







MySQL
表中十个字段,你主键用自增ID还是UUID,为什么?(我回答了自增和UUID的优缺点)
用的是自增 id。
因为 uuid 相对顺序的自增 id 来说是毫无规律可言的,新行的值不一定要比之前的主键的值要大,所以 innodb 无法做到总是把新行插入到索引的最后,而是需要为新行寻找新的合适的位置从而来分配新的空间。
这个过程需要做很多额外的操作,数据的毫无顺序会导致数据分布散乱,将会导致以下的问题:
-
写入的目标页很可能已经刷新到磁盘上并且从缓存上移除,或者还没有被加载到缓存中,innodb 在插入之前不得不先找到并从磁盘读取目标页到内存中,这将导致大量的随机 IO。
-
因为写入是乱序的,innodb 不得不频繁的做页分裂操作,以便为新的行分配空间,页分裂导致移动大量的数据,影响性能。
-
由于频繁的页分裂,页会变得稀疏并被不规则的填充,最终会导致数据会有碎片。
结论:使用 InnoDB 应该尽可能的按主键的自增顺序插入,并且尽可能使用单调的增加的聚簇键的值来插入新行。
为什么自增ID更快一些,UUID不快吗,它在B+树里面存储是有序的吗(我回答是有序的,然后从索引长度上说UUID更慢一些)
自增的主键的值是顺序的,所以 Innodb 把每一条记录都存储在一条记录的后面,所以自增 id 更快的原因:
-
下一条记录就会写入新的页中,一旦数据按照这种顺序的方式加载,主键页就会近乎于顺序的记录填满,提升了页面的最大填充率,不会有页的浪费
-
新插入的行一定会在原有的最大数据行下一行,mysql定位和寻址很快,不会为计算新行的位置而做出额外的消耗
-
减少了页分裂和碎片的产生
但是 UUID 不是递增的,MySQL 中索引的数据结构是 B+Tree,这种数据结构的特点是索引树上的节点的数据是有序的,而如果使用 UUID 作为主键,那么每次插入数据时,因为无法保证每次产生的 UUID 有序,所以就会出现新的 UUID 需要插入到索引树的中间去,这样可能会频繁地导致页分裂,使性能下降。
而且,UUID 太占用内存。每个 UUID 由 36 个字符组成,在字符串进行比较时,需要从前往后比较,字符串越长,性能越差。另外字符串越长,占用的内存越大,由于页的大小是固定的,这样一个页上能存放的关键字数量就会越少,这样最终就会导致索引树的高度越大,在索引搜索的时候,发生的磁盘 IO 次数越多,性能越差。
查询数据时,到了B+树的叶子节点,之后的查找数据是如何做?
数据页中的记录按照「主键」顺序组成单向链表,单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索。因此,数据页中有一个页目录,起到记录的索引作用,就像我们书那样,针对书中内容的每个章节设立了一个目录,想看某个章节的时候,可以查看目录,快速找到对应的章节的页数,而数据页中的页目录就是为了能快速找到记录。那 InnoDB 是如何给记录创建页目录的呢?页目录与记录的关系如下图:
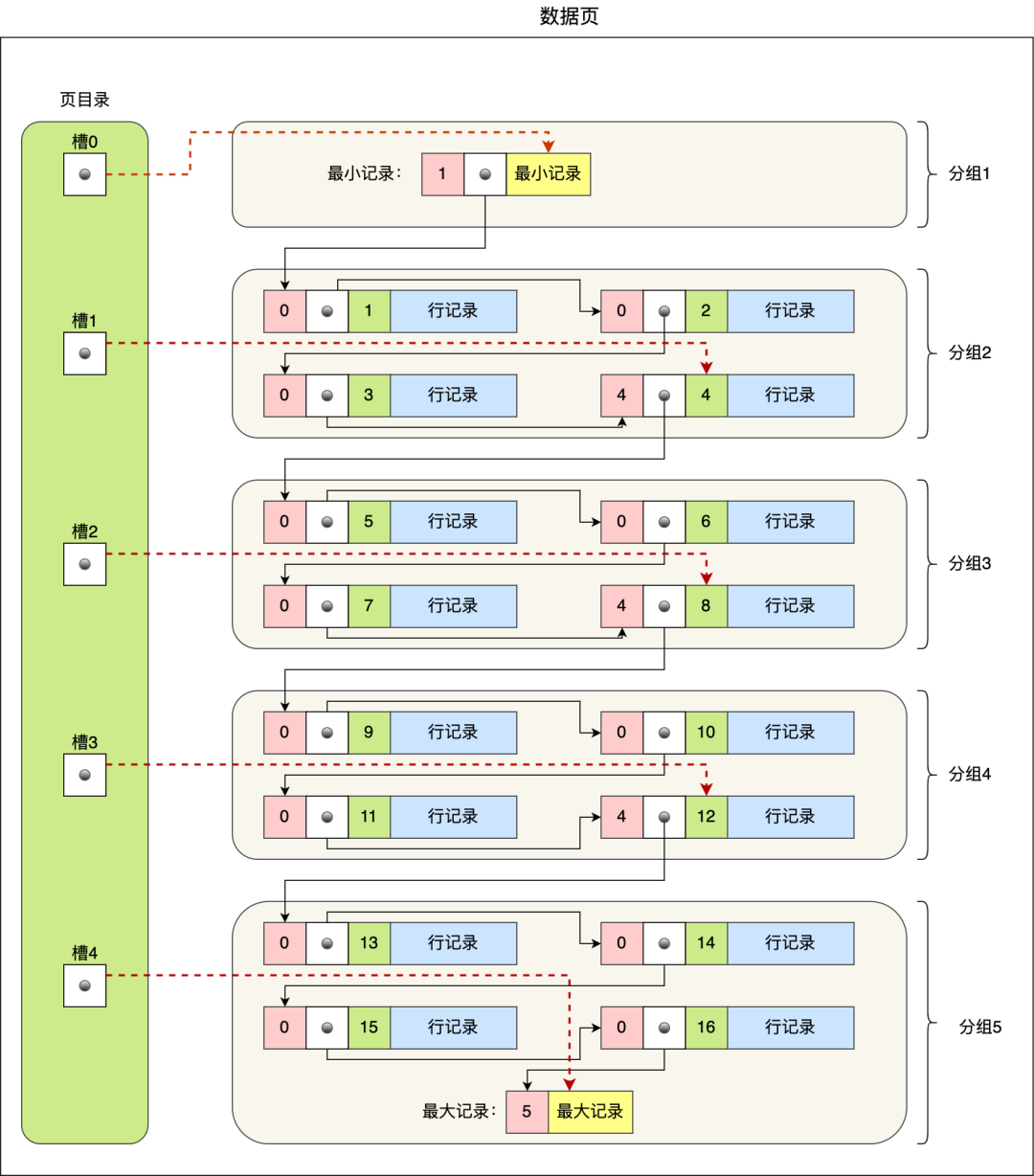
页目录创建的过程如下:
-
将所有的记录划分成几个组,这些记录包括最小记录和最大记录,但不包括标记为“已删除”的记录;
-
每个记录组的最后一条记录就是组内最大的那条记录,并且最后一条记录的头信息中会存储该组一共有多少条记录,作为 n_owned 字段(上图中粉红色字段)
-
页目录用来存储每组最后一条记录的地址偏移量,这些地址偏移量会按照先后顺序存储起来,每组的地址偏移量也被称之为槽(slot),每个槽相当于指针指向了不同组的最后一个记录。
从图可以看到,页目录就是由多个槽组成的,槽相当于分组记录的索引。然后,因为记录是按照「主键值」从小到大排序的,所以我们通过槽查找记录时,可以使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到对应的记录,无需从最小记录开始遍历整个页中的记录链表。以上面那张图举个例子,5 个槽的编号分别为 0,1,2,3,4,我想查找主键为 11 的用户记录:
-
先二分得出槽中间位是 (0+4)/2=2 ,2号槽里最大的记录为 8。因为 11 > 8,所以需要从 2 号槽后继续搜索记录;
-
再使用二分搜索出 2 号和 4 槽的中间位是 (2+4)/2= 3,3 号槽里最大的记录为 12。因为 11 < 12,所以主键为 11 的记录在 3 号槽里;
-
再从 3 号槽指向的主键值为 9 记录开始向下搜索 2 次,定位到主键为 11 的记录,取出该条记录的信息即为我们想要查找的内容。
你说你会MySQL,那它有哪些存储引擎(InnoDB和MyISAM)?
-
InnoDB:InnoDB是MySQL的默认存储引擎,具有ACID事务支持、行级锁、外键约束等特性。它适用于高并发的读写操作,支持较好的数据完整性和并发控制。
-
MyISAM:MyISAM是MySQL的另一种常见的存储引擎,具有较低的存储空间和内存消耗,适用于大量读操作的场景。然而,MyISAM不支持事务、行级锁和外键约束,因此在并发写入和数据完整性方面有一定的限制。
-
Memory:Memory引擎将数据存储在内存中,适用于对性能要求较高的读操作,但是在服务器重启或崩溃时数据会丢失。它不支持事务、行级锁和外键约束。
InnoDB的四种隔离级别,你平常做项目和实习用的什么隔离级别(默认的)
用的是默认的,可重复读隔离级别
可重复读有没有幻读的问题?(举了例子)
有的,可重复读隔离级别下虽然很大程度上避免了幻读,但是还是没有能完全解决幻读。我举例一个可重复读隔离级别发生幻读现象的场景。以这张表作为例子:
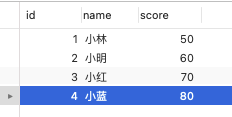
事务 A 执行查询 id = 5 的记录,此时表中是没有该记录的,所以查询不出来。
# 事务 A
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from t_stu where  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











