






“给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,如果这k个实例的多数属于某个类,就把该输入实例分给这个类。”
K近邻算法英文全称为K-nearest neighbor(简称KNN),顾名思义,就是找出与输入样本最近的那个分类的邻居。KNN是一种基本的,用于分类与回归问题的方法。本文只讨论分类问题。
著名的鸭子测试中有一句流传甚广的话,“如果它看起来像鸭子,游泳像鸭子,叫声像鸭子,那么它可能就是只鸭子。” 这句话与KNN算法的核心思想不谋而合。
KNN的算法步骤一般而言是这样的:
- 在训练数据集X_train中,对输入的实例x,计算每一组样本到x的距离。
- 对这些距离进行排序,取出离x最近的k个样本。
- 取出这k个样本中占比最多的类别,并认为x属于这一类。
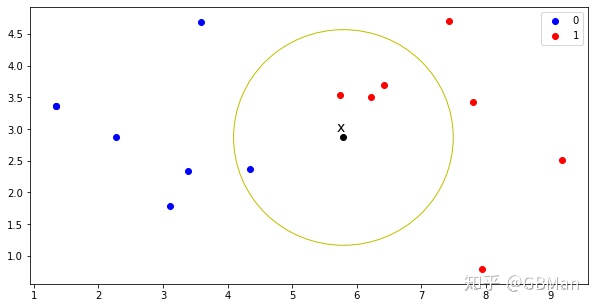
如图所示,当输入实例x时,我们先计算x到训练数据集X_train每一个样本点的距离,然后对这些距离进行从近到远(顺序)排序,并取出离x最近的k个点,图中可以看出k=4,并且在这4个点中(即黄圈中的点)有3个属于1类,有1个属于0类,因此我们使用“少数服从多数”的原则,认为x属于1类。
重点:
KNN中一个重要的超参数就是k值,k值不同可能带来的分类结果也十分不同。
此外,KNN另一个重要超参数是距离的度量,计算距离的公式主要有欧氏距离、闵氏距离、曼哈顿距离和切比雪夫距离等。
具体差别如下:

这里我们使用欧氏距离:
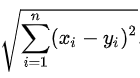
Python代码实现
# 引入numpy科学计算库和Python内置库collections.Counter
import numpy as np
from collections import Counter
x = np.array([5.7, 2.8])
# 计算x到训练数据集X_train各点的欧氏距离
distance = [np.sqrt(np.sum((x_train - x) **2)) for x_train in X_train ]
# 对distance中的距离索引进行顺序排序
indexes = np.argsort(distance)
# 映射到这些点的类型
nearest = y_train[indexes]
# 取出前k个种类,这里设k=4
topK_y = nearest[:4]
# 对topK_y中的类型进行投票,看看哪种类型占比最多
c = Counter(topK_y)
# 返回和x最接近的点的标签
c.most_common()[0][0]至此,简单的KNN算法已经完成了。我们稍微进行一下封装:
import numpy as np
from collections import Counter
def KNN_classify(x,X_train,y_train,k):
"""使用断言对输入的参数进行判断。"""
assert 1 <= k <= X_train.shape[0], "k must be valid"
assert X_train.shape[0] == y_train.shape[0],
"the size of X_train must equal to the size of y_train"
assert X_train.shape[1] == x.shape[0],
"the feature number of x must equal to X_train"
distance = [np.sqrt(np.sum((x_train - x)**2)) for x_train in X_train]
nearest = np.argsort(distance)[:k]
topK_y = y_train[nearest]
votes = Counter(topK_y).most_common()[0][0]
return votes
















 537
537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









