





 本文记录了PyTorch使用中遇到的多种错误,包括在指定优化器变量时的错误、CUDA相关问题、计算图错误、版本迭代警告以及CUDNN错误。提供了解决方案,例如将列表转换为Tensor,确保权重和输入类型一致,避免in-place操作等。
本文记录了PyTorch使用中遇到的多种错误,包括在指定优化器变量时的错误、CUDA相关问题、计算图错误、版本迭代警告以及CUDNN错误。提供了解决方案,例如将列表转换为Tensor,确保权重和输入类型一致,避免in-place操作等。
前言: 本文主要记载在pytorch使用过程中遇到的一些报错以及解决方案等,在以前的文章[1]中,主要涉及的是比较容易出现的原理上的,或者难以发现的bug,而这里的主要是系统抛出的error或者warning的解决方法,其各有侧重,欢迎各位贡献idea。如有谬误,请联系指出,如需转载,请注明出处,谢谢。
e-mail: FesianXu@gmail.com
QQ: 973926198
github: https://github.com/FesianXu
在指定优化器的优化变量时
- 1 pytorch 版本号: 1.0.0 with python 3.6.1 报错内容: optimizer can only optimize Tensors, but one of the params is list 原因:在指定优化器的优化变量时,其必须是一个可迭代的参数对象或者是一个定义了优化组的字典[3],具体见[4]的操作。这个可迭代的参数对象一般可以是
list。 解决方案:将所有需要优化的对象用list进行包裹,如:
trained_vars = list(model.submodel_1.parameters()) +
list(model.submodel_2.parameters())
opt = torch.optim.SGD(trained_vars, lr=...)
注意到此时的trained_vars是一个可迭代的list,其中每个元素都是一个参数组。
CUDA相关
- 1 报错内容:RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same 版本: 1.0.0 with python 3.6.1 原因:有部分变量未加载进入显存,注意,在如下情况
class model(nn.Module):
def __init__(self):
super().__init__()
self.convs = [
nn.Conv2d(...),
nn.Conv2d(...)
]
m = model().cuda()
此时convs因为只是个list而不是集成了nn.Module的对象,因此是不会被迭代地放置到GPU中的,model().cuda()这种方式只会对model类中的__init__()方法中定义的继承了nn.Module的类的实例有效。 解决方法:
self.convs = [
nn.Conv2d(...),
nn.Conv2d(...)
]
self.convs = nn.ModuleList(self.convs)
- 2 报错内容:RuntimeError: cuDNN error: CUDNN_STATUS_BAD_PARAM 版本: pytorch 1.0 原因: 输入的
tensor的数据类型不匹配,应该是torch.float32()解决方法:
inputv = inputv.float()
model(inputv)
pytorch计算图相关
- 1 报错内容:RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation 版本: 1.0.0 with python 3.6.1 原因: 注意到有些操作属于
in-place操作,比如x += 1,x[0] = 5等,这类操作如果是在如下情况发生的:
c = x+b
x += 1
compute_gradient(ys=c, xs=x)
如果此时c对x对梯度,而x的值已经在后续的计算中发生了in-place的变化,那么就会导致出错[5]
解决方案:将x += 1改成x = x+1即可解决。
补充: x += 1在pytorch中是一个in-place操作,所谓in-place就是进行了该操作是对该变量直接进行处理后返回的,也就是说该变量的地址是不会改变的,只是值变了而已;而非in-place操作就是,在内存中另外开辟了一个空间存放新的值,然后将指针指向那个新的地址,在这种情况下,该变量的地址是会改变的。下面是一个例子:
In [1]: import torch
In [2]: a = torch.tensor(5)
In [3]: a
Out[3]: tensor(5)
In [4]: id(a)
Out[4]: 139636046877104
In [5]: a += 8
In [6]: a
Out[6]: tensor(13)
In [7]: id(a)
Out[7]: 139636046877104 # inplace操作,其地址不变
In [1]: import torch
In [2]: a = torch.tensor(6)
In [3]: id(a)
Out[3]: 139938915856816
In [4]: a = a+1
In [5]: a
Out[5]: tensor(7)
In [6]: id(a)
Out[6]: 139938915829584 # 非in-place操作,地址不同了
在pytorch中,计算梯度的时候有时候要求前面的相关变量不能被in-place操作改变,不然将会导致梯度计算问题,从而报错。
版本迭代
- 1 警告内容:/pytorch/torch/csrc/autograd/python_function.cpp:622: UserWarning: Legacy autograd function with non-static forward method is deprecated and will be removed in 1.3. Please use new-style autograd function with static forward method. 原因: 自定义层的时候,在新的版本的pytorch中将会抛弃旧的用法,旧的用法指的是其
forward方法为非静态方法,在1.3版本之后,forward方法要求定义成静态方法,具体参考[6]。
CUDNN相关
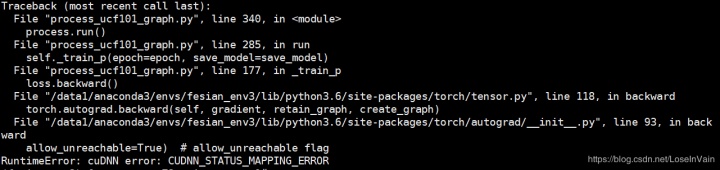
- 1 报错信息: RuntimeError: cuDNN error: CUDNN_STATUS_MAPPING_ERROR 原因: 原因不明,偶尔会触发,但是又不是进程性的,一般和代码无关,可能是CuDNN的bug,见[9] 解决方法: 在代码中添加
torch.backends.cudnn.enabled = False
import torch
torch.backends.cudnn.enabled = False
# your code here
其他
- 1 报错内容:undefined symbol: THPVariableClass 原因: 在导入某些和
pytorch有关的第三方包时,如果先导入第三方包,容易发生这种错误,正确的做法是首先导入pytorch,例如:[7]
import torch
import your_extension
- 2 报错内容: CUDA error 59: Device-side assert triggered 原因: 这个运行时错误太经典了,经常是因为定义的分类器的输出类别和标签的数量不匹配,比如分类器输出100个类,而期待的标签范围应该是[0,99],如果你输入一个标签是100,那么就会报出这种错误[8]
Reference
[1]. 用pytorch踩过的坑 [2]. https://discuss.pytorch.org/t/giving-multiple-parameters-in-optimizer/869 [3]. https://pytorch.org/docs/stable/optim.html?highlight=sgd#torch.optim.ASGD [4]. https://blog.youkuaiyun.com/LoseInVain/article/details/81708474 [5]. https://discuss.pytorch.org/t/encounter-the-runtimeerror-one-of-the-variables-needed-for-gradient-computation-has-been-modified-by-an-inplace-operation/836/5 [6]. https://discuss.pytorch.org/t/custom-autograd-function-must-it-be-static/14980 [7]. https://github.com/pytorch/extension-cpp/issues/6 [8]. https://towardsdatascience.com/cuda-error-device-side-assert-triggered-c6ae1c8fa4c3 [9]. https://github.com/pytorch/pytorch/issues/27588#issuecomment-603315518

















 4567
4567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









