




 探讨C++中写时复制技术原理及其优化,利用代理模式解决内存管理问题。
探讨C++中写时复制技术原理及其优化,利用代理模式解决内存管理问题。
C++学习笔记(十二)——写时复制(代理模式的一个示例)
本篇任务有:
- 什么是写时复制;
- 写时复制存在的利弊;
- 改善写时复制——代理模式的一个示例;
什么是写时复制
通过代码和其显示结果来了解什么是写时复制,实例代码如下(代码12-1):
///
/// @file cowString1.cc
/// @author XuHuanhuan(1982299154@qq.com)
/// @date 2019-02-23 16:44:42
///
#include <stdio.h>
#include <iostream>
#include <string>
using std::cout;
using std::endl;
using std::string;
int main()
{
string pstr1 = "hello";
string pstr2 = pstr1;
string pstr3 = pstr2;
string pstr4 = pstr2;
String pstr5 = "hello";//他的地址与pstr1,pstr2,pstr3,pstr4不相同。
cout << "写时复制现象" << endl;
cout << "写时复制现象->写之前地址相同" << endl;
printf("pstr1 = %p\n", pstr1.c_str());//采用cout << pstr1.c_str() << endl;打印字符串
printf("pstr2 = %p\n", pstr2.c_str());//采用cout << &(pstr1.c_str()) << endl;报错
printf("pstr3 = %p\n", pstr3.c_str());//采用cout << pstr1 << endl;打印字符串
printf("pstr4 = %p\n", pstr4.c_str());//采用cout << &pstr1 << endl;打印的地址不一样,因为他们属于同一个类的不同的对象,所以地址不同
printf("pstr4 = %p\n", pstr5.c_str());//采用cout << &pstr1 << endl;
cout << "写时复制现象->写之后地址不相同" << endl;
pstr4[0] = 'X';
printf("pstr4 = %p\n", pstr4.c_str());
return 0;
}
结果如下(图11-1):
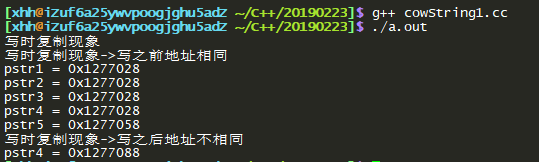
分析打印的结果,可以看到String类型的pstr1,pstr2,pstr3,pstr4在没有改变字符串的内容时,他们的地址是相同的。也就是说pstr1,pstr2,pstr3,pstr4他们指向的地址相同。当我对pstr4做改动之后,pstr4的指向发生了改变。总结这种现象特点就是:==多个String类型的字符串赋予相同地址的字符常量时,这些指针的指向同一个地址。只有当某个指向该字符串的某个变量发生改变时,该变量才会发生复制操作,而指向另外一个地址。==为了解释的更加清楚,作图如下:
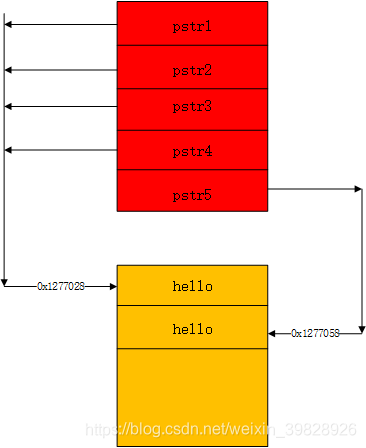 (图11-2)
(图11-2)
上图是在pstr4改变值之前的进程空间的部分示意图。红色部分为栈空间,黄色部分为可读写字符串空间。经过赋值操作之后各个指针的示意图就如上所示。
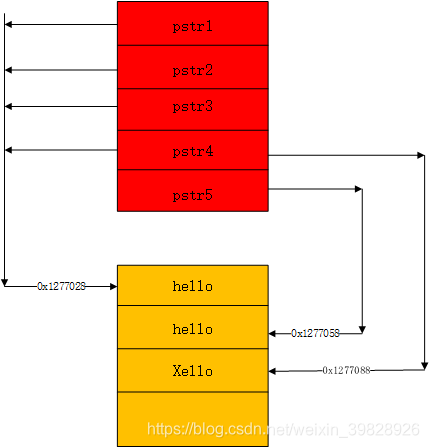
(图11-3)
但是,当pstr4的值发生改变时,计算机内发生的步骤为:将地址为0x1277028的hello复制到0x1277088上→修改h为X。
写时复制存在的利弊
写时复制的好处在于其大大减少了进程运行所需要的内存空间,提高了程序的写效率。但是它的缺点也同样的致命。示例代码如下(代码12-2):
///
/// @file cowbug.cc
/// @date 2019-02-24 14:02:00
///
#include <stdio.h>
#include <string.h>
#include <iostream>
using std::cout;
using std::endl;
class String
{
public:
String()
{};
String(const char * pstr)
:_pstr(new char[strlen(pstr)+1]())
{
strcpy(_pstr, pstr);
}
void getString(const char * pstr)
{
_pstr = new char[strlen(pstr)+1]();
strcpy(_pstr, pstr);
}
void putString()
{
cout << "String: " << _pstr << endl;
}
void putPoint()
{
printf("%p\n", _pstr);
}
~String()
{
delete [] _pstr;
}
private:
char * _pstr;
};
int main()
{
String str1("hello");
String str2 = str1;
String str3 = str2;
str1.putPoint();
str2.putPoint();
str3.putPoint();
return 0;
}
结果如下所示(图12-4):
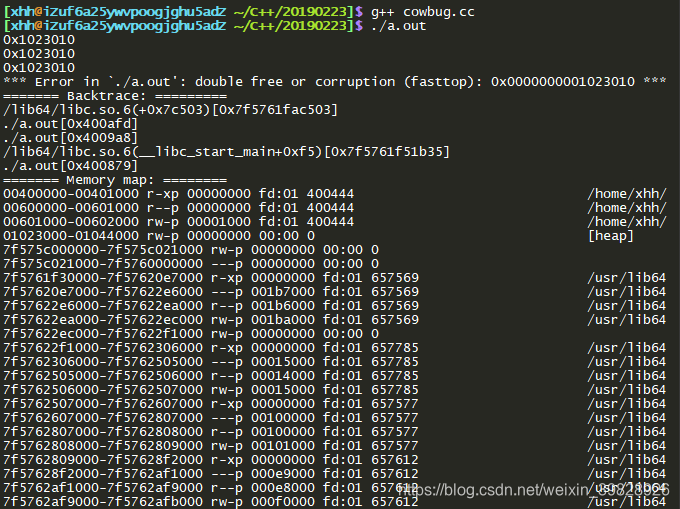
前三行结果可以看出,str1,str2,str3指向了相同的地址,也就是说其采用的策略就是写时复制。但是后面却出现了报错。错误原因在于堆空间的多次free(double free)。这就是写时复制所制造出来的bug。
改善写时复制——代理模式的一个示例
写时复制可以提高写效率并且大大减少了进程的运行所占内存,但是却带来了double free问题。那么如何改进写时复制来避免double free呢?通过上面的代码我们可以看出解决问题的关键在于一下几点:
- 对于赋值(删除)操作:
- 只能有一个对象执行析构函数,且该对象在执行析构函数前其他对象都不存在了;
- 需要对该类创建了多少对象进行计数,所以需要重载一些函数和运算符; - 对于修改操作:
- 修改前需要复制字符串,并且重置计数位;
- 修改相应的值
为了解决这个问题,这里提出一种较为合理含有计数位的字符串模型。如下图所示(图12-5):
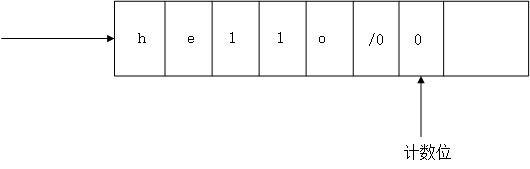
图为再堆空间上存储的一个字符串。该字符串有别于一般的字符串。他的结尾/0后面还多了一位计数位。这个计数位就是用来标记有多少个对象指向了该字符串。所以,对析构函数的改进就是判断计数位是否为1,当计数位为1的时候就执行delete操作。当计数位大于1的时候就不执行delete操作。这样就可以避免double free问题了。
对于修改操作,这相对复杂一些。这个内容要结合代码才能看出来。下面给出改善后的写时复制代码示例(代码12-3)如下:
///
/// @file cowString.cc
/// @author XuHuanhuan(1982299154@qq.com)
/// @date 2019-02-22 13:25:05
///
#include <stdio.h>
#include <string.h>
#include <iostream>
using std::cout;
using std::endl;
class cowString{
class CharPaxy{ //注意如果下面的代码有要使用该嵌套类的操作时,必须要把该嵌套类放到上面,不然编译报错。
public:
CharPaxy(cowString & str, size_t idx)//const cowString & str加上一个const为什么不对??
:_str(str)
,_idx(idx)
{}
operator char()
{
if(_idx >= 0 && _idx < strlen(_str._pstr))
return _str._pstr[_idx];
else
cout << "访问越界" << endl;
return _str._pstr[_str.size()];
}
cowString & operator=(const char ch)
{
if(_idx >= 0 && _idx < strlen(_str._pstr))
{
if(_str.Count() > 1)
{
char * temp = new char[strlen(_str._pstr)+2]();
strcpy(temp, _str._pstr);
_str.decrCount();
_str._pstr = temp;
_str.initCount();
}
_str._pstr[_idx] = ch;
}
return _str;
}
private:
cowString & _str; //两个疑问:一、为什么是cowString 类型? 二、为什么要有&?
size_t _idx;
};
public:
cowString()
:_pstr(new char[2])
{
initCount();
}
cowString(const char * pstr)
:_pstr(new char[strlen(pstr) +2])
{
strcpy(_pstr,pstr);
initCount();
}
cowString(const cowString & hs)
{
_pstr = hs._pstr;
incrCount();
}
/* cowString & operator=(const char * pstr)
{
_pstr= new char[strlen(pstr)+3]();
strcpy(_pstr, pstr);
initCount();
return *this;
}
*/
cowString & operator=(const cowString & cowstr)
{
_pstr = cowstr._pstr;
incrCount();
return *this;
}
size_t size() const
{
return strlen(_pstr);
}
size_t Count() const
{
return _pstr[size()+2];
}
CharPaxy operator[](size_t idx)
{
return CharPaxy(*this, idx);
}
private:
friend std::ostream & operator<<(std::ostream & os, cowString & cowstr);//为什么要有3个&:前两个是由于流不能复制,最后一个&是因为在函数传参时
//用到了复制构造函数,这个时候为了避免调用复制构造函数,就必须要使用&(应用)
void initCount()
{
_pstr[size()+2] = 1;
}
void incrCount()
{
++_pstr[size()+2];
}
void decrCount()
{
--_pstr[size()+2];
}
char * _pstr;
};
std::ostream & operator<<(std::ostream & os, cowString & cowstr)
{
os << cowstr._pstr;
return os;
}
int main()
{
cowString cowstr1();
cowString cowstr2 = "hello";
cowString cowstr3("world");
cowString cowstr4(cowstr2);
cout << "cowstr = " << cowstr2 << " link num: " << cowstr2.Count() << endl;
cout << "cowstr = " << cowstr3 << " link num: " << cowstr3.Count() << endl;
cout << "cowstr = " << cowstr4 << " link num: " << cowstr4.Count() << endl;
cout << "cowstr = " << cowstr2 << " link num: " << cowstr2.Count() << endl;
cout << "cowstr = " << cowstr2 << " link num: " << cowstr2.Count() << endl;
cout << "cowstr = " << cowstr2 << " link num: " << cowstr2.Count() << endl;
cout << "////测试[]和=的重载效果(一)////////" << endl;
cowString cowstr5("world");
cowString cowstr6(cowstr5);
cout << "cowstr = " << cowstr5 << " link num: " << cowstr5.Count() << endl;
cout << "cowstr = " << cowstr6 << " link num: " << cowstr6.Count() << endl;
cowstr6[0] = 'X';
cout << "cowstr5 = " << cowstr5 << " link num: " << cowstr5.Count() << endl;
cout << "cowstr6 = " << cowstr6 << " link num: " << cowstr6.Count() << endl;
cout << "cowstr6[0] = " << cowstr6[0] << " link num: " << cowstr6.Count() << endl;
cout << "////测试[]和=的重载效果(二)////////" << endl;
cowString cowstr7("world");
cowstr7[0] = 'G';
cout << "cowstr7[0] = " << cowstr7[0] << " link num: " << cowstr7.Count() << endl;
return 0;
}
这段代码非常值得水平一般的人研究。通过cowString类(没有里面的嵌套类CharPaxy)就可以就可以避免double free问题。但是,当对该字符串做修改时,仅需用cowString类是无法满足要求的。难点在于:
char ch1 = cowstr1[0];与cowstr1[0] = 'X'这两个操作无法只使用[]重载函数就能做出区分,还需要重载=函数;char ch1 = cowstr1[0];与cowstr1[0] = 'X'这两个操作对[]重载函数的返回值有不同的要求,char ch1 = cowstr1[0];要求[]重载函数的返回值为字符型,cowstr1[0] = 'X'并不要求[]重载函数有返回值。
这两大难点可以通过代理模式来解决。问题的关键在于:[]的重载函数即要有返回值,还要能够与=重载函数结合时处理cowString类对象所以[]的重载函数的返回值不能是一般的char类型。而是能够满足上述要求的高级char类型(CharPaxy)。==将char类型的功能做了延申后代替char类型实现功能的设计称之为代理模式。==对CharPaxy的设计如下:
1、要实现的目标:
a>、能够在cowString的对象调用[]时存储该对象和下标;
b>、能够在该对象调用=时做出正确的写时复制功能;
c>、该对象还能够自动返回char类型的字符;
对应的实现是能够看代码了,其他的多说了也没用。不过还需要注意的几点就是:cowString调用[]之后(例如:cowString cowstr1("hello"); cowstr1[0]= 'N';)的cowstr1[0]就不再是cowString的对象了,而是CharPaxy类的实例。所以cowString & operator=(const char ch);必须得是CharPaxy的成员函数;CharPaxy & operator[](size_t idx);必须得是cowString的成员函数,且其返回值必须是CharPaxy(不然cowstr1[0]无法使用CharPaxy的cowString & operator=(const char ch);成员函数了)。其中细节都在代码中体现,这里不再多说。

















 2871
2871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









