







Kafka 概述
Kafka最初是是由 LinkedIn 开发的一个基于发布订阅的分布式的消息系统,由 Scala 编写,并于 2011 年初开源,Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
Kafka安装
安装前置环境
1、安装 JDK 1.8
2、安装 zookeeper 集群(也可以使用自带 ZooKeeper)
开始安装
1.下载kafka安装包:点击链接去kafka官网下载kafka安装包
2.集群规划安装
我的zk集群是三台,kafka也规划配置三台,分别部署在hadoop01、hadoop02、hadoop03三台节点上,集群规划不多赘述,各人根据自己需求安装即可
1)解压安装包
[hadoop@hadoop01 package]$ tar -zxvf kafka_2.11-1.1.0.tgz -C /home/hadoop/core/
2)在/home/hadoop/data 目录下创建 kafka文件夹,用于存储kafka的broker节点的topic及各种落盘数据
[hadoop@hadoop01 kafka_2.11-1.1.0]$ mkdir -p /home/hadoop/data/kafka
3)修改配置文件
[hadoop@hadoop01 ~]$ cd /home/hadoop/core/kafka_2.11-1.1.0/config
[hadoop@hadoop01 config]$ vim server.properties
修改配置以下属性:
broker.id=1 # kafka的broker节点的标识id,必须保证全局唯一
delete.topic.enable=true #表示开启topic删除功能,因为kafka topic默认是标记删除
auto.create.topics.enable=false #关闭kafka自动创建topic功能,为了配合delete.topic.enable参数,彻底删除topic
这两个参数同时开启才能保证topic被彻底删除,如果不开启这个参数只开启delete.topic.enable,那么当我们执行delete topic命令后,当有producer向删除的topic继续push消息时,kafka会根据默认配置再次创建我们已经删除掉的topic。如果执行命令删除topic失败,我们想手动彻底删除某个topic,需要做下面两个操作:
- 删除kafka存储目录(server.properties文件log.dirs配置,默认为"/tmp/kafka-logs")相关对应的某个topic目录
- 如果配置了delete.topic.enable=true直接通过命令删除,如果命令删除不掉,直接通过zkCli.sh登陆zk客户端窗口,执行 rmr /brokers/topics/[待删除的topic_name] 手动删除掉topic即可
host.name=hadoop01 # 指定当前节点主机名
listeners=PLAINTEXT://hadoop01:9092 # 配置这两个参数是为了将host主机和port端口告知给producers和consumers,方便producers和consumers远程连接监听,如果没有配置会return java.net.InetAddress.getCanonicalHostName()解析值# A comma separated list of directories under which to store log files
log.dirs=/home/hadoop/data/kafka # kafka 运行日志存放的路径# The default number of log partitions per topic. More partitions allow greater
num.partitions=4 #当前broker节点每个topic的分区数量,默认为1num.recovery.threads.per.data.dir=1 # 用来恢复和清理 data 下数据的线程数量log.retention.hours=168 #segment 文件保留的最长时间,默认超过7天数据将被删除zookeeper.connect= hadoop01:2181,hadoop02:2181,hadoop03:2181 #配置连接 Zookeeper 集群地址
zookeeper.connection.timeout.ms=60000 # Timeout in ms for connecting to zookeeper
broker.id=your broker id
host.name= your broker hostname
advertised.listeners=PLAINTEXT:// your broker hostname:9092
export KAFKA_HOME=/home/hadoop/core/kafka_2.11-1.1.0
export PATH=$PATH:$KAFKA_HOME/bin[hadoop@hadoop01 config]$ source ~/.bashrc
6)启动集群
- 先启动zookeeper集群
- 顺序启动kafka集群
#启动kafka集群
nohup kafka-server-start.sh -daemon \
/home/hadoop/core/kafka_2.11-1.1.0/config/server.properties \
1>/home/hadoop/logs/kafka/kafka_std.log \
2>/home/hadoop/logs/kafka/kafka_err.log &
#关闭kafka集群
kafka-server-stop.sh stopKafka 的各种 Shell 操作
1、启动集群每个节点的进程
nohup kafka-server-start.sh \
/home/hadoop/core/kafka_2.11-1.1.0/config/server.properties \
1>~/logs/kafka/kafka_std.log \
2>~/logs/kafka/kafka_err.log &2、创建 topic
kafka-topics.sh \
--create \
--zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 \
--replication-factor 3 \
--partitions 10 \
--topic kafka_test参数解释:
- --create 创建kafka topic
- --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 指定kafka的zookeeper地址
- --partitions 指定分区的个数
- --replication-factor 指定每个分区的副本个数
3、查看kafka已经创建的所有topic
kafka-topics.sh \
--list \
--zookeeper hadoop01:2181,hadoop02:2181,hadoop03:21814、查看某个指定的 kafka topic 的详细信息
kafka-topics.sh \
--zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 \
--describe \
--topic kafka_test 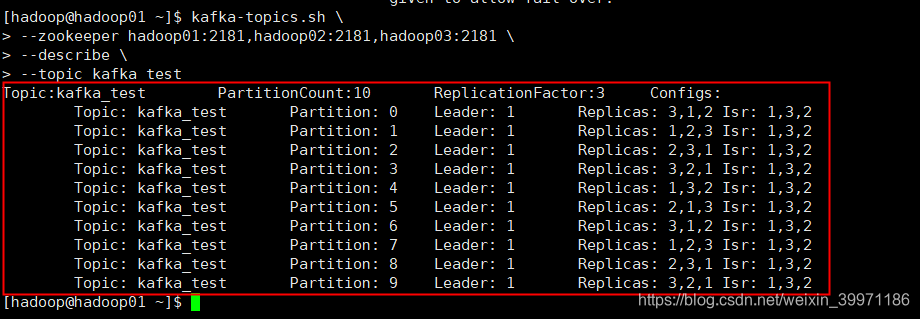
5、开启生产者模拟生成数据
kafka-console-producer.sh \
--broker-list hadoop01:9092,hadoop02:9092,hadoop03:9092 \
--topic kafka_test6、开启消费者模拟消费数据
kafka-console-consumer.sh \
--zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 \
--from-beginning \
--topic kafka_test 
注意:出现上面的提示是因为,Kafka 从 2.2 版本开始将 kafka-topic.sh 脚本中的 −−zookeeper 参数标注为 “过时”,推荐使用 −−bootstrap-server 参数,所以建议将 --zookeeper 参数及其值手动替换为--bootstrap-server,一定要注意两者参数值所指向的集群地址是不同的,−−zookeeper指向的是zk集群地址,而--bootstrap-server指向的是kafka集群地址
kafka-console-consumer.sh \
--bootstrap-server hadoop01:9092,hadoop02:9092,hadoop03:9092 \
--from-beginning \
--topic kafka_test
7、查看某 topic 某个分区的偏移量最大值和最小值
kafka-run-class.sh \
kafka.tools.GetOffsetShell \
--topic kafka_test \
--time -1 \
--broker-list hadoop01:9092,hadoop02:9092,hadoop03:9092 \
--partitions 1 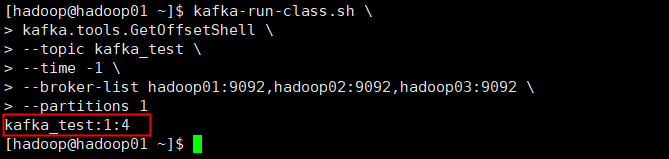
8、增加 topic 分区数
kafka-topics.sh \
--alter \
--zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 \
--topic kafka_test \
--partitions 209、删除 Topic
kafka-topics.sh \
--delete \
--zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 \
--topic kafka_test


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









