



 本文介绍如何使用MATLAB进行简单的网页爬取工作,包括发送HTTP请求获取HTML内容、使用正则表达式提取所需数据及将提取结果保存到本地文件。
本文介绍如何使用MATLAB进行简单的网页爬取工作,包括发送HTTP请求获取HTML内容、使用正则表达式提取所需数据及将提取结果保存到本地文件。
总览
% 获取目标url的html字符串
详细步骤
第一步, 对目标url发送请求,使用webread函数(不推荐用urlread函数)
使用webread函数的格式:
html = webread(url, options);其中,options是我们自己设置的参数
>>%查看默认参数
>>weboptions
ans =
weboptions - 属性:
CharacterEncoding: 'auto'
UserAgent: 'MATLAB 9.7.0.1190202 (R2019b)'
Timeout: 5
Username: ''
Password: ''
KeyName: ''
KeyValue: ''
ContentType: 'auto'
ContentReader: []
MediaType: 'auto'
RequestMethod: 'auto'
ArrayFormat: 'csv'
HeaderFields: []
CertificateFilename: 'default'
修改参数
options = weboptions('Timeout', inf);
% 这里我们修改了timeout为inf,也就是不限制超时强制停止获取网页的html数据
url='www.baidu.com';
html = webread(url, options)这些有很多”<>”的就是html类型的数据,
第二步, 使用正则表达式来获取数据
- 2.1正则表达式是什么
如果你不了解正则表达式,可以看看这篇文章
路路了吧:(转)Matlab 正则表达式零基础zhuanlan.zhihu.com正则表达式中有一些字符并不代表本来的意思,而是有其他含义, 比如英文句号( . )在正则中不会找到目标字符串中的句点, 而是会匹配一个除换行符外的任意字符:
str1 = 'abcadcafghica cda@c';
key1 = 'a.c';
findall_1 = regexpi(str1, key1, 'match')
findall_1 =
1x4 cell 数组
{'abc'} {'adc'} {'a c'} {'a@c'}如果你想匹配一个句点,你须要在句点前加一个反斜杠:
key='a.c'限于篇幅, 这些特殊字符的详细的介绍放在文末的附录中.
- 2.2获取数据
比如我们要找到html中的所有网页链接:
key = 'http://.*?.com';%问号代表最多匹配一次.如果你好奇不加问号会怎么样,就试试吧
findalls = regexpi(html, key, 'match');
>> findalls(1)
ans =
1x1 cell 数组
{'http://s1.bdstatic.com'}第三步, 把数据保存到txt中
% 打开文件, ‘w’代表以只写模式打开, 这种模式下, 如果没有找到文件, 就会自动创建, 如果有文件, 就会覆盖之前的文件
file = fopen('D:test.txt','w');
% 用fprintf函数把数据写入文件(cell数据是不能直接写入的, 要用cell2mat转化为字符串)
fprintf(file, '%s', cell2mat(findalls));
% 关闭文件, 不然不会保存
fclose(file);完整代码
clc, clear all
url='http://www.baidu.com';
options = weboptions('Timeout', inf);
html = webread(url, options);
key = 'http://.*?.com';
findalls = regexpi(html, key, 'match');
file = fopen('D:test.txt','w');
for i_ = 1:length(findalls)
% 把cell数据转化为字符串
each = cell2mat(findalls(i_));
fprintf(file, '%s', each);
% 加一个换行(n)不然会全部挤在一起
fprintf(file, 'n%s', '');
end
fclose(file);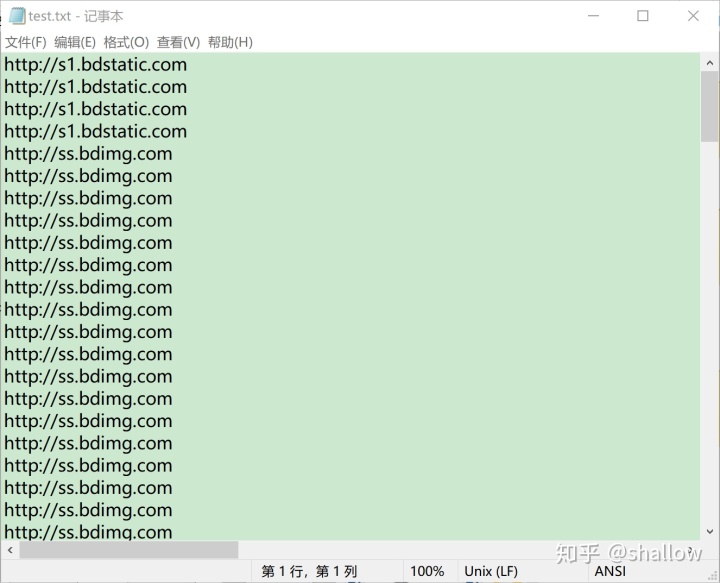
附录:正则表达式中的特殊字符
将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用或一个八进制转义符。例如,'n' 匹配字符 "n"。'n' 匹配一个换行符。序列 '' 匹配 "" 而 "(" 则匹配 "("。^ 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性 ^ 也匹配 'n' 或 'r' 之后的位置。$ 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性 $ 也匹配 'n' 或 'r' 之前的位置。* 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。 * 等价于{0,}。+ 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。? 匹配前面的子表达式零次或一次。例如, "do(es)?" 可以匹配 "do" 或 "does" 中的"do" 。? 等价于 {,1}。? 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配单个 "o",而 'o+' 将匹配所有 'o'。. 匹配除 "n" 之外的任何单个字符。要匹配包括 'n' 在内的任何字符,请使用象 '[.n]' 的模式。(x|y) 匹配 x 或 y。例如,'z|food' 能匹配 "z" 或 "food"。 '(z|f)ood' 则匹配 "zood" 或 "food"。[xyz] 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中 的 'a'。[^xyz] 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中 的'p'。[a-z] 字符范围。匹配指定范围内的任意字符。例如,'[a-z]' 可以匹配 'a' 到 'z' 范围内的任意小写字母字符。[^a-z] 负值字符范围。匹配任何不在指定范围内的任意字符。例如,'[^a-z]' 可以匹配任何不在 'a' 到 'z' 范围内的任意字符。[1-8] 数字范围。匹配指定范围内的任意字符。例如,'[1-8]' 可以匹配 '1' 到 '8' 范围内的任意数字字符。[1-5a-ex] 1-5或a-e或x{n} n 是一个非负整数。匹配确定的 n 次。例如, 'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。请注意在逗号和两个数之间不能有空格。{n,} n 是一个非负整数。至少匹配 n 次。例如, 'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。 'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。{,n} n 是一个非负整数。至多匹配 n 次{n,m} m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。b 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'erb' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。B 匹配非单词边界。'erB' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。cx 匹配由 x 指明的控制字符。例如, cM 匹配一个 Control-M 或回车符。 x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。d 匹配一个数字字符。等价于 [0-9]。D 匹配一个非数字字符。等价于 [^0-9]。f 匹配一个换页符。等价于 x0c 和 cL。n 匹配一个换行符。等价于 x0a 和 cJ。r 匹配一个回车符。等价于 x0d 和 cM。s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ fnrtv]。S 匹配任何非空白字符。等价于 [^ fnrtv]。t 匹配一个制表符。等价于 x09 和 cI。v 匹配一个垂直制表符。等价于 x0b 和 cK。w 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。W匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。xn 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,'x41' 匹配 "A"。'x041' 则等价于 'x04' & "1"。正则表达式中可以使用 ASCII 编码。.num匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,'(.)1' 匹配两个连续的相同字符。n 标识一个八进制转义值或一个向后引用。如果 n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义 值。nm标识一个八进制转义值或一个向后引用。如果 nm 之前至少有 nm 个获得子表 达式,则 nm 为向后引用。如果 nm 之前至少有 n 个获取,则 n 为一个后跟 文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 nm 将匹配八进制转义值 nm。nml 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进 制转义值 nml。un匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, u00A9 匹配版权符号 (?)。

















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









