









开头先附上scrapy框架学习的视频传送门:2018年最新Python3.6网络爬虫实战
再附上:Scrapy中文手册 与 Scrapy英文文档
1.在项目文件夹下创建一个新的scrapy项目,名为‘samzhu’
scrapy startproject samzhu2.在项目文件夹下会出现如下文件
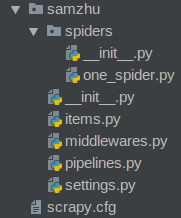
scrapy.cfg: 项目的配置文件
samzhu/: 该项目的python模块。之后您将在此加入代码。
samzhu/items.py: 项目中的item文件.
samzhu/pipelines.py: 项目中的pipelines文件.
samzhu/settings.py: 项目的设置文件.
samzhu/spiders/: 放置spider代码的目录.
3.Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类
为了创建一个Spider,必须继承 scrapy.Spider 类,且定义以下三个属性:name、start_urls、parse()
下面例子爬取了猫眼电影热映口碑榜,提取第一页中所有影片的相对地址
所有的spider类放下文件夹spiders下,并需要不同的name来作为标识
此处我们新建了一个文件one_spider.py并修改
# -*- coding: utf-8 -*-
import scrapy
class SamSpider(scrapy.Spider):
#用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
name = "sam"
#包含了Spider在启动时进行爬取的url列表
start_urls = [
"https://maoyan.com/board"
]
#被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
def parse(self, response):
print(response.text)
print('>'*50,'sam')
a=response.css('.movie-item-info .name a::attr(href)').extract()
print(a)
print('>'*50,'end')在项目文件夹下终端运行
scrapy crawl sam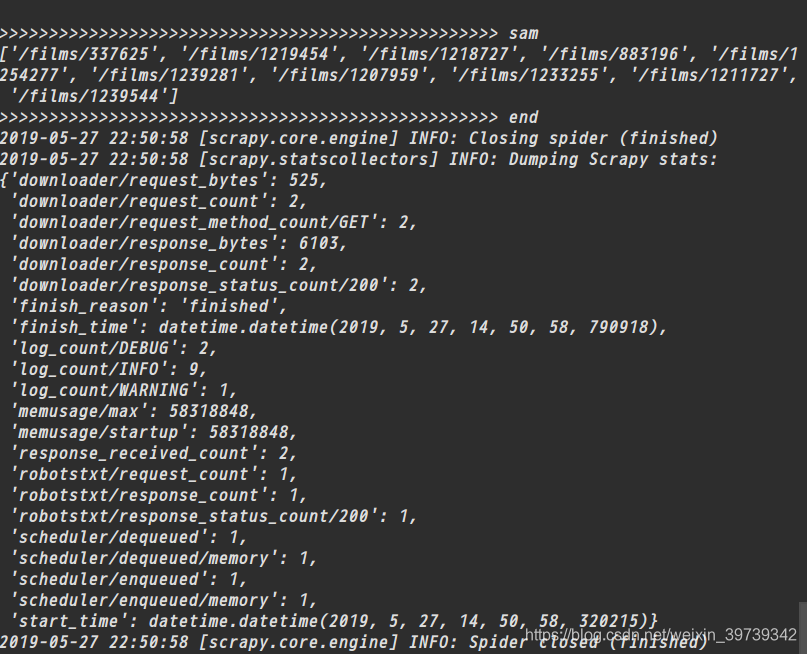

















 92
92

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









