




本文章为 SQL Server 的详细学习大纲 里面的一个子章节的详细介绍,如果想了解相关的其他内容,可以从这里面查看,或者查看SQL Server专栏,里面有些文章可能并不在 SQL Server 的详细学习大纲 里面,是一些补充内容。
| 函数名称 | 说明 |
|---|---|
| APPROX_COUNT_DISTINCT | 用于返回组中不同非空值的近似数量。在处理大规模数据时,能快速提供一个大致的不同值数量估计,相比精确计算不同值数量的方法,在性能上有优势,适用于对精度要求不是极高的场景。 |
| AVG | 计算一组数值的平均值。会忽略 NULL 值,将非 NULL 值相加后除以非 NULL 值的数量得到平均值,常用于统计分析中获取数据的平均水平。 |
| CHECKSUM_AGG | 返回组中值的校验和。可用于检测数据在传输或存储过程中是否发生变化,通过对比校验和来判断数据的完整性。 |
| COUNT | 计算组中项目的数量。有两种形式,COUNT(*)会计算包括 NULL 值在内的所有行的数量,而COUNT(column)则只计算指定列中非 NULL 值的行数,在统计数据行数时非常常用。 |
| COUNT_BIG | 与COUNT功能类似,但返回值的数据类型为bigint,可处理更大规模的数据计数,避免因数据量过大导致整数溢出的问题。 |
| GROUPING | 用于指示是否对指定列进行了分组。在使用ROLLUP或CUBE等扩展GROUP BY操作时,帮助识别结果集中的汇总行,辅助数据分析和报表生成。 |
| GROUPING_ID | 返回一个表示分组级别或组合的整数值。与GROUPING函数配合使用,能更精确地确定在复杂分组操作中的分组情况,在处理多维数据分析的分组汇总场景中很有帮助。 |
| MAX | 返回一组值中的最大值。忽略 NULL 值,能快速找出数据集中的最大数值,在数据比较和范围分析中常用。 |
| MIN | 返回一组值中的最小值。同样忽略 NULL 值,用于确定数据的下限,与MAX函数一起可用于分析数据的取值范围。 |
| STDEV | 计算样本标准偏差。基于样本数据估计数据的离散程度,反映数据相对于平均值的波动情况,在统计学和数据分析中用于评估数据的稳定性和变异性。 |
| STDEVP | 计算总体标准偏差。与STDEV不同,它是基于总体数据计算的,在已知总体数据的情况下,能更准确地描述数据的离散特征。 |
| STRING_AGG | 将字符串值连接成一个字符串。可以指定分隔符,方便将多行数据中的字符串列合并为一个统一的字符串,在数据处理和报表展示中用于文本合并操作。 |
| SUM | 计算一组数值的总和。忽略 NULL 值,对指定列的非 NULL 值进行求和运算,常用于计算总量、累计值等场景。 |
| VAR | 计算样本方差。衡量样本数据的离散程度,通过与平均值的偏差平方和来体现数据的变异性,在数据分析和统计推断中具有重要作用。 |
| VARP | 计算总体方差。与VAR的区别在于计算基于总体数据,能更准确地反映总体数据的离散特性。 |
构建测试数据:
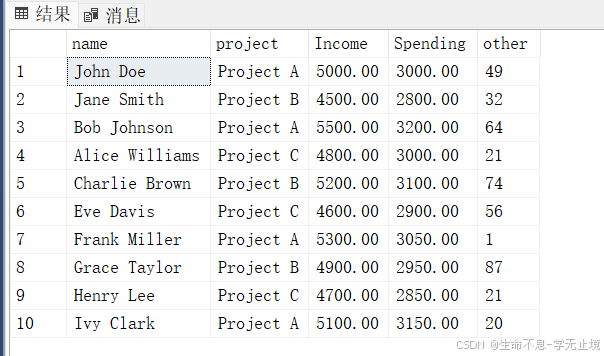
create table test_table(name varchar(15) ,project varchar(15), Income decimal(15,2) , Spending decimal(15,2),other int );
INSERT INTO test_table (name, project, Income, Spending, other) VALUES
('John Doe', 'Project A', 5000.00, 3000.00,49),
('Jane Smith', 'Project B', 4500.00, 2800.00,32),
('Bob Johnson', 'Project A', 5500.00, 3200.00,64),
('Alice Williams', 'Project C', 4800.00, 3000.00,21),
('Charlie Brown', 'Project B', 5200.00, 3100.00,74),
('Eve Davis', 'Project C', 4600.00, 2900.00,56),
('Frank Miller', 'Project A', 5300.00, 3050.00,1),
('Grace Taylor', 'Project B', 4900.00, 2950.00,87),
('Henry Lee', 'Project C', 4700.00, 2850.00,21),
('Ivy Clark', 'Project A', 5100.00, 3150.00,20);
select * from test_table;
例子:
-- 假设存在名为 test_table 的表,包含列 Income(数值类型)、project(字符串类型)
SELECT
--使用 APPROX_COUNT_DISTINCT 计算 Income 列不同非空值的近似数量
APPROX_COUNT_DISTINCT(Income) AS approx_distinct_count,
--计算 Income 列的平均值
AVG(Income) AS average_value,
-- 计算包括 NULL 值在内的所有行数量
COUNT(*) AS total_row_count,
-- 计算 Income 列非 NULL 值的行数
COUNT(Income) AS non_null_count,
--由于 COUNT_BIG 与 COUNT 类似,这里以 COUNT 为例,实际使用时可根据数据规模和需求替换
COUNT_BIG(Income) AS bigint_count,
--使用 GROUPING 函数(假设按 Income 分组),这里只是示例,实际可能需要结合 ROLLUP 或 CUBE 等操作才有实际意义
GROUPING(project) AS grouping_result,
--使用 GROUPING_ID 函数(假设按 Income 分组),同样实际可能需要复杂分组场景才有实际意义
GROUPING_ID(project) AS grouping_id_result,
--找出 Income 列的最大值
MAX(Income) AS max_value,
-- 找出 Income 列的最小值
MIN(Income) AS min_value,
-- 计算 Income 列的样本标准偏差
STDEV(Income) AS stdev_value,
-- 计算 Income 列的总体标准偏差
STDEVP(Income) AS stdevp_value,
-- 计算 Income 列的总和
SUM(Income) AS sum_value,
-- 计算 Income 列的样本方差
VAR(Income) AS var_value,
-- 计算 Income 列的总体方差
VARP(Income) AS varp_value
FROM
test_table
group by ROLLUP(project);
select
-- 将 project 列的字符串值连接成一个字符串,以逗号分隔
STRING_AGG(name, ',') AS concatenated_strings,
-- 计算 Income 列值的校验和
CHECKSUM_AGG(other) AS checksum_agg_result
from test_table
group by project;



















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











