









目录
一、机器学习的分类
分类:识别某个对象属于哪个类别,常用的算法有:SVM(支持向量机)、nearest neighbors(最近邻)、random forest(随机森林),常见的应用有:垃圾邮件识别、图像识别。
回归:预测与对象相关联的连续值属性,常见的算法有:SVR(支持向量机)、 ridge regression(岭回归)、Lasso,常见的应用有:药物反应,预测股价。
聚类:将相似对象自动分组,常用的算法有:k-Means、 spectral clustering、mean-shift,常见的应用有:客户细分,分组实验结果。
降维:减少要考虑的随机变量的数量,常见的算法有:PCA(主成分分析)、feature selection(特征选择)、non-negative matrix factorization(非负矩阵分解),常见的应用有:可视化,提高效率。
模型选择:比较,验证,选择参数和模型,常用的模块有:grid search(网格搜索)、cross validation(交叉验证)、 metrics(度量)。它的目标是通过参数调整提高精度。
预处理:特征提取和归一化,常用的模块有:preprocessing,feature extraction,常见的应用有:把输入数据(如文本)转换为机器学习算法可用的数据。
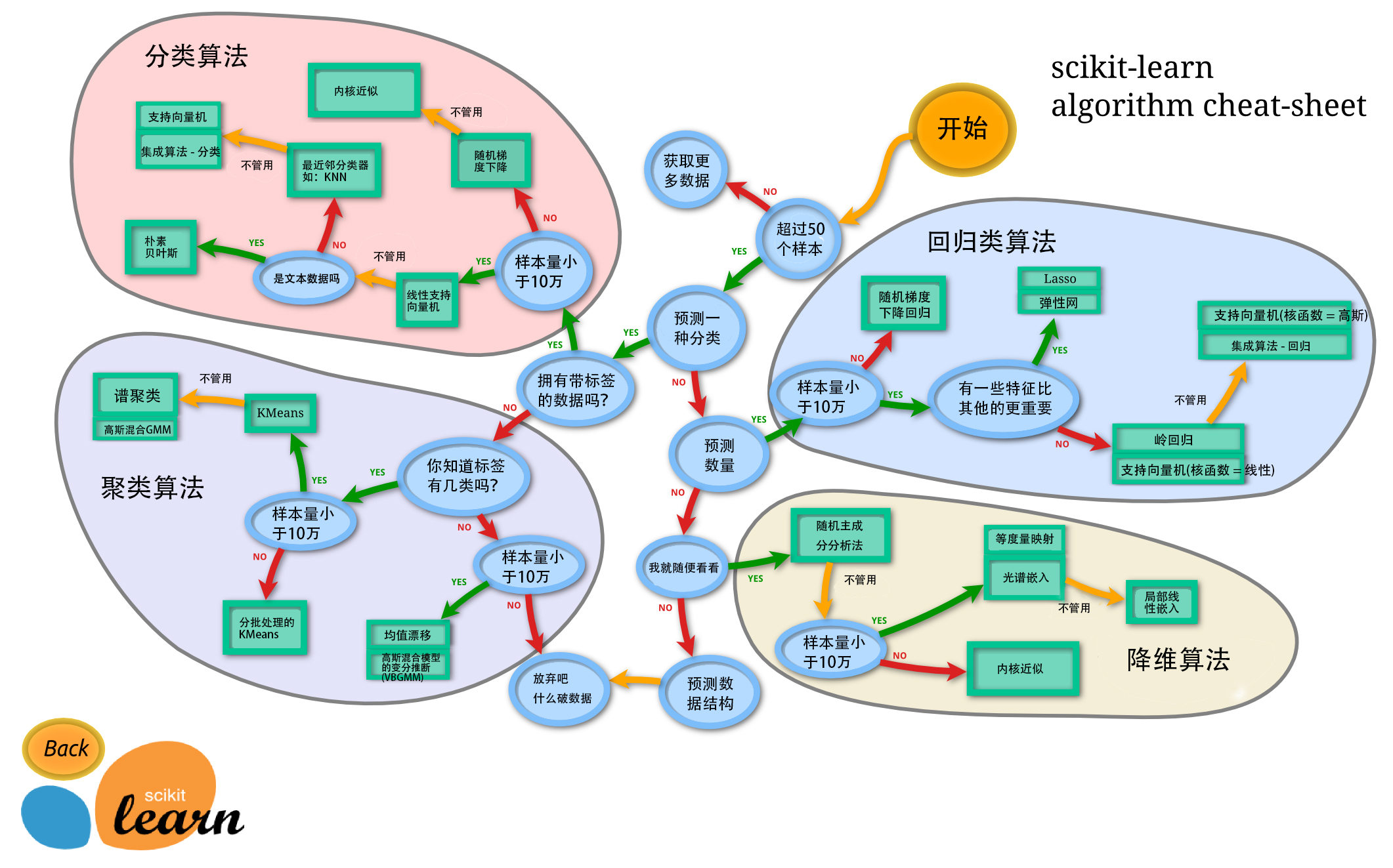
二、具体实例:
#随机森林分类
#训练模型,保存模型
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_wine
import pandas as pd
import pickle
from joblib import dump, load
wine = load_wine()
Xtrain,Xtest,Ytrain,Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
dtc = RandomForestClassifier()
result = dtc.fit(Xtrain,Ytrain)
# score = result.score(Xtest,Ytest)
# pred = result.predict(Xtest)
# print(Ytest,pred,score)
dump(dtc, 'D:\\sklearn-test\\dtc.pkl')#也可以使用文件对象
#逻辑回归处理红酒数据集的分类
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression as LR
from sklearn.metrics import accuracy_score
import pandas as
wine = load_wine()
Xtrain,Xtest,Ytrain,Ytest = train_test_split(wine.data,wine.target,test_size=0.3,random_state=100)
lr = LR(class_weight='balanced')
lr = lr.fit(Xtrain,Ytrain)
yp = lr.predict_proba(Xtest)
ypred = lr.predict(Xtest)
score = lr.score(Xtest,Ytest)
score
#xgboost实现红酒数据集的分类
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 准确率
import xgboost as xgb # 引入工具库
import pandas as pd
wine = load_wine()
Xtrain,Xtest,Ytrain,Ytest = train_test_split(wine.data,wine.target,test_size=0.3,random_state=100)
# read in data
dtrain = xgb.DMatrix(Xtrain,label=Ytrain) # XGBoost的专属数据格式,但是也可以用dataframe或者ndarray
dtest = xgb.DMatrix(Xtest) # # XGBoost的专属数据格式,但是也可以用dataframe或者ndarray
# specify parameters via map
params = {
'booster': 'gbtree',
'objective': 'multi:softmax',
'num_class': 3,
'gamma': 0.1,
'max_depth': 6,
'lambda': 2,
'subsample': 0.7,
'colsample_bytree': 0.75,
'min_child_weight': 3,
'silent': 0,
'eta': 0.1,
'seed': 1,
'nthread': 4,
}
plst = list(params.items())
num_round = 2 # 使用线程数
bst = xgb.train(plst, dtrain, num_round) # 训练
# make prediction
preds = bst.predict(dtest) # 预测
accuracy = accuracy_score(Ytest,preds)
accuracy
#支持向量机实现红酒数据集的分类
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 准确率
from sklearn.svm import SVC # 引入工具库
import pandas as pd
import matplotlib.pyplot as plt
wine = load_wine()
Xtrain,Xtest,Ytrain,Ytest = train_test_split(wine.data,wine.target,test_size=0.3,random_state=100)
clf = SVC(kernel='linear',gamma='auto')
clf = clf.fit(Xtrain,Ytrain)
ypred = clf.predict(Xtest)
ypred[ypred==2]
#神经网络实现红酒数据集的分类
from sklearn.neural_network import MLPClassifier as DNN
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 准确率
from sklearn.svm import SVC # 引入工具库
import pandas as pd
import matplotlib.pyplot as plt
wine = load_wine()
Xtrain,Xtest,Ytrain,Ytest = train_test_split(wine.data,wine.target,test_size=0.3,random_state=100)
s = []
for i in range(100,2000,100):
dnn = DNN(hidden_layer_sizes=(int(i),),random_state=420).fit(Xtrain,Ytrain)
s.append(dnn.score(Xtest,Ytest))
print(i,max(s))
plt.figure(figsize=(20,5))
plt.plot(range(100,2000,100),s)
plt.show()调用模型:
#调用模型,预测
from joblib import dump, load
from sklearn.datasets import load_wine
wine = load_wine()
data = wine.data
target = wine.target
dtc = load('D:\\sklearn-test\\dtc.pkl')
dtc.score(data,target)三、学习笔记总结:
(1)、数据预处理:
- 无量钢化:preprocessing.MinMaxScaler(数据归一化,压缩数据在一定的范围内)和StandardScaler(数据标准化,按照均值和方差处理数据),优先考虑StandardScaler数据标准化
- 用labelcoder处理标签的值为0,1
- 用describe查看数据的偏态(如果你发现出现的异常值,要看异常值的频率,
- 频度少应该是人为造成的,频度多需要找业务人员交流清楚,如果异常值超过了10%
- 这份数据就不能用了)
- 先处理困难特征,填补缺失值再进行后续的处理
- 用的SVM算法,不同的核函数,linear线性核函数,rbf高斯径向基核函数
(2)、线性回归(岭回归,Lasso):
- r2 r_score、均方误差
- TSS=RSS+ESS
- 正则化系数(可以降低过拟合)、最少二乘法
- 正则化路径eps
(3)、逻辑回归:
- 预测概率的效果非常好
(4)、xgboost:
- 不断的迭代树,后一棵树在前一棵树的基础上迭代
- subsample数据的抽取比例
四、有助于学习的网站:
(1)机器学习集成学习之XGBoost(基于python实现) - 知乎
(2)Kaggle: Your Machine Learning and Data Science Community
(3)天猫天池大数据竞赛:


















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









