




 本文通过两个基本测试案例,详细介绍了如何在Hive中设置Reduce任务数量,并观察其对数据分布和处理效率的影响。测试一使用默认设置,测试二手动设置了Reduce任务数量,对比了两种情况下数据输出的差异。
本文通过两个基本测试案例,详细介绍了如何在Hive中设置Reduce任务数量,并观察其对数据分布和处理效率的影响。测试一使用默认设置,测试二手动设置了Reduce任务数量,对比了两种情况下数据输出的差异。
1.基本测试一
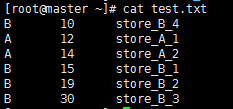
set mapred.reduce.tasks=-1;
set mapreduce.job.reduces=-1;
hive (hive_db)> insert overwrite local directory '/root/distribute_result1'
> select merid,money,name from store distribute by merid sort by money desc;
输出结果
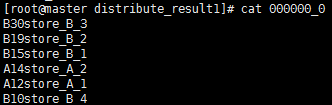
set mapred.reduce.tasks=2;
set mapreduce.job.reduces=2;
hive (hive_db)> insert overwrite local directory '/root/distribute_result2'
> select merid,money,name from store distribute by merid sort by money desc;
输出结果:
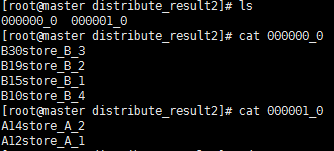
2.基本测试二

















 955
955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









