






 本文探讨了MySQL数据库的性能调优方法,包括my.ini配置参数的合理设置,以及针对拥有上亿条记录的大表进行高效查询的技术策略。通过实践案例展示了复合索引与IN操作的有效应用。
本文探讨了MySQL数据库的性能调优方法,包括my.ini配置参数的合理设置,以及针对拥有上亿条记录的大表进行高效查询的技术策略。通过实践案例展示了复合索引与IN操作的有效应用。
my.ini参数
table_cache=512
bulk_insert_buffer_size = 100M
innodb_additional_mem_pool_size=30M
innodb_flush_log_at_trx_commit=0
innodb_buffer_pool_size=207M
innodb_log_file_size=128M
innodb_flush_log_at_trx_commit默认值1的意思是每一次事务提交或事务外的指令都需要把日志写入(flush)硬盘,这是很费时的。特别是使用电 池供电缓存(Battery backed up cache)时。设成2对于很多运用,特别是从MyISAM表转过来的是可以的,它的意思是不写入硬盘而是写入系统缓存。日志仍然会每秒flush到硬 盘,所以你一般不会丢失超过1-2秒的更新。设成0会更快一点,但安全方面比较差,即使MySQL挂了也可能会丢失事务的数据。而值2只会在整个操作系统 挂了时才可能丢数据。对于事务要求很强,设置为0 是存在安全问题的
mysql创建表
CREATE TABLE `news` (
`id` int(19) NOT NULL AUTO_INCREMENT,
`title` varchar(30) DEFAULT NULL,
`content` varchar(400) DEFAULT NULL,
`type` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `PK_NEWS_ID` (`id`),
KEY `INDEX_NEWS_ID_TYPE` (`id`,`type`),
KEY `INDEX_NEWS_TYPE` (`type`)
) ENGINE=InnoDB AUTO_INCREMENT=1072779 DEFAULT CHARSET=utf8
java插入测试数据代码放到文章最后面
mysql5.5 支持 insert into mytable value (xxx,xxx....),(xxx,xxx....)...........插入多条记录,相比addBatch 好不到哪里,而且mysql数据包有限制,超大字符串对JVM也很难消受
查询随着select字段增多会消耗更多时间,limit a,b 也会随着a的增大而加大查询时间。
现在数据已经添加到了至少6200万条数据,
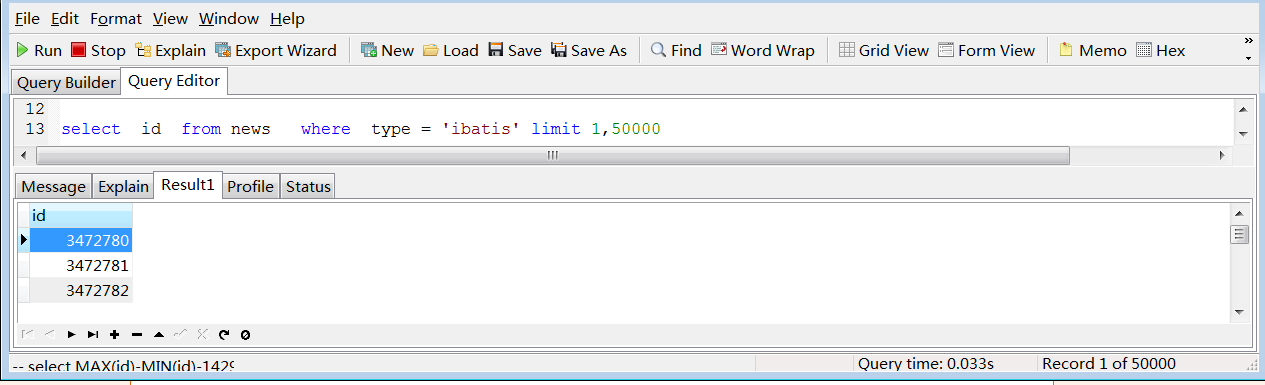
in的速度是惊人的
可见复合索引带来性能的优势
这个表大约是6200万条记录,综合一下2个最重要的速度最快查询就是分页的查询语句
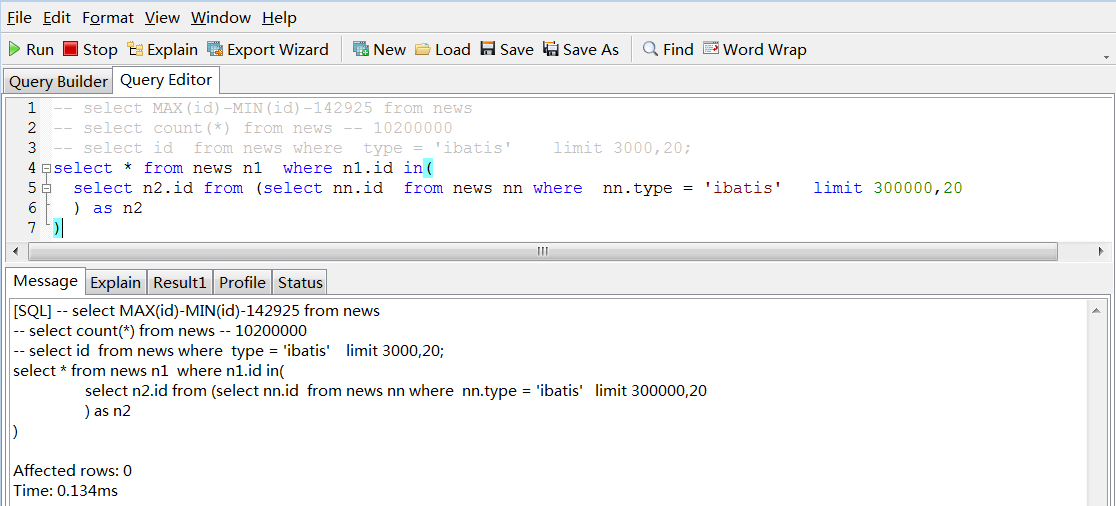
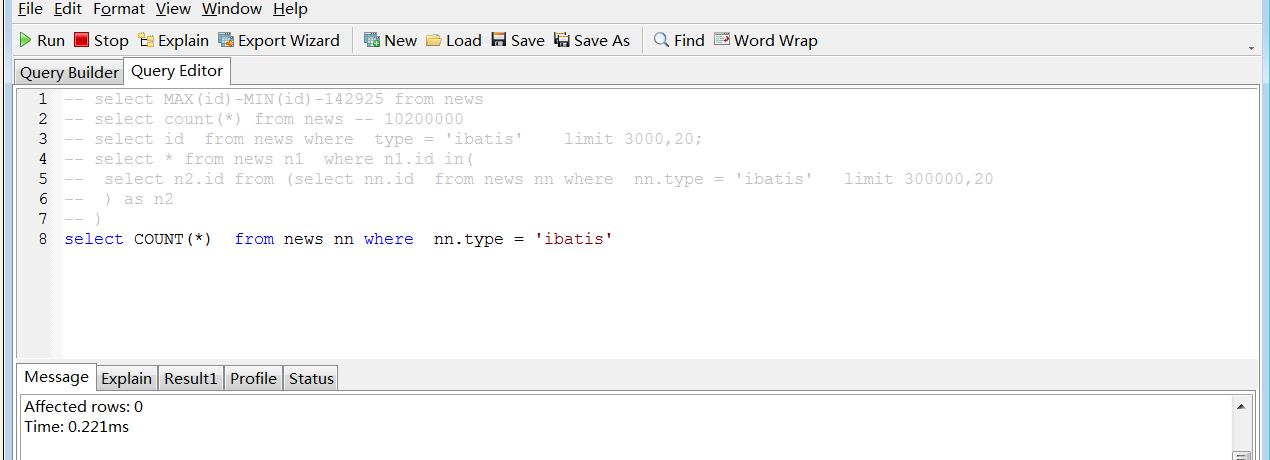
大表查询总结: 1 复合索引好好使用 2 in 要好好使用
上面的都是传统分页的,分页做下改进
1 当页面传到controller层有一个page对象,代表要查询的页数,那么我们的sql可以随着变化
start=(page-1)*pagesize+1 然后是where做限制 就是where加上 id >= start
如果表中增加了一个type='ios8' 因为ios8 的数据是从三千多万多条开始的,假设是32888888条记录,后面才增加type='ios8'的记录,那么分页就可以加上 id >= start + 32888888
2 对于新闻类,老的数据分页是固定的,所以可以分表,新闻就要新闻
所以最新的新闻的分页好办,表里面弄几百页就够了,其他的数据放到一个老数据表里面,老数据表的存储引擎改成MyISAM
比如前500页就查询news的数据,后面的就查询oldnews1,oldnews2.....表的数据,对old表做一下策略每个old表的一种分类只允许有100000页的数据。
假设oldnew1表,是数据里面最先入进去的,是知道id的范围的,但是oldnews1表分页的页数是会变的
我们在老数据表每个表里面都增加一个page字段,存储页数,由于页数是会变动的,所以我们需要页码字段和数据倒着来,那么插入的时候就不会改动前面的页码的,我们知道有多少个老表。假设有10个老表
limit a,b,那么a就会大于 (news表的总页数*pagesize-news表的总条数+ 9*100000*pagesize),查询页码的时候就需要-100000+1,因为页码字段是倒着来的.
3 上面分表+页码策略做的话性能会明显的提升很多,但是表中有大字段而且字段超多始终会对性能产生影响,老新闻是不变的,可以做静态化处理,我们新增一个路径表urloldnew1,.....,只给一个id,page,url即可,查询的时候就用这样就可以让表的数据字段大大减少,不去查询老的原始数据表。
url是生成的静态文件地址,这需要静态化的时候进行二次加密,根据文件路径生成 加密码,然后根据加密码生成静态路径。
4 下面对单条新闻设计。
查询单条新闻:
看到的类似于 www.myblog.com/s/blog_s897yu_99uiiu_s7yht.html
这是经过加密的,后台要解密前台传递过来的字符串
如jkser896 _ 89hhgii _ oiy67hjk
根据字段表再次解密 java开发者 _ /news/old8/ 1243546678
这样拼接路径就成了。
最后把java插入测试数据放到附件里
---- 数据已经增加到了一个亿多,分页查询性能丝毫不减,Mysql竟然如此精悍
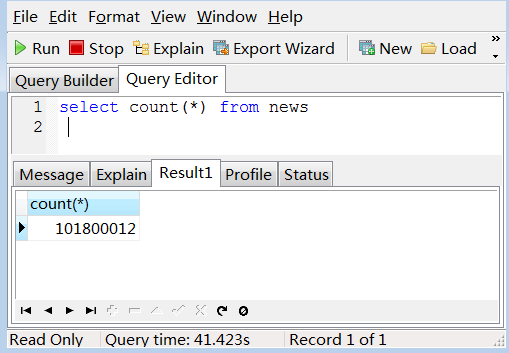
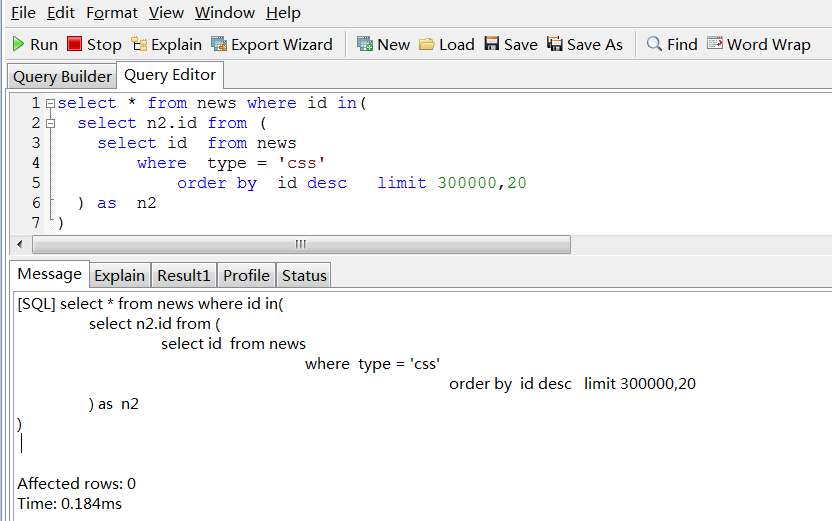
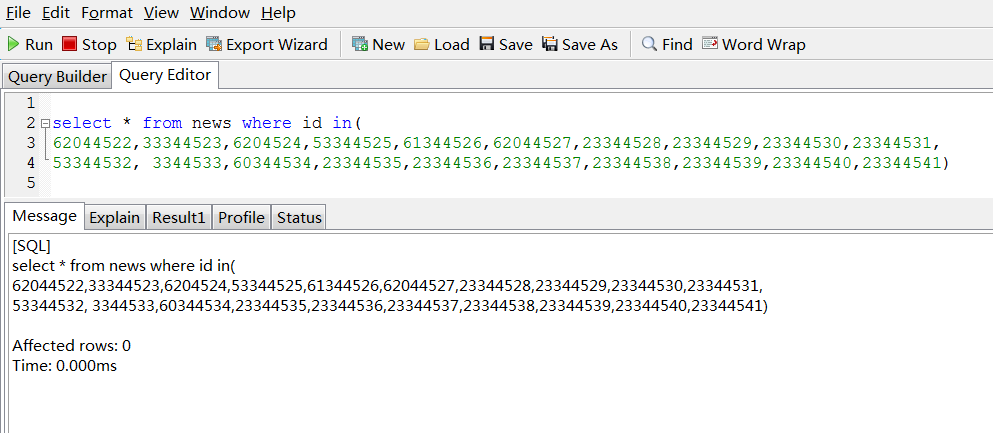
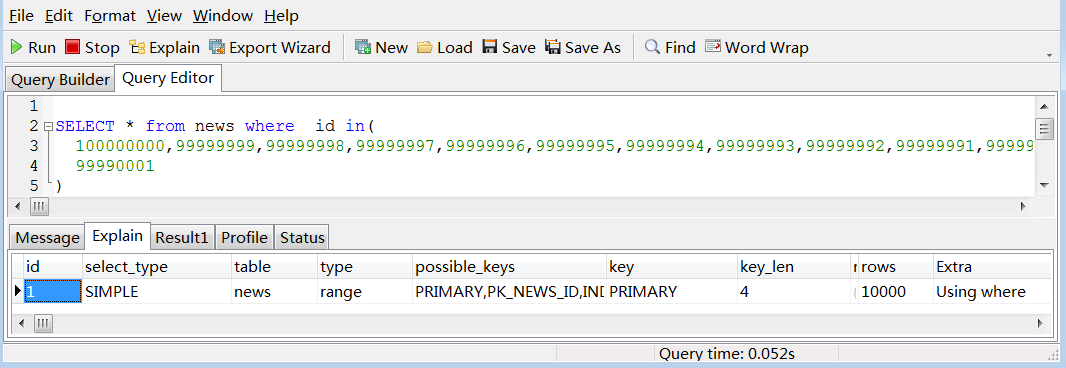
听大婶们说in不走索引的啊,看看大婶们对吗?in里面放一万个

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









