 数据库频繁项集挖掘:FP增长算法详解
数据库频繁项集挖掘:FP增长算法详解





 本文通过实例解析,介绍了如何使用FP增长算法在支持度为60%、置信度为80%的条件下,找出数据库中的频繁项集,包括步骤一的字母计数、步骤二的FP图绘制,以及步骤三条件模式基的生成过程。
本文通过实例解析,介绍了如何使用FP增长算法在支持度为60%、置信度为80%的条件下,找出数据库中的频繁项集,包括步骤一的字母计数、步骤二的FP图绘制,以及步骤三条件模式基的生成过程。
题目:数据库有5个事物,设min_sup=60%(支持度),min_conf=80%(置信度)
使用FP增长算法找出所有的频繁项集。
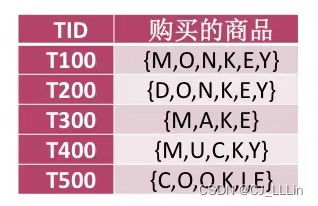
步骤① :数出字母个数
min_sup=60%,所以去除个数 <3(5×0.6)的字母;
(若同一行有2个以上相同字母,则都算作1个)
因此结果为:K 5 、 E 4 、 M 3 、O 3 、Y 3
步骤② :画出FP图
(按步骤①的结果排序,而不是商品的名字字母顺序)
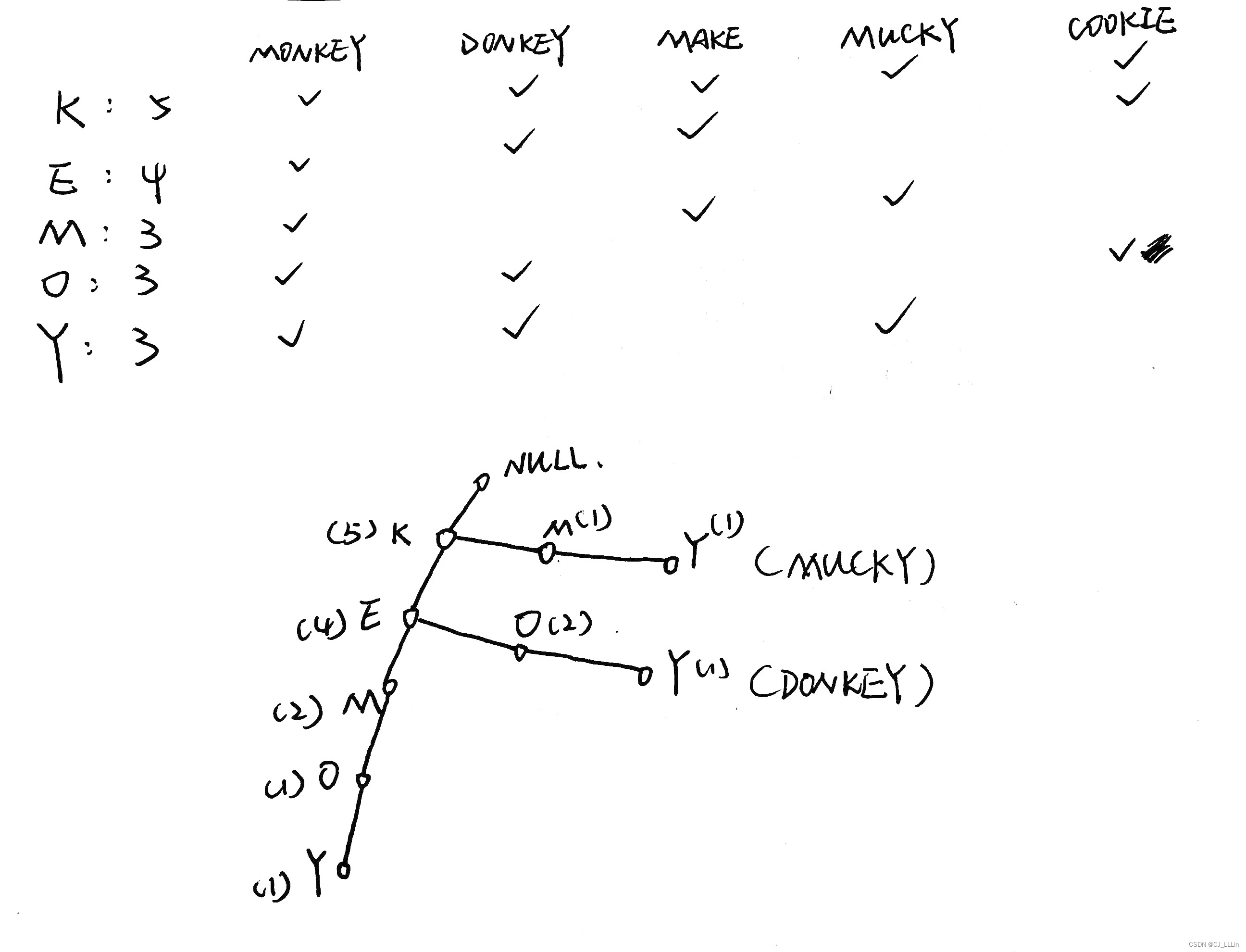
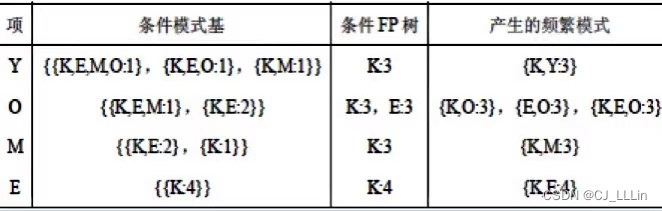
步骤③ :写出4种条件模式基(Y、O、M、E),从而找出所有的频繁项集
(min_sup=60%,所以去除个数 <3(5×0.6)的字母)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









