



 本文介绍了SQL Server中常用的聚合函数,如COUNT(), SUM(), AVG(), MIN(), MAX(),并结合GROUP BY子句进行数据分组统计。通过示例展示了如何查询每个组的行数、总数、平均值和范围。同时,讲解了HAVING子句的用法,用于在GROUP BY之后进一步过滤分组结果,实现更复杂的条件筛选。"
105023776,8483590,MATLAB绘图详解,"['MATLAB', '图形绘制', '数据可视化']
本文介绍了SQL Server中常用的聚合函数,如COUNT(), SUM(), AVG(), MIN(), MAX(),并结合GROUP BY子句进行数据分组统计。通过示例展示了如何查询每个组的行数、总数、平均值和范围。同时,讲解了HAVING子句的用法,用于在GROUP BY之后进一步过滤分组结果,实现更复杂的条件筛选。"
105023776,8483590,MATLAB绘图详解,"['MATLAB', '图形绘制', '数据可视化']
在数据库中有大量的数据,如果统计起来会较为麻烦,比如统计某数据的平均值或者总数值,但是在SQL Server中有聚合函数可以使用,聚合函数会对一个组进行运算然后返回计算的结果,通常和GROUP BY子句一起使用,因为GROUP BY子句可以将行排序成组。经常使用的聚合函数有以下几个,COUNT():返回每个组中的行数、SUM():返回组中的总和、AVG():返回组中的平均值、MIN():返回组中最小的值、MAX():返回组中最大的值。
首先使用建立一个表,名为Tab,列名为num1的数值用来分组,列名为num2的作为组的数据,值得一提的是作为计算的num2的数据类型是为number类型,否则SUM()、AVG()这些计算型的聚合函数都使用不了,下面的案例将使用该表的数据进行介绍

案例1:查询1组和2组分别有多少行

结果是一组的数据是三行,二组的数据都是四行,从表的数据来看是没问题的
案例2:查询1组和2组分别的总数值
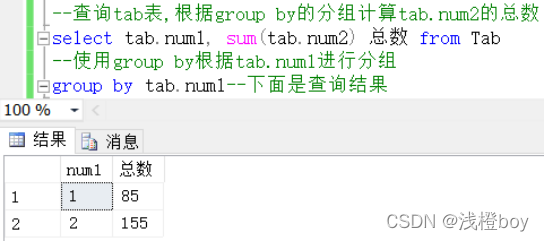
根据以上两次的查询可以看得出来其实聚合函数使用的方法基本上是相差无几无非就是自己的需求做出对应的选择
下面介绍一下HAVING子句,HAVING子句通常与GROUP BY子句一起使用,根据HAVING子句的条件过滤掉不需要的分组,在HAVING子句中因为前面使用了GROUP BY子句形成了一个组,在判断条件时不能使用列名进行判断,所以需要用指定的条件聚合函数才可以进行判断,即使这个聚合函数在后面的查询结果没有出现,下面举一个例子
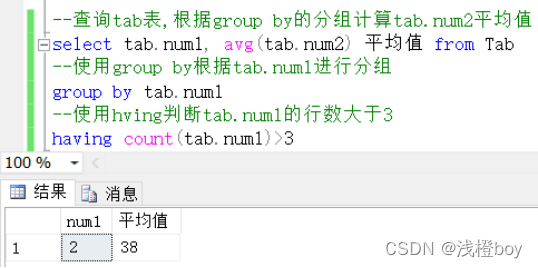
查询1组和2组分别的平均数,但是只需要查询行数大于三的组
结果是只有2组的行数大于三,而1组在过滤中排除在外了
关于HAVING子句其作用不仅单条件筛选还可以多条件筛选,下面在举一个例子
查询1组和2组分别的总值,但是只需要查询组最大值小于40和最小值大于10的组
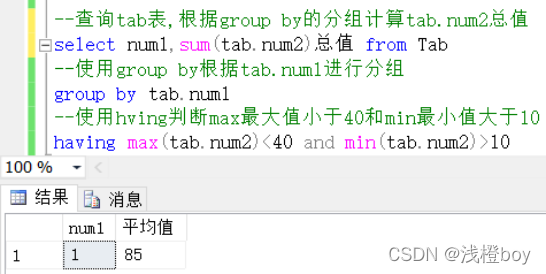
结果是只有1组的最大值小于40和最小值大于10,而2组在过滤中排除在外了
以上便是本次分享的全部内容

















 1377
1377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









