4个特征是离散型还是连续性,为后续作图的类型做准备。
# 判断一下最重要的4个特征是离散型还是连续性
# 通过特征下不同类别的个数,以 10 为界,而不像之前那样通过类型判断
select_features = ['Purpose_debt consolidation', 'Bankruptcies', 'Number of Credit Problems', 'Purpose_other']
for feature in select_features:
unique_count = X1[feature].nunique()
print(f"特征{feature}的类别数为{unique_count}")
if unique_count <= 10:
print(f"特征{feature}是离散型\n")
else:
print(f"特征{feature}是连续型\n")
输出:
特征Purpose_debt consolidation的类别数为2
特征Purpose_debt consolidation是离散型
特征Bankruptcies的类别数为5
特征Bankruptcies是离散型
特征Number of Credit Problems的类别数为8
特征Number of Credit Problems是离散型
特征Purpose_other的类别数为2
特征Purpose_other是离散型注:需要保证这四个特征是数值型,并且精准判断具体是离散型还是连续性,这里都是离散型数据
连续型特征:(如销售额、温度)适合用直方图展示分布
分类型特征:(如性别、产品类别)应改用条形图或饼图
样本中前4个特征的分布图
import matplotlib.pyplot as plt
# 样本中前4个特征的分布图
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes = axes.flatten() # 将二维数组展平为一维数组,方便循环
plt.rcParams['figure.dpi'] = 300 # 设置图像分辨率为300dpi
for i, feature in enumerate(select_features):
axes[i].hist(X1[feature], bins = 20)
axes[i].set_title(f"Histogram of {feature}")
axes[i].set_xlabel(feature)
axes[i].set_ylabel("Frequency")
plt.tight_layout() # 调整子图之间的间距
plt.show()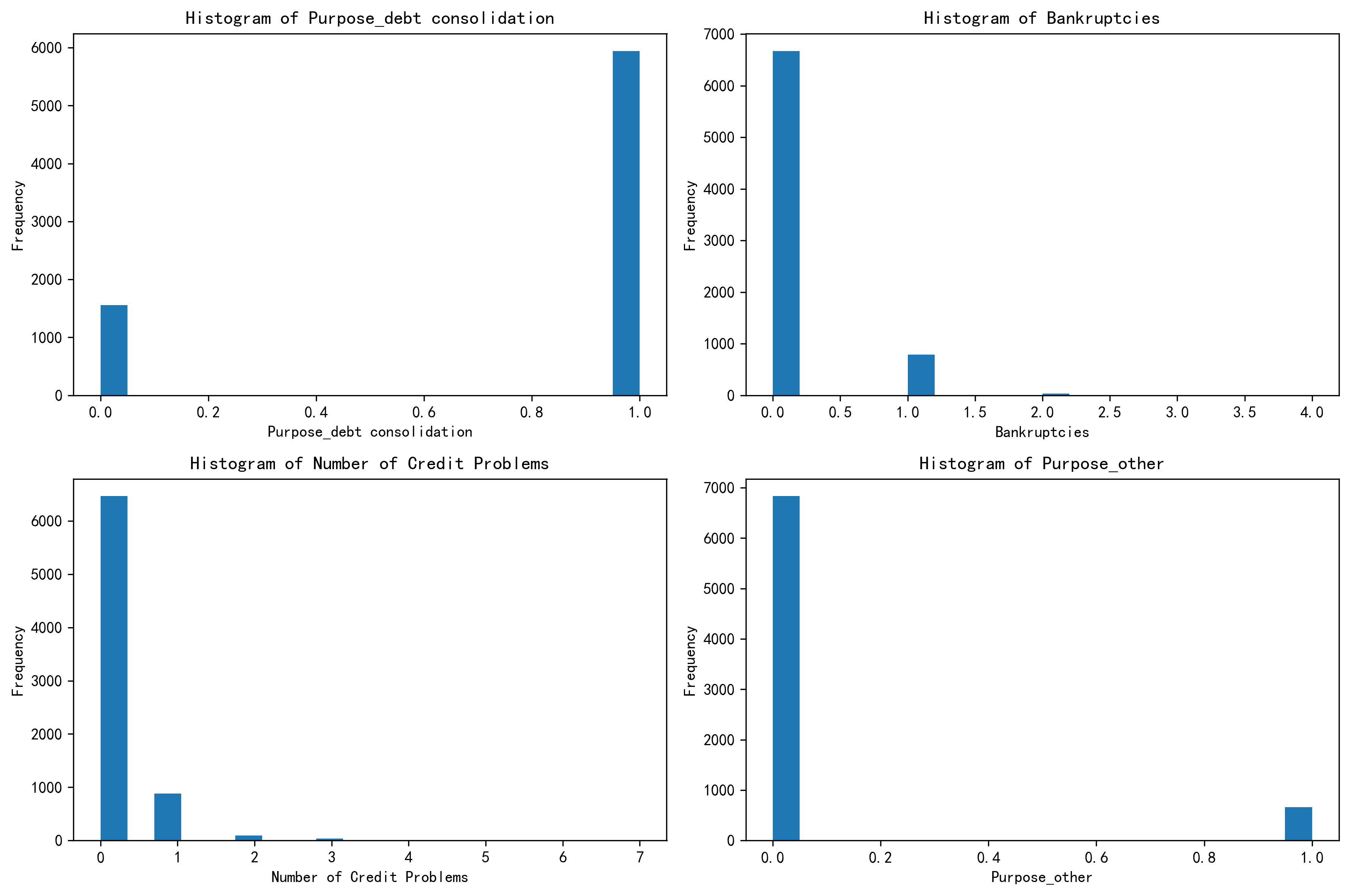
分离每个簇并展示各簇和重要特征的关系
# 查看聚类特征下的类别,为下步单独分离出每个簇的数据做准备
X[['KMeans_Cluster']].value_counts()输出:
KMeans_Cluster
0 5205
1 1381
2 914
Name: count, dtype: int64分离出每个簇的数据
# 分离出每个簇的数据
# == 0 :生成布尔序列,标记所有聚类标签等于0的数据点为True
# X[condition] :使用布尔索引筛选出满足条件(即属于簇0)的所有行数据
X_cluster0 = X[X['KMeans_Cluster'] == 0] # 有5205个样本
X_cluster1 = X[X['KMeans_Cluster'] == 1] # 有1381个样本
X_cluster2 = X[X['KMeans_Cluster'] == 2] # 有914个样本分别绘制每个簇对应的那4个特征的分布图,再根据分布图确定每个簇的含义。
(1)绘制 簇0 的分布图
# 绘制簇0的分布图
# 簇0 样本当中前四个重要特征的分布图
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
plt.rcParams['figure.dpi'] = 300
axes = axes.flatten()
for i, feature in enumerate(select_features):
axes[i].hist(X_cluster0[feature], bins=30) # 这里的bins=30表示将数据分成30个区间
axes[i].set_title(f'Histplot of {feature}')
axes[i].set_xlabel(feature)
axes[i].set_ylabel('Frequency')
plt.tight_layout()
plt.show()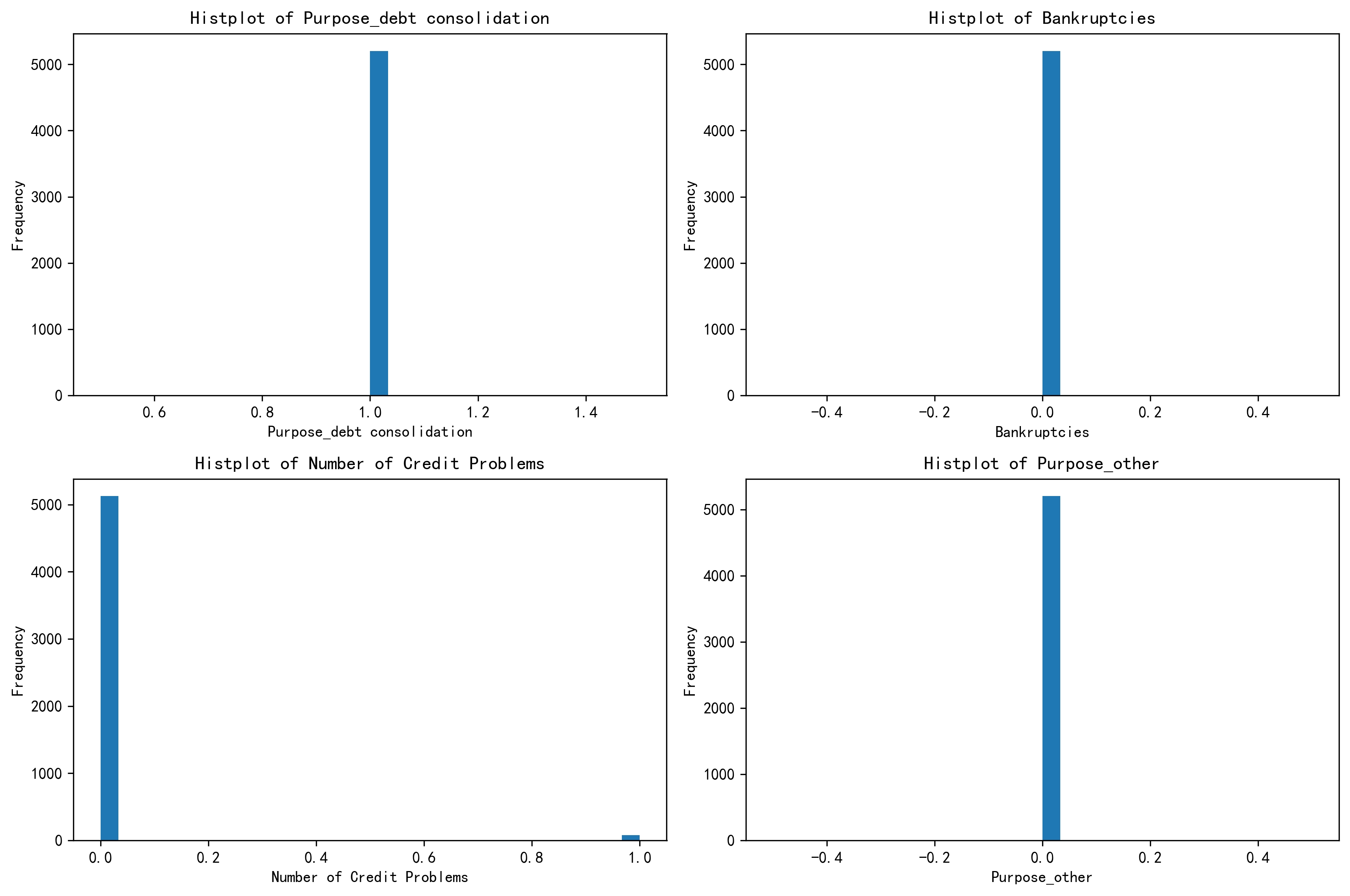
(2)绘制 簇1 的分布图
# 绘制簇1的分布图
# 簇1 样本当中前四个重要特征的分布图
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
plt.rcParams['figure.dpi'] = 300
axes = axes.flatten()
for i, feature in enumerate(select_features):
axes[i].hist(X_cluster1[feature], bins=30) # 这里的bins=30表示将数据分成30个区间
axes[i].set_title(f'Histplot of {feature}')
axes[i].set_xlabel(feature)
axes[i].set_ylabel('Frequency')
plt.tight_layout()
plt.show()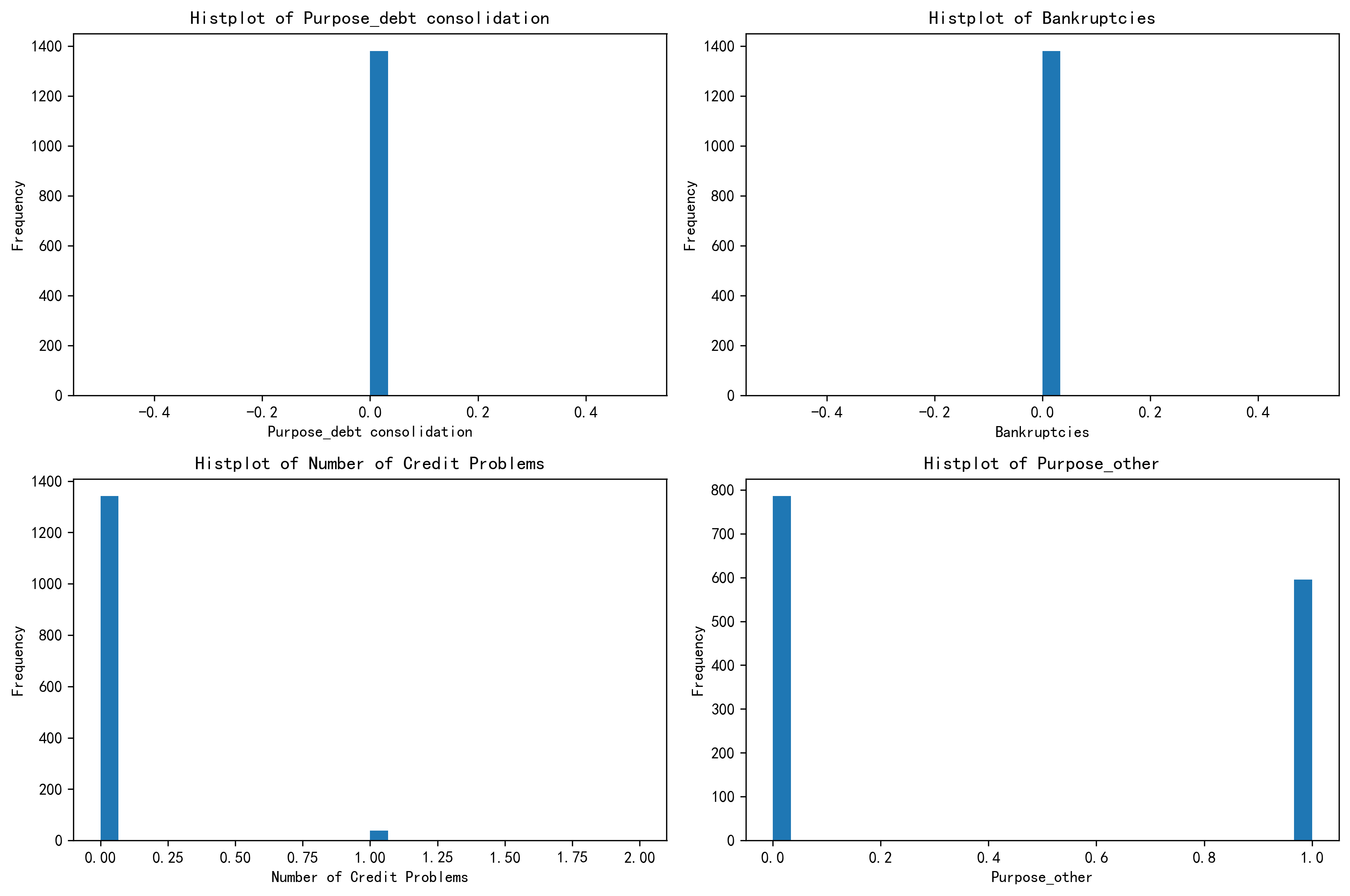
(3)绘制 簇2 的分布图
# 绘制簇2的分布图
# 簇2 样本当中前四个重要特征的分布图
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
plt.rcParams['figure.dpi'] = 300
axes = axes.flatten()
for i, feature in enumerate(select_features):
axes[i].hist(X_cluster2[feature], bins=30) # 这里的bins=30表示将数据分成30个区间
axes[i].set_title(f'Histplot of {feature}')
axes[i].set_xlabel(feature)
axes[i].set_ylabel('Frequency')
plt.tight_layout()
plt.show()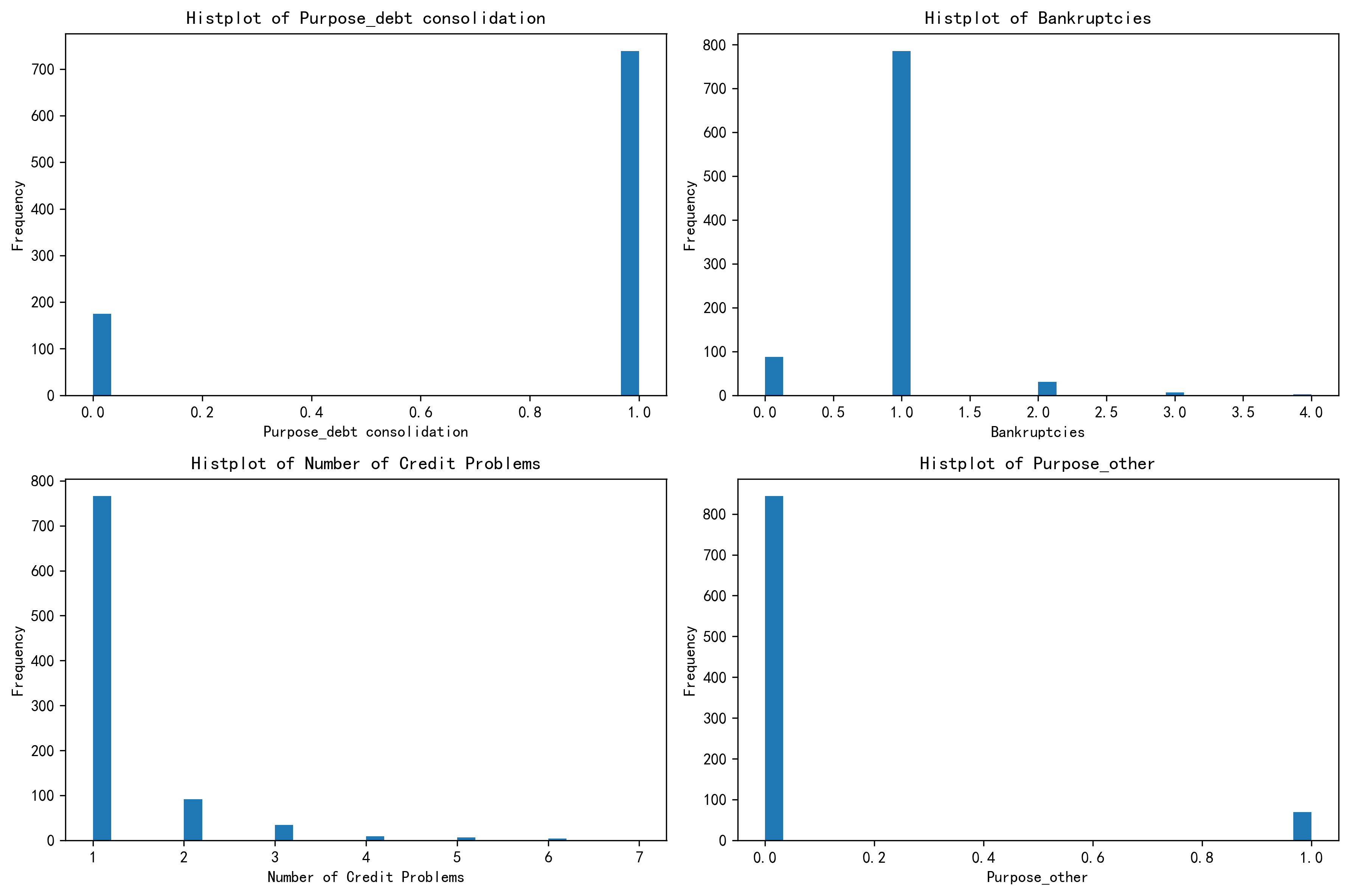
把这三个簇的图发给ai,让ai给你定义。
四、三个簇的总结与定义
- 第一个簇 - 优质信用稳健财务型
-
特征总结:在债务合并用途上表现一致,几乎无破产记录,信用问题极少,资金用途集中且很少涉及特殊类别。财务状况稳定,信用良好,资金流向明确。
-
定义依据:各项关键财务和信用指标表现优异,显示出良好的财务自律性和信用履约能力,所以定义为 “优质信用稳健财务型”。
-
- 第二个簇 - 较稳健但信用有分化财务型
-
特征总结:多数无债务合并需求,破产情况少见,但信用问题上存在个体差异,资金用途有一定分散性。整体财务状况相对稳定,但在信用和资金使用方向上不如第一个簇表现一致。
-
定义依据:虽然总体财务状况尚可,但信用记录和资金用途的分化情况使其区别于第一个簇,因此定义为 “较稳健但信用有分化财务型”。
-
- 第三个簇 - 高风险财务困境型
-
特征总结:债务合并需求分化,破产经历较多,信用问题普遍且严重,资金用途有差异。在财务健康和信用方面存在诸多问题,面临较大财务风险。
-
定义依据:基于明显的财务困境迹象和高风险特征,定义为 “高风险财务困境型”。
-
现在你就得到了一个全新的特征,完成了你的特征工程
后续研究需要对这个特征独热编码,然后重新建模训练,如果加了这个特征后模型精度提高,说明这个特征是有用的。

















 1179
1179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









