






 本文深入探讨统计学中的关键概念,包括方差、标准差、协方差和皮尔森相关系数,解释了它们在数据分析中的作用及计算方法,特别强调了方差估计中分母选择的重要性。
本文深入探讨统计学中的关键概念,包括方差、标准差、协方差和皮尔森相关系数,解释了它们在数据分析中的作用及计算方法,特别强调了方差估计中分母选择的重要性。
方差:
在给定皮尔森相关系数的定义以前,先给出一些统计学的基本概念,样本之间存在
均值: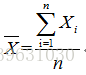 方差:
方差: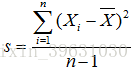 标准差:
标准差: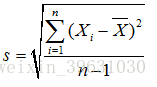
标准差是衡量样本集合的各个样本点到均值的距离之平均,是描述样本之间的离散程度,而方差是标准差的平方。
有人会问了,为什么方差的分母是n-1,而不是n?
在给出回答之前,先解释一下什么是无偏估计
无偏估计:估计量的均值等于真实值,即具体每一次估计值可能大于真实值,也可能小于真实值,而不能总是大于或小于真实值(这就产生了系统误差)。
如果已知全部的数据,那么均值和方差可以直接求出。但是对一个随机变量X,需要估计它的均值和方差,此时才用分母为n-1的公式来估计他的方差,因此分母是n-1才能使对方差的估计(而不是方差)是无偏的。因此,这个问题应该改为,为什么随机变量的方差的估计的分母是n-1?如果我们已经知道了全部的数据,那就可以求出均值μ,sigma,此时就是常规的分母为n的公式直接求,这并不是估计!
但是,在实际估计随机变量X的方差的时候,我们是不知道它的真实期望的,而是用期望的估计值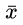 去估计方差,那么:
去估计方差,那么:
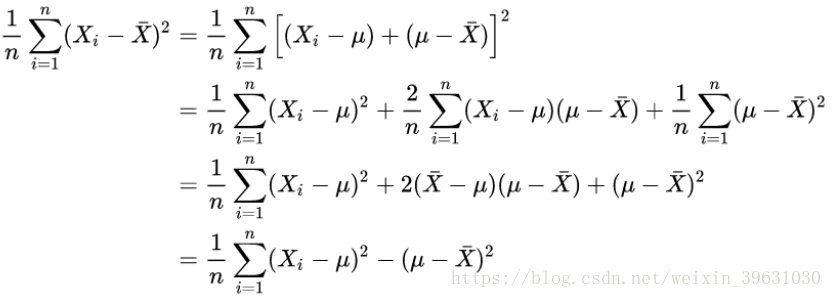
除非正好有![]() ,否则一定有
,否则一定有
![]()
而等式右边的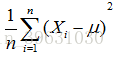 才是对样本方差的正确估计;
才是对样本方差的正确估计;
这个不等式就说明 了为什么用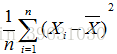 会导致对方差的低估。所以把n替换为n-1,就是把方差稍微放大一点点,至于为什么是n-1而不是n-2、n-3,其中有严格的数学证明。
会导致对方差的低估。所以把n替换为n-1,就是把方差稍微放大一点点,至于为什么是n-1而不是n-2、n-3,其中有严格的数学证明。
协方差:
我们应该注意到,标准差和方差一般是用来描述一维数据的,但现实生活我们常常遇到含有多维数据的数据集;
方差的定义

从而引出衡量两变量之间的协方差公式

协方差用于表示变量间的相互关系,变量间的相互关系一般有三种:线性正相关,线性负相关和线性不相关。
如果结果为正值,则说明两者是线性正相关的;如果结果为负值,则两者是线性负相关;如果结果为0,则两者线性不相关。
皮尔森相关系数
皮尔森相关系数为了确定每个特征之间是否紧密相关,如果很相关就属于重复特征,可以去除,达到去重或者降维的效果。 我们输入机器学习模型中的每个特征都独一无二,这才是最佳。
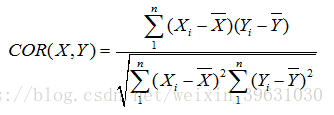
有公式可知,皮尔森相关系数是由变量间的协方差除以变量间的标准差得到的,
虽然协方差能反映两个随机变量的相关程度(协方差大于0的时候表示两者正相关,小于0的时候表示两者负相关),但其数值上受量纲的影响很大,不能简单地从协方差的数值大小给出变量相关程度的判断。为了消除这种量纲的影响,于是就有了皮尔森相关系数的概念。
当两个变量的方差都不为零时,相关系数才有意义,相关系数的取值范围为[-1,1]。《数据挖掘导论》中给了一个很形象的图来说明相关度大小与相关系数之间的联系:
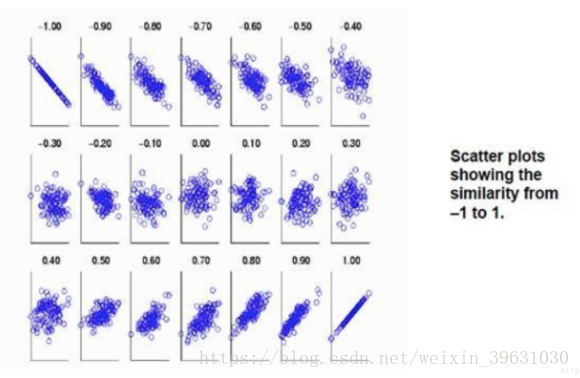
由上图可以总结,当相关系数为1时,成为完全正相关;当相关系数为-1时,成为完全负相关;相关系数的绝对值越大,相关性越强;相关系数越接近于0,相关度越弱。
xx = [1,2,3,4,5]
yy = [1,2,3,4,5]
# 样本均值
def mean(x):
sum_ = 0
for i in x:
sum_ += i
return sum_ / len(x)
# 方差
def std(x):
tmp_ = 0
mean_ = mean(x)
for i in x:
tmp_ += (i-mean_)**2
import math
return math.sqrt(tmp_ / (len(x)-1))
# 协方差
def cov(x,y):
sum_ = 0
for i in range(len(x)):
sum_ += (x[i]-mean(x))*(y[i]-mean(y))
return sum_ / (len(x)-1)
# 相关系数
def COR(x,y):
return cov(x,y) / (std(x)*std(y))
print(COR(xx,yy))

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









