







 YOLO(You Only Look Once)是一种快速的目标检测算法,以其端到端的网络结构实现高效检测。该文详细介绍了YOLOv1的架构,包括网络结构、训练过程,以及性能特点。YOLO通过将输入图像划分为网格,每个网格预测多个边界框和类别概率,直接对整张图进行训练。训练中,YOLO在ImageNet数据集预训练,并采用特定的损失函数优化坐标、大小和分类的误差。虽然在定位精度上可能低于最优系统,但YOLO的背景预测假阳性较低,整体运行速度快。
YOLO(You Only Look Once)是一种快速的目标检测算法,以其端到端的网络结构实现高效检测。该文详细介绍了YOLOv1的架构,包括网络结构、训练过程,以及性能特点。YOLO通过将输入图像划分为网格,每个网格预测多个边界框和类别概率,直接对整张图进行训练。训练中,YOLO在ImageNet数据集预训练,并采用特定的损失函数优化坐标、大小和分类的误差。虽然在定位精度上可能低于最优系统,但YOLO的背景预测假阳性较低,整体运行速度快。
yolo统一架构做目标检测速度非常快,是端到端的网络,定位错误会高于最优检测系统,但是背景预测的假阳性会更低。
1、介绍:
在yolo之前出现的方法,像DPM(deformable parts models)是使用滑动窗口的方法,分类器在整个图像上以均匀间隔的位置运行。R-CNN则是先选出提议区域,产生潜在的边界框,并在此上运行分类器。后处理细化边界框,消除重复检测,并根据场景中的其他目标重新划分框,这种方法比较复杂,并且运行速度慢。
yolo很简单,只有单独的卷积网络,同时预测多个边界框和框的分类。直接在整张图上做训练。

2、架构设计
系统将输入图像分成SXS的网格,如果目标的中心落入网格单元,该网格单元就负责检测那个目标。每个网格单元预测B个边界框和这些框的置信度。置信度的计算是Pr(Object) ∗ IOU(truth pred)。每个边界框包含5个预测:x,y,w,h,c(置信度)。(x,y)坐标指框的中心相对网格单元的边界的相对坐标,宽高是相对与图片。每个网格单元还会预测C条件类别概率Pr(ClassijObject)。这些概率是在包含目标的网格单元上预测的,每个网格单元只预测类别中的一种,不管有多少框包含它。
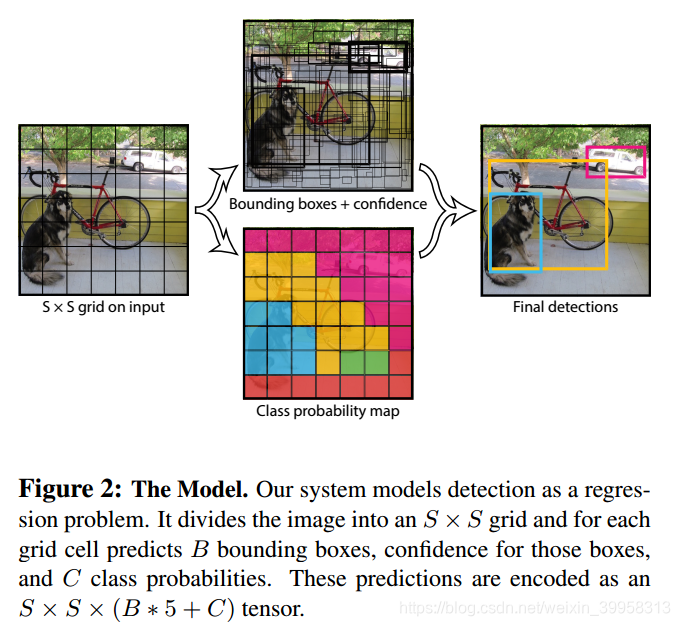
2.1 网络结构
网络有24个卷基层,连接2个全连接层。

2.2 训练
在ImageNet1000类数据集上做了预训练,使用的是Darknet。后将网络的输入分辨率从224X224变为448x448用于检测。我们通过图像宽度和高度归一化边界框的宽度和高度,使它们介于0和1之间。边界框x和y坐标参数化为特定网格单元位置的偏移,因此它们也在0和1之间。最后一层的线性激活函数及所有其它层使用一下线性激活:
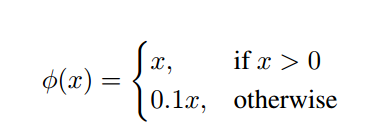
优化使用平方和误差。
损失函数:

第一项是边界框中心坐标的误差项, 指的是第 个单元格存在目标,且该单元格中的第 个边界框负责预测该目标第一项是边界框中心坐标的误差项。第二项是边界框的高与宽的误差项,其同等对待大小不同的边界框,但是实际上较小的边界框的坐标误差应该要比较大的边界框要更敏感。为了保证这一点,将网络的边界框的宽与高预测改为对其平方根的预测,即预测值变为 。。第三项是包含目标的边界框的置信度误差项。第四项是不包含目标的边界框的置信度误差项。而最后一项是包含目标的单元格的分类误差项, 指的是第 个单元格存在目标。
指的是第 个单元格存在目标,且该单元格中的第 个边界框负责预测该目标第一项是边界框中心坐标的误差项。第二项是边界框的高与宽的误差项,其同等对待大小不同的边界框,但是实际上较小的边界框的坐标误差应该要比较大的边界框要更敏感。为了保证这一点,将网络的边界框的宽与高预测改为对其平方根的预测,即预测值变为 。。第三项是包含目标的边界框的置信度误差项。第四项是不包含目标的边界框的置信度误差项。而最后一项是包含目标的单元格的分类误差项, 指的是第 个单元格存在目标。
每个单元格预测多个边界框。但是其对应类别只有一个。那么在训练时,如果该单元格内确实存在目标,那么只选择与ground truth的IOU最大的那个边界框来负责预测该目标,而其它边界框认为不存在目标。这样设置的一个结果将会使一个单元格对应的边界框更加专业化,其可以分别适用不同大小,不同高宽比的目标,从而提升模型性能。如果一个单元格内存在多个目标,Yolo算法就只能选择其中一个来训练,这也是Yolo算法的缺点之一。要注意的一点时,对于不存在对应目标的边界框,其误差项就是只有置信度,坐标项误差是没法计算的。而只有当一个单元格内确实存在目标时,才计算分类误差项,否则该项也是无法计算的。
3、性能
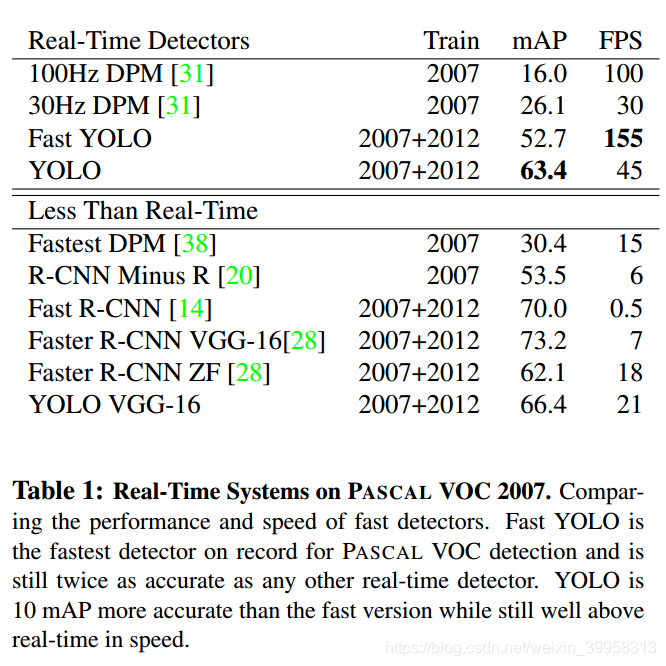

















 3377
3377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









