



在人工智能的视觉领域,CNN(卷积神经网络) 和注意力机制(如Vision Transformer)是两大主流模型。虽然注意力机制在精度上表现亮眼,但CNN在运算速度上却优势明显,尤其对实时性要求高的场景(如自动驾驶、视频分析)。这背后的核心原因究竟是什么?
一、计算复杂度:CNN线性增长 vs 注意力指数爆炸 💥
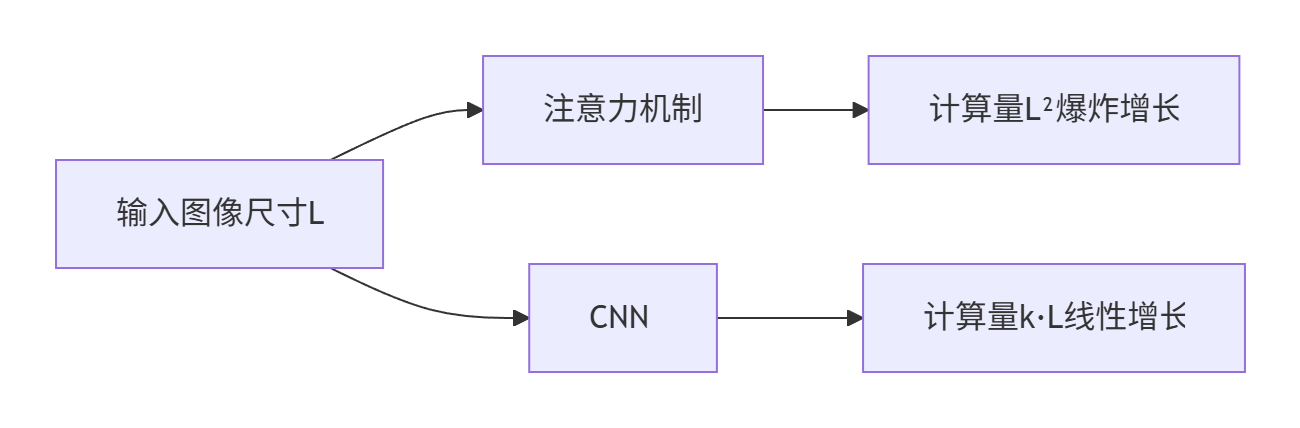
当输入图像尺寸增大时(如从1080p到4K),二者的计算量差距会急剧拉大:
| 运算类型 | 计算复杂度公式 | 举个栗子🌰 |
|---|---|---|
| 自注意力机制 | O(L² × d) | 输入尺寸L翻倍 → 计算量变4倍 |
| CNN卷积操作 | O(k × L × d) | 输入尺寸L翻倍 → 计算量只翻2倍 |
📝 注:
- L = 输入图像的像素总数(如224x224图像中 L=50,176)
- d = 特征维度
- k = 卷积核尺寸(通常3x3 → k=9,远小于L)
🔁 流程图1:计算量对比示意图
以下是针对内存访问效率部分的清晰化改写,使用更直观的比喻和结构化表述:
二、内存搬运大战:CNN的"闪电通道" VS 注意力的"跨省物流"
🐢 注意力的致命伤——数据搬出搬进
想象你网购时:
1️⃣ 要拆50,000×50,000个包裹(一张普通图像生成的中间矩阵)
2️⃣ 包裹堆满巨型仓库(HBM主存容量大但取货慢)
3️⃣ 每次只准拿1个进拆包间(SRAM缓存极小)
4️⃣ 拆1个包裹得跑10公里路(HBM读写速度比SRAM慢10+倍)
💥 结果:90%时间浪费在取/还包裹的路上!
⚡ CNN的极速秘籍——隔壁小卖部采购
3×3卷积的聪明做法:
🛒 只买邻居9个商品(访问相邻9像素)
📦 商品挤在1个小货架(数据全塞进高速SRAM)
🚚 推车直线滑动进货(规律内存访问→缓存命中率>90%)
✅ 结果:省掉99%的运输时间,全程光速计算!
💡 核心原理图解

✨ 终极结论三连击
| 对比项 | 注意力机制 | CNN | 结果差异 |
|---|---|---|---|
| 数据搬运量 | 百亿级元素反复横跳 | 9个元素原地复用 | CNN省99.9%搬运 |
| 内存路程 | 慢速HBM↹SRAM折返跑 | SRAM内部光速直达 | CNN快10+倍 |
| 访问规律性 | 随机跳转→缓存崩溃 | 直线滑动→缓存命中90% | CNN延迟降低85% |
正如搬家:
❌ 注意力 = 把全市家具运到中转站再搬回家
✅ CNN = 直接从邻居借工具用
三、附加减速器:注意力模型的"豪华配置" ⚙️
现代视觉Transformer往往引入更多设计负担:
- 🔄 窗口切分/反转(如Swin Transformer)
- 📍 复杂的位置编码模块
- 🧩 多头注意力拼接机制
这些模块像滚雪球一样累积20%以上的额外速度开销。
✅ 终极结论:为什么选CNN?
| 场景 | 推荐架构 | 原因 |
|---|---|---|
| 手机/无人机实时检测 | ✅ CNN | 毫秒级响应,省电 |
| 4K视频分析 | ✅ CNN | 避免百倍计算膨胀 |
| 服务器端高精度识别 | ⚖️ 混合 | 用注意力提精度补速度 |
✨ 技术本质总结:
CNN赢在「计算简单」+「内存友好」,犹如城市公交专用道;
注意力机制像全城出租车调度——灵活但容易堵车。
💡 拓展思考:未来会出现「快如CNN,强如Transformer」的模型吗?
(答案指向Google新作MobileViTv3、FastViT等混合架构的突破... 想看分析的请点赞!)


















 1365
1365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









