




 博客介绍了FP-growth算法,它用于发现繁集项,相比Apriori算法更快,只需扫描两次数据集。阐述了Apriori的支持度和置信度概念,指出FP-growth基于历史数据,不适用于新品推荐和数据流处理,介绍了其构建步骤和应用场景,还提到可能需手写代码。
博客介绍了FP-growth算法,它用于发现繁集项,相比Apriori算法更快,只需扫描两次数据集。阐述了Apriori的支持度和置信度概念,指出FP-growth基于历史数据,不适用于新品推荐和数据流处理,介绍了其构建步骤和应用场景,还提到可能需手写代码。
FP-growth是发现繁集项的一种算法,说到它大家都在把它与Apriori算法做比较,得出来的是FP-growth算法发现繁集项更快,
Apriori中有两个概念:
1. 支持度: 某一事物占所有事物的比例
2. 置信度: 类似条件概率,A ==> B 的置信度 支持度{A,B}/支持度{A}
FP-growth比Apriori更优一点,FP-growth只需要扫描两次数据集。
FP-growth算法是基于历史数据,不适应新品推荐,也不适合数据流处理。
FP-growth算法主要是2部分:
1. 扫描一次全表,构建表头项(去掉支持度为1, 2)
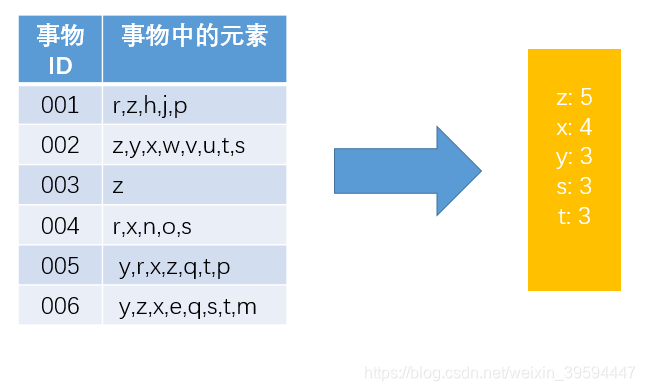
2. 扫描一次全表,构建FP树
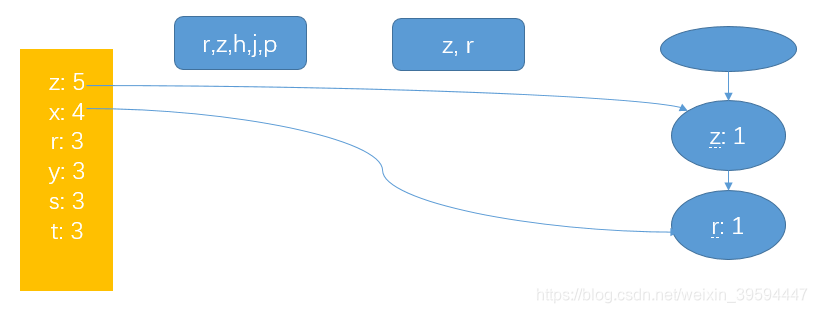
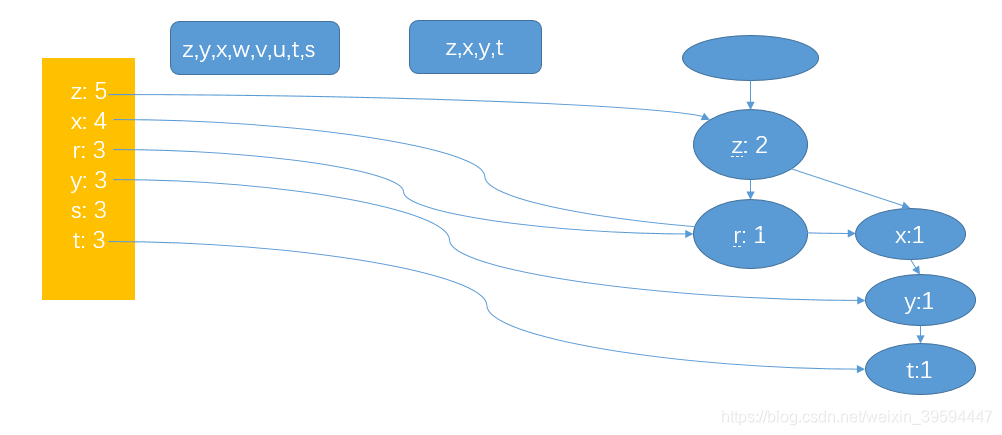
FP-growth应用: 搜索繁集项,按最小支持度搜索或者抽取条件模式基。
FP-growth这部分代码没找到现成的,可能需要自己手写。

















 4622
4622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









