







 R-FCN是NIPS2016上提出的目标检测方法,它改进了Faster R-CNN,通过引入位置敏感score map来引入translation variance,从而减少非共享网络层,提高运行速度。网络使用ResNet-101作为基础,通过位置敏感score map预测ROI各区域的类别概率和边框信息。
R-FCN是NIPS2016上提出的目标检测方法,它改进了Faster R-CNN,通过引入位置敏感score map来引入translation variance,从而减少非共享网络层,提高运行速度。网络使用ResNet-101作为基础,通过位置敏感score map预测ROI各区域的类别概率和边框信息。
论文笔记:R-FCN: Object Detection via Region-based Fully Convolutional Networks
简介
本文是NIPS2016的一篇目标检测经典论文,是基于Faster RCNN的改进。
通过构建一个position sensitive score map来强行引入translation variance,从而方便整个检测过程共享更多权值。
以往的网络中,为了提高检测的精度,不可避免地增加ROI Pooling之后的非共享子网络的层数,但这大幅增加了计算量。本文认为,出现这个问题(需要靠ROI Pooling之后的层来提高准确率这个问题),主要源自于整张图像级的分类任务倾向于具有平移不变性(translation invariance ),但是在检测过程中,却需要具备一定的位置表示能力,即具有translation-variance,以便让检测的响应能反映ROI与实际物体的重叠程度。所以,本文才提出了一个位置敏感score map来引入translation-variance,从而可以在不影响精度的情况下减少ROI层之后非共享的网络,从而提高运行速度。
方法
网络结构如图所示:
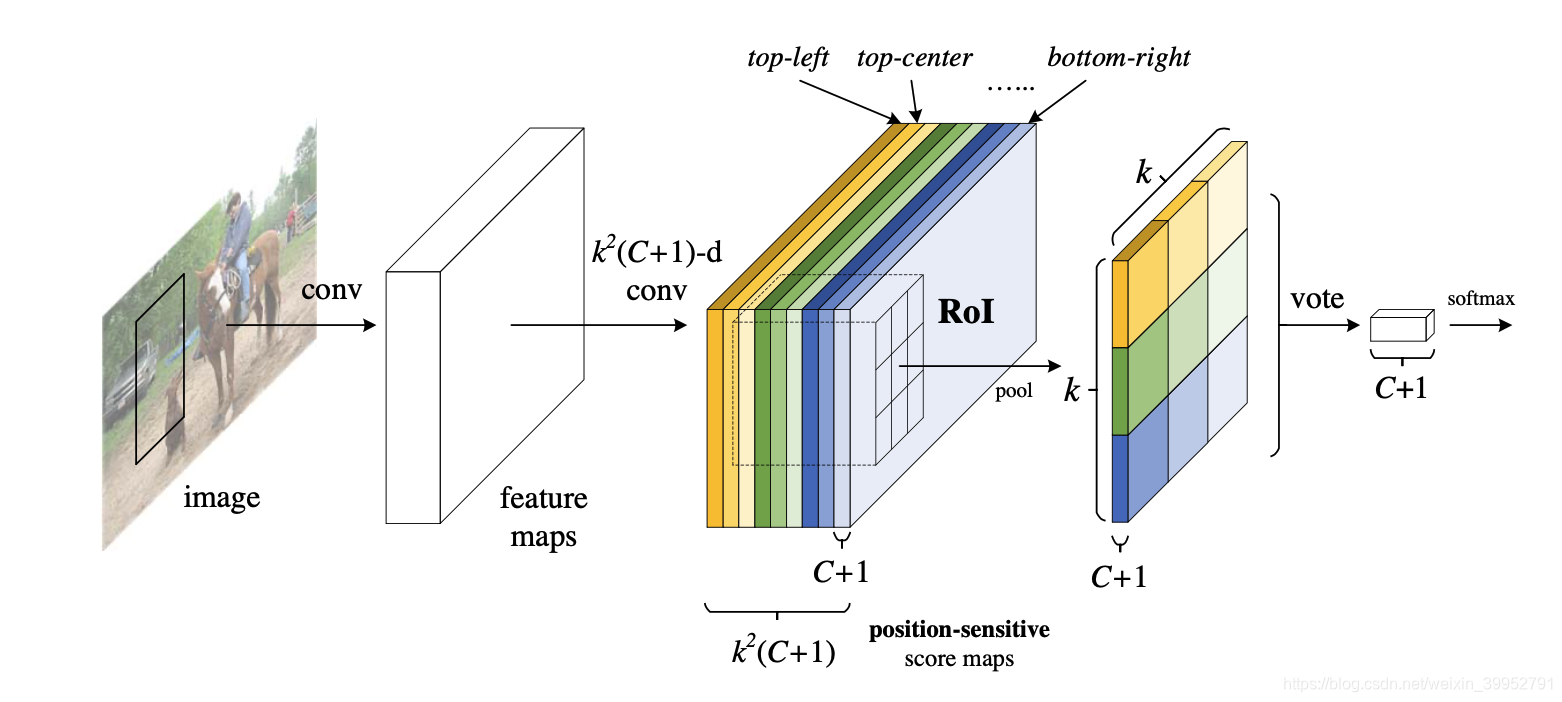
网络的骨架依然是一个全卷积网络(文中选用ResNet-101),再经过一个1x1卷积之后得到一个1024-d的特征图。对于这个特征图,通过卷积提取 k 2 ( C + 1 ) k^2(C+1) k2(C+1)-d的score maps,C+1代表C个类别和一个背景类,k2表示将ROI分成 k × k k \times k k×k个区域。对于任意一个输入的ROI,将ROI分成 k × k k \times k k×k个区域后(文中k取3),不妨以左上角的区域为例,其中一个score map只负责预测某个类别的左上角落在这个ROI左上角的可能性,k2 = 9个score maps 正好预测一个类别的左上、中上、右上、左中……9个区域落在这个ROI对应位置的概率,池化的时候也每个score map也只算自己负责的(w/k,h/k)部分的加权平均(w,k是ROI的尺寸),即:
r c ( i , j ∣ θ ) = ∑ ( x , y ) ∈ b i n ( j , j ) z i , j , c ( x + x 0 , y + y 0 ∣ θ ) / n r_c(i,j | \theta) = \sum_{(x,y) \in bin(j,j)}{z_{i,j,c}(x+x_0,y+y_0|\theta)/n}{} rc(i,j∣θ)=(x,y)∈bin(j,j)∑zi,j,c(x+x0,y+y0∣θ)/n
通过这个池化过程,每k2个通道池化成一个通道(因为score map只池化自己负责的那1/k2个ROI,每k2个score map产生一个类别的结果),总共生成了一个 ( C + 1 ) × k × k (C+1) \times k \times k (C+1)×k×k尺寸的分数图,将这个分数图的每一个通道取平均,就可以找到这个ROI对应的类别了。有了这个score maps层之后,就可以在共享的卷积层里面引入位置关系的信息了,从而在score map之后可以不再需要带权值的网络了,无论是训练过程还是测试过程都能快很多。类别判断过程如图所示:
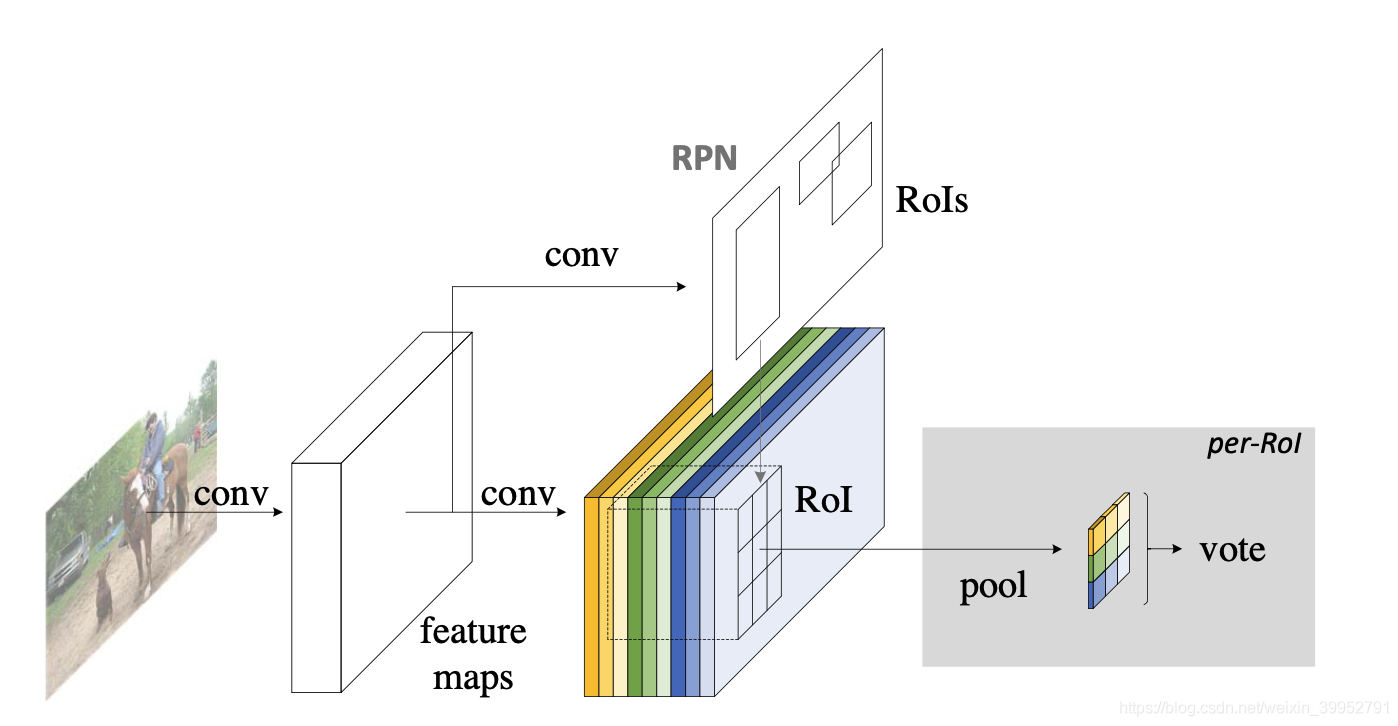
回归边框的过程同理。。在这个 k 2 ( C + 1 ) k^2(C+1) k2(C+1)旁边再加上一个4k2-d的卷积层,就可以回归出4k2的maps,将其整合成一个4-d的特征之后,就是边框的位置和尺寸信息了。
可视化过程如图所示:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









