






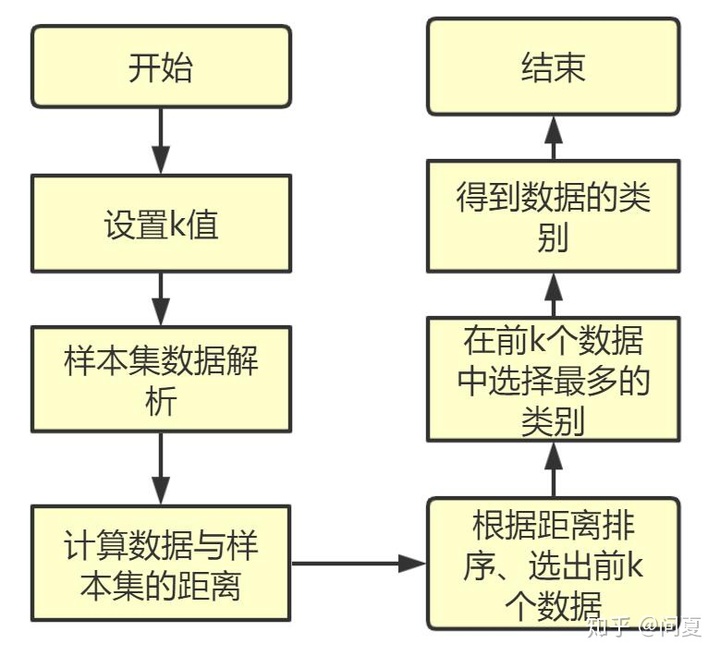
一、KNN算法简介
KNN算法,最大K近邻算法。是一种分类算法,原理较为简单。所谓k近邻,指在某种计算距离的函数下,最近的k个数据,通过此来分类未知类别。
算法思想:对于某一个未知类别,通过计算其与已知数据集的距离,然后进行排序,选出最近的k个数据,根据这些数据的类别,在其中选择出现最多的类别,即作为这个未知数据的类别,完成分类。
算法优缺点及适用范围
| 优点:精度高、对异常值不敏感、无数据输入假定 |
| 缺点:计算复杂度高、空间复杂度高、效率较低 |
| 适用性:数值型和标称型 |
参考博客
Python3《机器学习实战》学习笔记(一):k-近邻算法(史诗级干货长文)_Jack-Cui-优快云博客_python3机器学习实战blog.youkuaiyun.com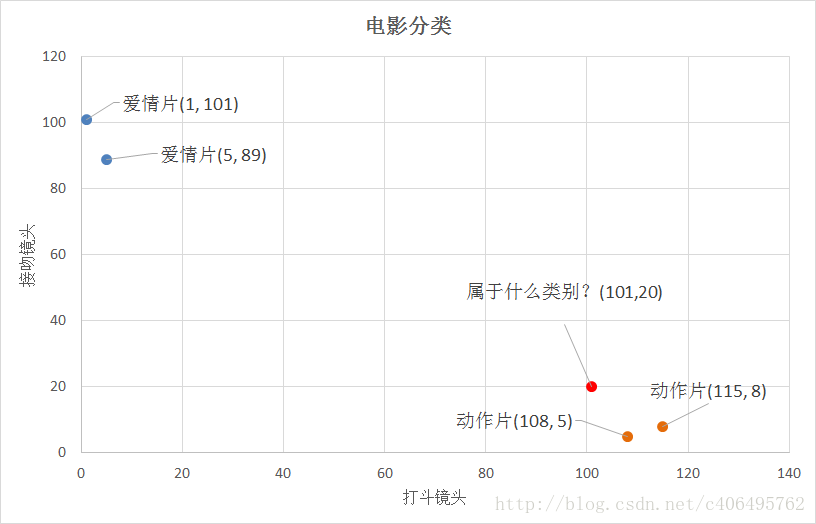
二、实战案例一:电影片分类
这是《机器学习实战》中的一个案例:已知某样本电影的打斗画面和接吻画面个数,根据已有数据集,进行分类。我们使用KNN算法,通过比较其与已知数据集的欧式距离,设定合适的k(根据数据集的大小和数据特征而定),进行分类排序,选出最接近的,作为样本类别。
import numpy as np
import operator
def createdateset():
group = np.array([[1,101],[5,89],[108,5],[115,8]])
labels = ['爱情片',"爱情片","动作片","动作片"] #
return group,labels
#inX表示输入的样本,dateSet表示训练样本集,labels是样本标签,k是近邻个数
def classfy_film(inX,dateSet,lables,k):
dateSetSize=dateSet.shape[0]
diffMat=np.tile(inX,(dateSetSize,1))-dateSet #tile(A,(B,C))函数,复制矩阵为B行,C重复列
sqDiffMat=diffMat**2
#sum(0)为列相加,sum(1)为行相加
sqDistences=sqDiffMat.sum(axis=1)
distances=sqDistences**0.5
sortedDistences=distances.argsort() #排序得到索引,默认从小到大
classCount={}
for i in range(k): #i=0
voteIlabel = labels[sortedDistences[i]] #得到最近的类别的标签放在voteIlabel中
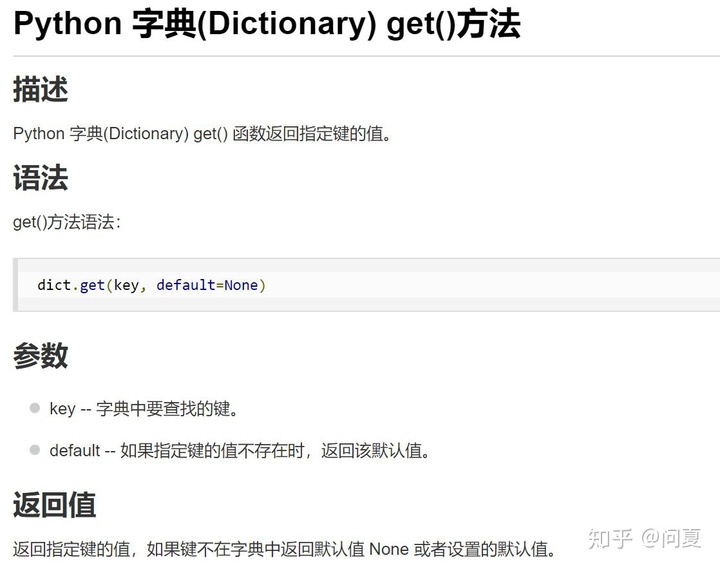
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1
#key=operator.itemgetter(1)按值排序
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0] #得到最前排序的类别
if __name__ =='__main__':
group,labels=createdateset()
test = [101,20]
test_class=classfy_film(test,group,labels,3)
print(test_class)利用到python的几个库函数,具体如下:

三、实战案例二:约会网站配对效果判定
算法过程类似,只不过需要对数据进行处理,数据为txt文本,需要用到python中的函数进行解析,解析代码如下:
def file2matrix(filename):
#打开文件
fr = open(filename)
#读取文件所有内容
arrayOLines = fr.readlines()
#得到文件行数
numberOfLines = len(arrayOLines)
#返回的NumPy矩阵,解析完成的数据:numberOfLines行,3列
returnMat = np.zeros((numberOfLines,3))
#返回的分类标签向量
classLabelVector = []
#行的索引值
index = 0
for line in arrayOLines:
#s.strip(rm),当rm空时,默认删除空白符(包括'n','r','t',' ')
line = line.strip()
#使用s.split(str="",num=string,cout(str))将字符串根据't'分隔符进行切片。
listFromLine = line.split('t')
#将数据前三列提取出来,存放到returnMat的NumPy矩阵中,也就是特征矩阵
returnMat[index,:] = listFromLine[0:3]
#根据文本中标记的喜欢的程度进行分类,1代表不喜欢,2代表魅力一般,3代表极具魅力
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index += 1
return returnMat, classLabelVector
#最后得到两个矩阵,一个是约会数据矩阵,一个是数据标签矩阵数据可视化,用到matplotlib.pyplot包,这里我们用到的是散点图scatter,设置合理的标轴标签和图例
#画出散点图,以datingDataMat矩阵的第一(飞行常客例程)、第二列(玩游戏)数据画散点数据,散点大小为15,透明度为0.5
axs[0][0].scatter(x=datingDataMat[:,0], y=datingDataMat[:,1], color=LabelsColors,s=15, alpha=.5)
#设置标题,x轴label,y轴label
axs0_title_text = axs[0][0].set_title(u'每年获得的飞行常客里程数与玩视频游戏所消耗时间占比',FontProperties=font)
axs0_xlabel_text = axs[0][0].set_xlabel(u'每年获得的飞行常客里程数',FontProperties=font)
axs0_ylabel_text = axs[0][0].set_ylabel(u'玩视频游戏所消耗时间占',FontProperties=font)
plt.setp(axs0_title_text, size=9, weight='bold', color='red')
plt.setp(axs0_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs0_ylabel_text, size=7, weight='bold', color='black')
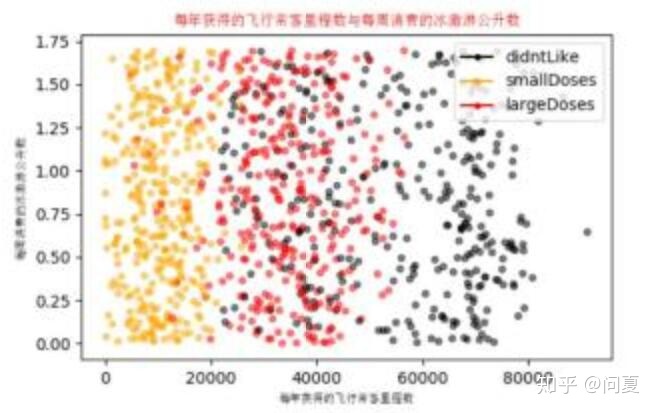
#画出散点图,以datingDataMat矩阵的第一(飞行常客例程)、第三列(冰激凌)数据画散点数据,散点大小为15,透明度为0.5
axs[0][1].scatter(x=datingDataMat[:,0], y=datingDataMat[:,2], color=LabelsColors,s=15, alpha=.5)
#设置标题,x轴label,y轴label
axs1_title_text = axs[0][1].set_title(u'每年获得的飞行常客里程数与每周消费的冰激淋公升数',FontProperties=font)
axs1_xlabel_text = axs[0][1].set_xlabel(u'每年获得的飞行常客里程数',FontProperties=font)
axs1_ylabel_text = axs[0][1].set_ylabel(u'每周消费的冰激淋公升数',FontProperties=font)
plt.setp(axs1_title_text, size=9, weight='bold', color='red')
plt.setp(axs1_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs1_ylabel_text, size=7, weight='bold', color='black')
#设置图例
didntLike = mlines.Line2D([], [], color='black', marker='.',
markersize=6, label='didntLike')
smallDoses = mlines.Line2D([], [], color='orange', marker='.',
markersize=6, label='smallDoses')
largeDoses = mlines.Line2D([], [], color='red', marker='.',
markersize=6, label='largeDoses')
#添加图例
axs[0][0].legend(handles=[didntLike,smallDoses,largeDoses])
axs[0][1].legend(handles=[didntLike,smallDoses,largeDoses])
axs[1][0].legend(handles=[didntLike,smallDoses,largeDoses])
#显示图片
plt.show()最后结果展示图
数据使用时需要进行归一化:若不进行归一化,数值之间的差异,导致某类过大的数据会影响其他数据的有效性。例如神经网络拟合时,可能有使某个参数系数过大,导致欠拟合。
四、sklearn机器学习算法包
重要参数
- n_neighbors:默认为5,就是k-NN的k的值,选取最近的k个点。
- weights:默认是uniform,参数可以是uniform、distance,也可以是用户自己定义的函数。uniform是均等的权重,就说所有的邻近点的权重都是相等的。distance是不均等的权重,距离近的点比距离远的点的影响大。用户自定义的函数,接收距离的数组,返回一组维数相同的权重。合理设置weigths可以降低异常数据的干扰。
设置合理的参数,能够大大提高算法的准确度
#构建KNN分类器
neigh = kNN(n_neighbors = 3, algorithm = 'auto')
#拟合模型, trainingMat为测试矩阵,hwLabels为对应的标签
neigh.fit(trainingMat, hwLabels)加州大学欧文学院机器学习数据集仓库
UCI Machine Learning Repositoryarchive.ics.uci.edu里面有大量关于机器学习的数据集,通过ctrl+f进行搜索需要的数据

















 4727
4727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









