






全网首个Π0仿真与实物复现方案
01
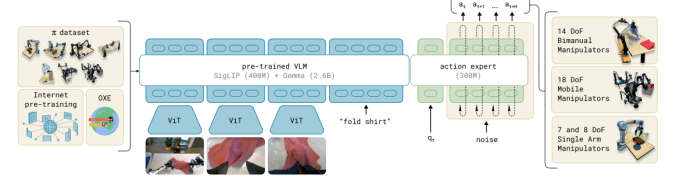
Π0的模型架构与训练策略
1.引入预训练的视觉-语言模型(VLM):
通过使用预训练的 VLM,模型导入了互联网规模的通用知识,继承了语言和视觉-语言模型的语义推理和问题解决能力。对于π的基础模型 VLM——PaliGemma,它本身并不直接输出动作。那怎么让它生成动作呢?具体而言,作者团队在PaliGemma后面接一个专门的动作模块
2.扩展为视觉-语言-动作模型(VLA):
在基础的视觉-语言模型上进一步训练,整合机器人动作数据,将模型扩展为一个视觉-语言-动作(VLA)模型。
3.跨化身训练:
为了利用不同类型的机器人数据,采用跨化身训练(Cross-EmbodimentTraining),将多种机器人类型的数据合并到同一个模型中。这些机器人具有不同的配置空间和动作表示,包括:
▪ 单臂系统
▪ 双臂系统
▪ 移动操纵器
4.动作分块架构与流匹配:
使用带有流匹配的动作分块架构来表示复杂的连续动作分布,以支持高度灵巧和复杂的物理任务。
02
Π0训练策略
1.预训练阶段:
模型在一个非常大且多样化的语料库上进行预训练,获取通用的知识和能力。
2.微调阶段:
在更狭窄且经过精心策划的数据集上对模型进行微调,引导出所需的行为模式,提升对具体任务的适应能力。
03
复现基于的开源代码和仿真平台
GitHub - EDiRobotics/mimictest: A simple testbed for robotics manipulation policies
是一个基于RoboMimic的机器人操作策略的简单测试平台,所有策略都以简单的方式重新编写,基于RoboSuite模拟器。效果如下:
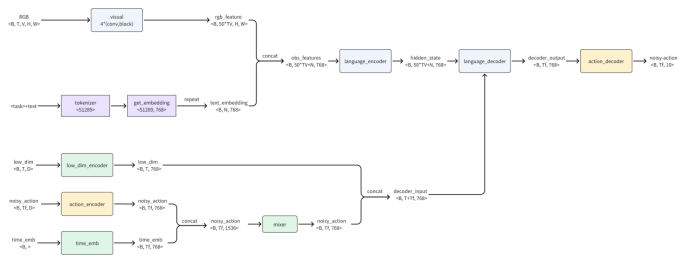
代码结构图
主文件FlowFlorencePi0ImageMimic.py
引入预训练的视觉-语言模型(VLM):
model_path = Path("microsoft/Florence-2-base")
freeze_vision_tower = True
加载模型 Florence-2-base 作为视觉特征提取器,并且设置 freeze_vision_tower=True,即冻结视觉塔的参数,避免在训练过程中更新该部分参数。
扩展为视觉-语言-动作模型(VLA):
diffuser_solver = "flow_euler"
这部分设置了扩散模型的v求解方法(flow_euler)
net = FlorencePi0Net(
path=model_path,
freeze_vision_tower=freeze_vision_tower,
num_actions=num_actions_6d,
lowdim_obs_dim=lowdim_obs_dim,
).to(device)
policy = DiffusionPolicy(
net=net,
loss_configs=loss_configs,
do_compile=do_compile,
scheduler_name=diffuser_solver,
num_train_steps=diffuser_train_steps,
num_infer_steps=diffuser_infer_steps,
ema_interval=ema_interval,
beta_schedule=beta_schedule,
clip_sample=clip_sample,
prediction_type=prediction_type,
)
这部分设置配置了整个网络
Π0主网络函数:FlorencePi0Net.py
| Plain Text |
功能:这是模型的主结构类,继承自 nn.Module,并初始化了一个预训练的因果语言模型(Causal Language Model),即 AutoModelForCausalLM。它通过加载一个预训练模型(Florence)来进行视觉-语言联合学习。
原理:加载一个预训练的模型作为视觉特征提取器,并根据 freeze_vision_tower 参数来决定是否冻结视觉塔(vision tower)的参数。如果冻结,模型不会在训练过程中更新视觉塔的权重。
| Plain Text |
功能:这里加载了 Florence 模型的处理器(AutoProcessor),并通过 tokenizer 处理输入的 <Action> 标签,作为模型的一个输入提示。prompt_embeds 将 <Action> 转换为嵌入向量,并将其作为固定参数,不在训练过程中更新。
| Plain Text |
功能:这一部分定义了多个层,用于处理低维观测(lowdim_obs_dim)和动作信息(num_actions),并将它们编码为模型可以理解的输入格式:
○ low_dim_encoder 将低维观测映射到与模型语言层(token_dim)相同的维度。
○ action_encoder 将动作空间的输入编码为 token_dim 维度的向量。
○ action_timestep_mixer 是一个多层感知机(MLP),用于对动作和时间步进行融合,并生成合适的表示。
○ action_decoder 将 decoder 输出的特征重新映射回动作空间。
○ time_emb 使用之前定义的正弦位置嵌入来处理时间步信息。
DiffusionPolicy函数:DiffusionPolicy.py
| Plain Text |
添加噪声:根据 loss_configs 配置的类型(diffusion 或 flow),为输入数据添加噪声。这模拟了扩散过程的正向过程,其中数据被逐步扰动。
对于 diffusion,调用 add_noise 方法将噪声添加到输入数据。
对于 flow,调用 scale_noise 方法将噪声按比例缩放。
04
仿真与实物训练过程中的问题
梯度爆炸问题:训练中梯度爆炸了,可以通过调小学习率来解决。
实物数据处理与频率问题:数据处理没什么大问题,关键是采集频率与推理频率要接近,差距太大会影响效果。
文本加载问题:文本数据太长会导致加载卡住,原因尚未仔细分析。
Warmup调整:之前使用基于epoch的warmup,现在改成按iter来调整。观察到loss下降更平滑,但是否有效还不确定。之前仿真中有梯度爆炸问题,但认为调整后可能不再影响。
评估次数对训练的影响:仿真中训练比较平滑,但在真机上观察到抖动现象。排除推理逻辑的问题后,单纯的模型输出也有类似问题,看起来像是模型在预测过程中无法准确判断前后顺序(例如:前进过程中突然后退)
05
加入Π0复现小组
你有兴趣加入Π0模型复现小组吗,加入后可以与其他成员互相讨论Π模型的复现进展,分享代码和数据。加入的前提是你已经跑通了仿真代码,并且拥有实物机器人。接下来小组将重点解决一些工程问题,如机器人控制过程中的抖动问题、加入lerobot框架、预训练数据量不足的问题,以及强化学习微调等问题。如果你有兴趣加入,可以联系木木。
参考文档
基础理论:https://blog.youkuaiyun.com/v_JULY_v/article/details/143472442?spm=1001.2014.3001.5501
实操代码:https://github.com/EDiRobotics/mimictest/blob/main/mimictest/Scripts/RobomimicExperiments/FlowFlorencePi0ImageMimic.py

















 1573
1573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









