






 本文介绍了Kafka消息发送的整体架构,强调RecordAccumulator缓存的作用和参数配置对性能的影响。讨论了如何保持消息的有序性,特别是通过限制`max.in.flight.requests.per.connection`以避免错序。还详细讲解了同步、异步发送模式以及生产者拦截器的使用,拦截器允许在消息发送前后进行定制操作。
本文介绍了Kafka消息发送的整体架构,强调RecordAccumulator缓存的作用和参数配置对性能的影响。讨论了如何保持消息的有序性,特别是通过限制`max.in.flight.requests.per.connection`以避免错序。还详细讲解了同步、异步发送模式以及生产者拦截器的使用,拦截器允许在消息发送前后进行定制操作。
消息发送的整体架构
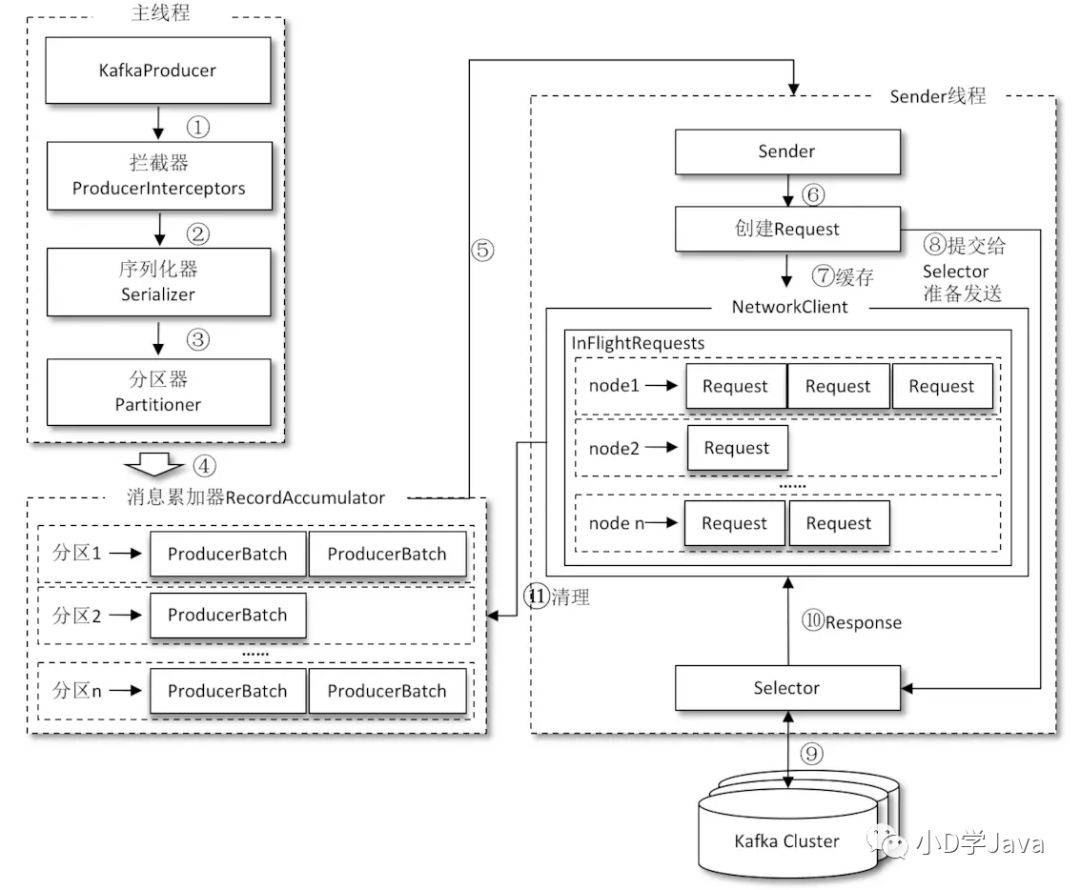
RecordAccumulator 主要用来缓存消息以便 Sender 线程可以批量发送,进而减少网络传输的资源消耗以提升性能。RecordAccumulator 缓存的大小可以通过生产者客户端参数 buffer.memory 配置,默认值为 33554432B,即32MB。如果生产者发送消息的速度超过发送到服务器的速度,则会导致生产者空间不足,这个时候 KafkaProducer 的 send() 方法调用要么被阻塞,要么抛出异常,这个取决于参数 max.block.ms 的配置,此参数的默认值为60000,即60秒。
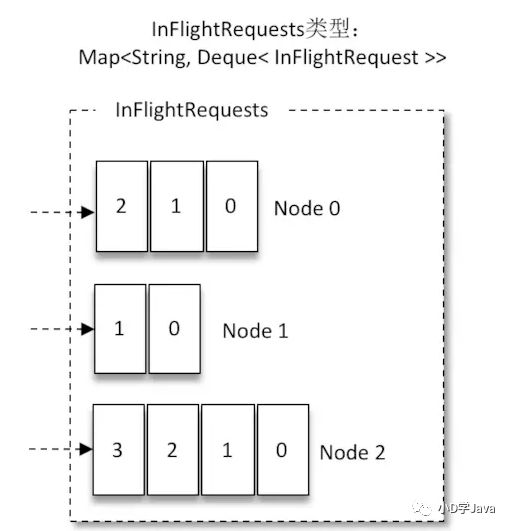
Kafka是通过broker中未确认的消息数来判断broker的负载的.未确认的消息数越多则负载越高.Sender线程通过InFlightRequests来缓存已经发出去但还没有收到响应的请求,具体形式为Map.
消息有序性
Kafka 可以保证同一个分区中的消息是有序的。如果生产者按照一定的顺序发送消息,那么这些消息也会顺序地写入分区,进而消费者也可以按照同样的顺序消费它们。
如果将acks参数配置为非零值,并且max.in.flight.requests.per.connection 参数配置为大于1的值,那么就会出现错序的现象:如果第一批次消息写入失败,而第二批次消息写入成功,那么生产者会重试发送第一批次的消息,此时如果第一批次的消息写入成功,那么这两个批次的消息就出现了错序。一般而言,在需要保证消息顺序的场合建议把参数 max.in.flight.requests.per.connection配置为1,而不是把 acks 配置为0,不过这样也会影响整体的吞吐。
max.in.flight.requests.per.connection = 1 限制客户端在单个连接上能够发送的未响应请求的个数(也就是客户端与 Node 之间的连接)。设置此值是1表示kafka broker在响应请求之前client不能再向同一个broker发送请求。注意:设置此参数是为了避免消息乱序
消息发送的三种模式
发后即忘(fire-and-forget,不保证消息到达broker,会丢消息)
同步(sync,同步发送,一条发完才发送下一条,每次都会返回Future值或抛异常,如果是可重试的异常,那么如果配置了retries参数则可自动重试)
异步(async,会有一个回调函数来通知消息的处理结果是成功还是异常)
同步代码
try { Future<RecordMetadata> future = producer.send(record); //阻塞获取结果,然后才能下一条发送 RecordMetadata metadata = future.get(); System.out.println(metadata.topic() + "-" +metadata.partition() + ":" + metadata.offset());} catch (ExecutionException | InterruptedException e) { //常见的可重试异常有:NetworkException、LeaderNotAvailableException、 //UnknownTopicOrPartitionException、NotEnoughReplicasException、NotCoordinatorException 等。 //对于可重试的异常,如果配置了 retries 参数,那么只要在规定的重试次数内自行恢复了,就不会抛出异常。 //不可重试异常如LeaderNotAvailableException ,RecordTooLargeException则是直接抛异常}异步代码
public class KafkaAsyncSender{ private static final Logger logger = LoggerFactory.getLogger(KafkaAsyncSender.class); //KafkaProducer 而言,它是线程安全的 private Producer producer; @Autowired private UdpSerializer udpSerializer; @Value("${kafka_connect_string}") private String kafkaConnectString; private Cache<String, Integer> cache; private KafkaTopicPartitionMapper mapper; @PostConstruct public void init() { Properties props = new Properties(); props.put("metadata.broker.list", kafkaConnectString.trim()); props.put("bootstrap.servers", kafkaConnectString.trim()); props.put("producer.type", "async");//消息发送类型同步(sync)还是异步(async将本地buffer) props.put("compression.codec", "none");//消息的压缩格式,默认为none不压缩,gzip, snappy, lz4 ////生产者发送消息之后,只要分区的 leader 副本成功写入消息,那么它就会收到来自服务端的成功响应 props.put("request.required.acks", "1"); //发送失败后重试的次数,允许重试 //如果 max.in.flight.requests.per.connection 设置不为1,可能会导致乱序 props.put("message.send.max.retries", 3);//失败重试次数 props.put("retry.backoff.ms", 100);//重试间隔 props.put("queue.buffering.max.ms", 10);//缓存数据的最大时间间隔 props.put("batch.num.messages", 1000);//缓存数据的最大条数 //限制生产者客户端能发送的消息的最大值,默认值为1048576B,即1MB,需注意broker端的message.max.bytes props.put("max.request.size", 1024 * 1024); props.put("key.serializer", "org.apache.kafka.common.serialization.ByteArraySerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.ByteArraySerializer"); this.producer = new KafkaProducer<String, String>(props); this.mapper = new KafkaTopicPartitionMapper(this.producer); this.cache = CacheBuilder.newBuilder().refreshAfterWrite(1, TimeUnit.SECONDS) .build(this.mapper); } //将被下面的handle类调用 public boolean sendMsg(final String topic, Object body, Callback callback) { //直接发送bytes数组 if(body instanceof byte[]){ ProducerRecord <String,byte[]>record = new ProducerRecord<String,byte[]>(topic,(byte[])body); producer.send(record); }else if(body instanceof BinlogEventInfo){ //对象类型的消息 final BinlogEventInfo binlogEventInfo = (BinlogEventInfo)body; Integer num = null; //获取发送到kafka的key,这里是使用guava缓存了key String cacheKey = genCacheKey(topic, binlogEventInfo); num = this.cache.getIfPresent(cacheKey); if(num == null){ try { num = this.mapper.load(cacheKey); } catch (Exception e) { logger.error("load kafka partition cache exception :", e); } if(num == null){ this.cache.put(cacheKey, Integer.MIN_VALUE); } else { this.cache.put(cacheKey, num); } } //构造发送的消息体,注意序列化是使用Byte序列化,没使用默认的String ProducerRecord <String,byte[]>record = null; if(num == Integer.MIN_VALUE || num == null){ //获取key失败,不使用key的构造发送发送数据 if(logger.isDebugEnabled()){ logger.debug("get partition fail , send to {}, info {}" , topic, JsonUtils.toJson((binlogEventInfo))); } record = new ProducerRecord<String,byte[]>(topic,udpSerializer.serialize(binlogEventInfo)); } else { //根据key指定到哪一个分区的发送 if(logger.isDebugEnabled()){ logger.debug("send to {}, partition {}, info {}" , topic, num, JsonUtils.toJson((binlogEventInfo))); } //这里有三个可能影响到分区数的因素 : 1.直接指定分区数 2,直接指定key 3.无任何指定 //在直接指定了分区数的情况下,那么将直接发送往此分区 //若分区数未指定,但key指定了,那么因为计算的hash值一样,那么相同的key也会发送到一样的分区 //若都未指定,则直接轮询分区来发送消息 record = new ProducerRecord<String,byte[]>(topic, num , null ,udpSerializer.serialize(binlogEventInfo)); } producer.send(record, callback); } return true; } private String genCacheKey(String topic, BinlogEventInfo binlogEventInfo) { return topic + "-" + binlogEventInfo.getHost() + "-" + binlogEventInfo.getSchemaName() + "-" + binlogEventInfo.getTableName(); }}Mapper的查询分区
public class KafkaTopicPartitionMapper extends CacheLoader<String, Integer>{ private Producer producer; public KafkaTopicPartitionMapper(Producer producer){ this.producer = producer; } @Override //格式 topic-host-database-table public Integer load(String key) throws Exception { try{ String[] arr = key.split("-"); int hash = this.hash(key); List list = this.producer.partitionsFor(arr[0]); int psize = list.size(); if(psize == 0){ return null; } else { //根据哈希值 % 分区数 return parlist.get(Math.abs(hash % psize)); } } catch(Exception e){ return null; } } //计算hash值 private int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } }异步的消息回调
//kafka消息管理类,发送消息以及回调处理public class KafkaQueueChannelHandler extends AsyncQueueChannelHandler{ private KafkaAsyncSender sender; public KafkaQueueChannelHandler(){ super("kafka"); this.sender = SpringContextUtil.getBean(KafkaAsyncSender.class); } public KafkaQueueChannelHandler(String identity) { super(identity); this.sender = SpringContextUtil.getBean(KafkaAsyncSender.class); } @Override public void sendMessage(BinlogEventInfo info, DeliverInfo deliverInfo) { //发送主题消息的时候设置回调 if(!sender.sendMsg(deliverInfo.getSendTopic(), info, new KafkaCallback(info, deliverInfo))) { this.stopDeliverAndNotify(info,Constants.SENDTYPE_KAFKA,"",deliverInfo.getSendTopic()); } } @Override public void sendMessageInner(BinlogEventInfo info, DeliverInfo deliverInfo) { this.sender.sendMsg(deliverInfo.getSendTopic(), info, new KafkaCallback(info, deliverInfo)); } private class KafkaCallback implements Callback{ private BinlogEventInfo info; private DeliverInfo deliverInfo; public KafkaCallback(BinlogEventInfo info, DeliverInfo deliverInfo) { this.info = info; this.deliverInfo = deliverInfo; } //异步回调方法 @Override public void onCompletion(RecordMetadata metadata, Exception exception) { //onCompletion() 方法的两个参数是互斥的,消息发送成功时,metadata 不为 null 而 exception 为 null; //消息发送异常时,metadata 为 null 而 exception 不为 null。 try{ if(metadata!=null){ logger.info("kafka回调信息:topic=【{}】,partition=【{}】,offset=【{}】,发送内容=【{}】,exception=【{}】,",metadata.topic(),metadata.partition(), metadata.offset(),JSON.toJSONString(info),exception); }else{ logger.info("kafka回调信息:发送内容=【{}】,exception=【{}】,",JSON.toJSONString(info),exception); } if(exception!=null){ stopDeliverAndNotify( info,Constants.SENDTYPE_KAFKA,"", this.deliverInfo.getSendTopic()); } else { //将位置信息保存到内存,异步更新到数据库 updatePosition(info, this.deliverInfo); } }catch(Exception e){ logger.error("KafkaQueueChannelHandler kafka回调处理失败:发送内容=【{}】,exception=【{}】",JSON.toJSONString(info),e); stopDeliverAndNotify( info,Constants.SENDTYPE_KAFKA,"", this.deliverInfo.getSendTopic()); } } } }生产者拦截器
生产者拦截器既可以用来在消息发送前做一些准备工作,比如按照某个规则过滤不符合要求的消息、修改消息的内容等,也可以用来在发送回调逻辑前做一些定制化的需求,比如统计类工作。
生产者拦截器的使用也很方便,主要是自定义实现 org.apache.kafka.clients.producer. ProducerInterceptor 接口。ProducerInterceptor 接口中包含3个方法:
//KafkaProducer在将消息序列化和计算分区之前会调用生产者拦截器的 onSend() 方法来对消息进行相应的定制化操作。public ProducerRecordonSend(ProducerRecord record);//KafkaProducer会在消息被应答(Acknowledgement)之前或消息发送失败时调用生产者拦截器的onAcknowledgement() 方法,//优先于用户设定的 Callback 之前执行。public void onAcknowledgement(RecordMetadata metadata, Exception exception);public void close();添加生产者拦截器
//此参数默认值为""properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, ProducerInterceptorPrefix.class.getName());实现
//接口的这3个方法中抛出的异常都会被捕获并记录到日志中,但并不会再向上传递。public class ProducerInterceptorPrefix implements ProducerInterceptor<String,String>{ @Override public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) { //更改消息内容 String modifiedValue = "prefix1-" + record.value(); return new ProducerRecord<>(record.topic(), record.partition(), record.timestamp(), record.key(), modifiedValue, record.headers()); } @Override public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {} @Override public void close() {} @Override public void configure(Map<String, ?> map) {}}参考链接
https://juejin.im/book/5c7d467e5188251b9156fdc0/section/5c7d5391f265da2db7183fe5

















 7328
7328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









