





测试数据如下:
A B D
B C
C A B
D B C注意:第一列与第二列之间是制表符't',第二列与第三列之间是空格符
需求:ABCD分别代表4个网页,计算其入链权重(PR)排名网页的顺序。
网页之间的关系图如下:
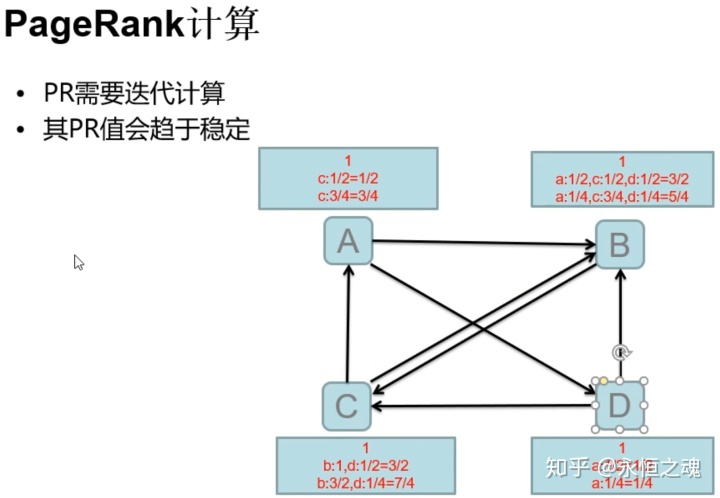
算法原理:


首先,先创建一个Node类来封装每行数据,代码如下:
package hadoop.mr;
import org.apache.commons.lang.StringUtils;
import java.io.IOException;
import java.util.Arrays;
public class Node {
private double pageRank = 1.0;
private String[] adjacentNodeNames;
private static final char fieldSeparator = 't';
public double getPageRank() {
return pageRank;
}
public Node setPageRank(double pageRank) {
this.pageRank = pageRank;
return this;
}
public String[] getAdjacentNodeNames() {
return adjacentNodeNames;
}
public Node setAdjacentNodeNames(String[] adjacentNodeNames) {
this.adjacentNodeNames = adjacentNodeNames;
return this;
}
public boolean containAdjacentNodes(){
return adjacentNodeNames!=null&&adjacentNodeNames.length>0;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(pageRank);
if (getAdjacentNodeNames()!=null){
sb.append(fieldSeparator).append(StringUtils.join(getAdjacentNodeNames(),fieldSeparator));
}
return sb.toString();
}
public static Node fromMR(String value) throws IOException{
//将value按制表符进行切割
String[] parts = StringUtils.splitPreserveAllTokens(value,fieldSeparator);
//value为空将报异常
if (parts.length<1){
throw new IOException("Expected 1 or more parts but received"+parts.length);
}
//将1或者后面的0.3这样数赋值pageRank并返回对象
Node node = new Node().setPageRank(Double.valueOf(parts[0]));
if(parts.length>1){
//将B D做成一个数组放到对象中
node.setAdjacentNodeNames(Arrays.copyOfRange(parts,1,parts.length));
}
return node;
}
public static Node fromMR(String v1,String v2) throws IOException{
return fromMR(v1+fieldSeparator+v2);
}
}
然后创建Job类:
package hadoop.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class RunJob {
public static enum MyCounter{
my
}
public static void main(String[] args) {
Configuration conf = new Configuration();
//如果分布式运行,必须打成jar包
//且client在集群外非hadoop.jar这种方式运行,client中必须配置jar的位置
//下面这行是hadoop2.5后出现的,默认为false,如果想运行在window系统中,需要设置为true
conf.set("mapreduce.app-submission.corss-platform","true");
//这个配置,只属于切换分布式到本地单进程模拟运行的配置
//这种方式不是分布式,所以不用打jar包。
conf.set("mapreduce.","local");
double d = 0.001;
int i = 0;
while (true){
i++;
try{
conf.setInt("runCount",i);
FileSystem fs = FileSystem.get(conf);
Job job = Job.getInstance(conf);
job.setJarByClass(RunJob.class);
job.setJobName("pr"+i);
job.setMapperClass(PageRankMapper.class);
job.setReducerClass(PageRankReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//这是帮忙做切割,按制表符,制表符前面的就是key,后面的是value
job.setInputFormatClass(KeyValueTextInputFormat.class);
//数据的输入分两种,第一次是原始数据,从input拿,后面都是从上一次输出拿,即上一次的输出是下一次的输入
Path input = new Path("/data/pagerank/input");
if (i>1){
input = new Path("/data/pagerank/output/pr"+(i-1));
}
FileInputFormat.addInputPath(job,input);
//输出
Path output = new Path("/data/pagerank/output/pr"+i);
if (fs.exists(output)){
fs.delete(output,true);
}
FileOutputFormat.setOutputPath(job,output);
boolean f = job.waitForCompletion(true);
if (f){
System.out.println("success");
//数据处理成功后拿被my标识的值,实际就是pr的差值
long sum = job.getCounters().findCounter(MyCounter.my).getValue();
System.out.println(sum);
double avgd = sum/4000.0;
if (avgd<d){
break;
}
}
}catch (Exception e){
e.printStackTrace();
}
}
}
private static class PageRankMapper extends Mapper<Text,Text,Text,Text>{
@Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
//从配置文件中取runCount的值,在客户端中已经配过,是i的值,这里如果取不到,就等于1返回
int runCount = context.getConfiguration().getInt("runCount",1);
//第一次A B D
//第二次A 0.3 B D
String page = key.toString();//KEY就是A这个位置的值
Node node = null;
if (runCount==1){
//如果是第一次,给一个1+'t'+B D
node = Node.fromMR("1.0",value.toString());
}else {
node=Node.fromMR(value.toString());
}
//toString的结果是1.0+'t'+B+'t'+D
context.write(new Text(page),new Text(node.toString()));
//假如数组不为空且长度不为零时结果为真
if(node.containAdjacentNodes()){
double outValue = node.getPageRank()/node.getAdjacentNodeNames().length;//看有几个入链,平均分
for (int i = 0;i<node.getAdjacentNodeNames().length;i++){
String outPage = node.getAdjacentNodeNames()[i];
context.write(new Text(outPage),new Text(outValue+""));//结果就是B 0.5 D 0.5
}
}
}
}
private static class PageRankReducer extends Reducer<Text,Text,Text,Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//进来的数据有两种
double sum = 0.0;
Node sourceNode = null;
for (Text i : values) {
Node node = Node.fromMR(i.toString());
if (node.containAdjacentNodes()){
//第一种:对应关系的数据
sourceNode = node;
}else {
//第二种:就是B 0.5的这种数据
sum = sum + node.getPageRank();
}
}
double newPR = (0.15/4)+(0.85*sum);//套用公式(1-d)+d*到改页面的入链值和d为0.85的阻尼系数,谷歌给的值,n是页面数
System.out.println("***********new pageRank value is"+newPR);
double d = newPR - sourceNode.getPageRank();
int j = (int)(d*1000.0);
//相差的值可能是负数,这里给它取了绝对值
j=Math.abs(j);
System.out.println(j+"--------------------------");
//将差值存放到配置文件中,因为整个过程在循环中,方法读取进行比较
context.getCounter(MyCounter.my).increment(j);
sourceNode.setPageRank(newPR);
context.write(key,new Text(sourceNode.toString()));
}
}
}
















 3347
3347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









