



 OTSU算法,又称大津法,是一种用于灰度图像自动阈值选择的方法。通过最大化类间方差,找到最佳分割点将图像目标与背景分离。文章介绍了算法原理,包括概率空间、目标与背景像素比例、平均灰度值等概念,并强调了算法在双峰直方图上的良好表现,适合分割具有明显对比的图像。
OTSU算法,又称大津法,是一种用于灰度图像自动阈值选择的方法。通过最大化类间方差,找到最佳分割点将图像目标与背景分离。文章介绍了算法原理,包括概率空间、目标与背景像素比例、平均灰度值等概念,并强调了算法在双峰直方图上的良好表现,适合分割具有明显对比的图像。
OTSU学名叫做最大类间方差方法,是一个叫大津的日本人发明的,所以又叫做大津法。这个方法主要用来进行灰度图像的自动阈值查找。这里面最关键的概念应该就是类间方差。方差我们都知道,就是刻画随机向量中的所有变量和中心偏移程度的,而这个类间方差,就是在方差的基础上添加了“类间”两个字,意思就是用这个方差在目标和背景这两个类之间刻画偏移程度。
我们从应用角度来探讨一下。比如我们有一个阈值T,这个T可以对图像做二值化操作,将目标从背景中分割出来,那么这个T应该怎么查找呢?我们下面尽可能细致的介绍这个过程。
假设图像的尺寸是W*H,那么图像总点数就是W*H,也就是整个概率空间,也理解为概率全集。那么目标像素个数我们定义为n0,背景像素个数我们定义为n1,可见n0+n1 = W*H。
进一步,我们定义w0是目标像素个数占整个图像总点数的比例,即w0 = n0 / (W * H)。w1定义为背景像素个数占整个图像总点数的比例,即w1 = n1 / (W*H0),可见w0 + w1 = 1。
以上属于点数的概率定义,下面我们进行灰度值的相关定义。我们将u0定义为目标的平均灰度,也就是u0 = n0灰度值的累加值/n0,u1定义为背景的平均灰度,也就是u1= n1灰度值的累加值/n1。同样的,整个图像的平均灰度定义为u = (n0灰度值的累加值 + n1灰度值的累加值)/(W * H)。
这些概念定义完之后,我们就可以定义类间方差g = w0 * (u0 - u)^ 2 + w1 * (u1 - u)^ 2。我们的目标就是在0到255之间选择一个T,使得这个类间方差最大,具体选择方法就从0到255之间进行迭代计算,将从0到255之间的所有256个类间方差都计算出来,然后进行排序,取最大的类间方差对应的T,就是我们要求得的结果。
至此,整个算法的工作流程介绍完毕。我们能从这个算法中得到什么感悟呢?
首先就是数据层在概率论上的抽象,也就是在矩阵中应用了概率论知识。概率空间从0到255个球,每个球都一应不同的数字。然后在统计学上进行刻画:我们的目标就是将目标和背景分成两个类,并且使用方差来刻画类之间的差异,当差异最大,也就是类之间的偏离度最大的时候,也就是找到了最好的分类阈值。
最后,在工程应用中,OTSU对于灰度图像的直方图是双峰的效果较好,如果是单峰效果就不如双峰的话,如下图:
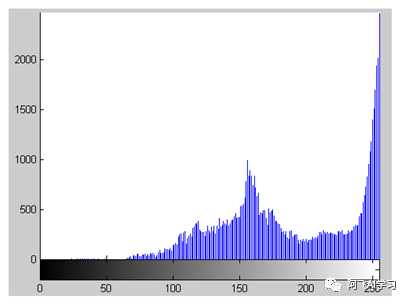
这也从另一个角度说明,数据本身有各自的属性,工具是围绕着数据进行的,不可能一种工具包打天下,每个工具都有自己的适用范围。最简单的理解就是,我们从0-255去寻找是的类间方差最大的时候,如果我们只找到一个值,并且这个值对应的类间方差和其他值对应的类间方差差别较大的时候,这个值就会将图像分割的比较好。如果我们找到一连续的值,发现这些值对应的类间方差没有什么大的区别,那说明图像本身可能就不适合用这个算法。
最典型的就是我们用这个方法来分割文本图像,比如下图:
|

分析这个图片发现,目标比例和背景基本上可以分成两类,可以推测出文本前景是一个波峰,背景是一个波峰,这样的话OTSU方法就可能适用。所以说,我们学习一个算法,一定要注意适用条件,同时分析数据本身的属性,不能就是乱套乱用,毫无章法,这样也很难形成专业的思维,长期来说,很难达到质的飞跃。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









