




 本文探讨了在Python中进行IO密集型操作时,如MySQL数据传递,多线程与多进程对CPU占用的影响。重点解析了IO操作是否消耗CPU资源,以及为何并发不等于CPU效率提升,还提到了DMA、并发意义和解决策略。
本文探讨了在Python中进行IO密集型操作时,如MySQL数据传递,多线程与多进程对CPU占用的影响。重点解析了IO操作是否消耗CPU资源,以及为何并发不等于CPU效率提升,还提到了DMA、并发意义和解决策略。
IO频繁读取占用CPU资源?
参考链接:
https://blog.youkuaiyun.com/qq_29454347/article/details/84997053
https://www.zhihu.com/question/27734728
场景:因为最近在做python与mysql数据传递,通过多线程多进程等加快读取速度,减小消耗的问题。因其中计算量很少,多为数据的写入与读取,认为可视为IO密集型操作。
IO密集型定义:CPU消耗很少,任务的大部分时间都是在等待IO操作完成。(IO的速度远远低于CPU和内存的速度)。
疑问:
1.IO读取不消耗CPU资源吗
2.就算一个消耗很少的话,IO密集型,说明IO过程很多。很多的话是不是也会占用很多CPU消耗
3.项目中虽然是IO型多线程线程池,但CPU占用也很高
引发:并发的意义
python中因为有GIL锁,多线程本质上同一时间也只能运行一个线程而已。所说的python多线程本质上也只是多并发。本人用3线程与3进程处理同样的数据,进程明显比线程快很多。
解1IO占用CPU资源,但是不多。原因是有DMA(直接存储器访问,director memory access)帮助。计算机硬件上使用DMA来访问磁盘等IO,也就是请求发出后,CPU就不再管了,直到DMA处理器完成任务,再通过中断告诉CPU完成了。所以总体来说单个IO对CPU占用的并不多
流程:
CPU计算文件地址 ——> 委派DMA读取文件 ——> DMA接管总线 ——> CPU的A进程阻塞,挂起——> CPU切换到B进程 ——> DMA读完文件后通知CPU(一个中断异常)——> CPU切换回A进程操作文件
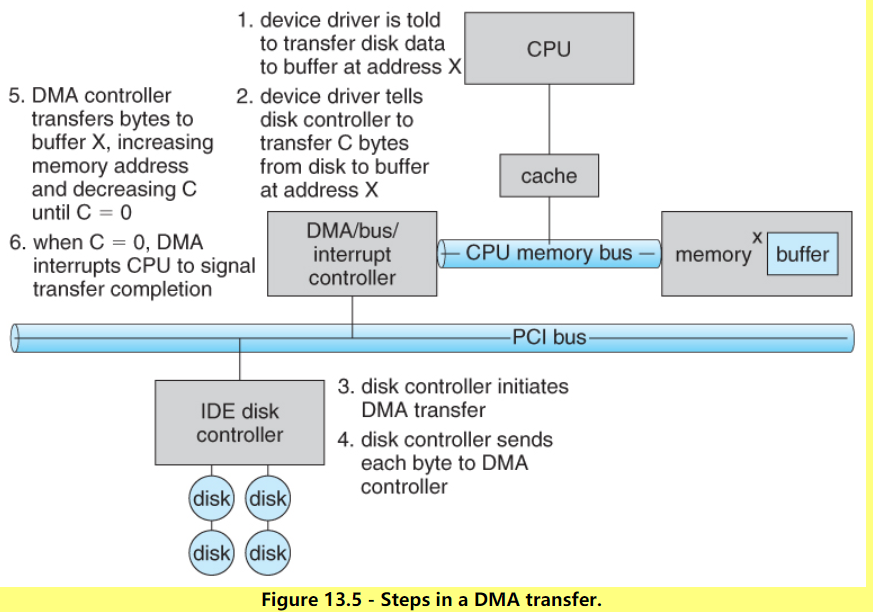
**解2:**虽然IO不会占用大量的CPU时间,但是非常频繁的IO还是会非常浪费CPU时间的,所以面对大量IO的任务,有时候是需要算法来合并IO,或者通过cache来缓解IO压力的。
**解3:**非空闲等待,比如IO等待、资源争用(同一资源被不同线程请求,而此资源又需要保持一致性,只能前一个释放后一个再访问,这样导致的等待)也会导致CPU过高
并发的意义:假设原先读取文件CPU需要傻等50纳秒。现在尽管两次上下文切换要各消耗5纳秒。CPU还是赚了40纳秒时间片。

















 378
378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









