







 超级会员免费看
超级会员免费看
 这篇博客深入探讨了线性回归,包括一元和多元线性回归的概念、拟合过程、损失函数和参数求解。通过实例展示了如何使用最小二乘法求解线性回归模型,并介绍了模型评估指标如MSE、RMSE、MAE和R2。
这篇博客深入探讨了线性回归,包括一元和多元线性回归的概念、拟合过程、损失函数和参数求解。通过实例展示了如何使用最小二乘法求解线性回归模型,并介绍了模型评估指标如MSE、RMSE、MAE和R2。
回归分析
回归分析是用来评估变量之间关系的统计过程。用来解释自变量X与因变量Y的关系。即当自变量X发生改变时,因变量Y会如何发生改变。
线性回归
回归分析的一种,评估的自变量X与因变量Y之间是一种线性关系。当只有一个自变量时,称为一元线性回归,当具有多个自变量时,称为多元线性回归。
线性关系的理解:
- 画出来的图像是直的。
- 每个自变量的最高次项为1。
拟合
拟合,是指构建一种算法(数学函数),使得该算法能够符合真实的数据。从机器学习角度讲,线性回归就是要构建一个线性函数,使得该函数与目标值之间的拟合性最好。从空间的角度来看,就是要让函数的直线(面),尽可能穿过空间中的数据点。线性回归会输出一个连续值。
一元线性回归
我们从简单的一元线性回归开始。这里,我们以房屋面积(x)与房屋价格(y)为例,显而易见,二者是一种线性关系,房屋价格正比于房屋面积,我们假设比例为 w:
y
^
=
w
∗
x
\hat{y} = w * x
y^=w∗x
然而,这种线性方程一定是过原点的,即当x为0时,y也一定为0。这可能并不符合现实中某些场景。为了能够让方程具有更广泛的适应性,我们这里再增加一个截距,设为b,即之前的方程变为:
y
^
=
w
∗
x
+
b
\hat{y} = w * x + b
y^=w∗x+b
而以上方程,就是我们数据建模的模型。方程中的w与b,就是模型的参数。
假定数据集如下:
| 房屋面积 | 房屋价格 |
|---|---|
| 30 | 100 |
| 40 | 120 |
| 40 | 115 |
| 50 | 130 |
| 50 | 132 |
| 60 | 147 |
线性回归是用来解释自变量与因变量之间的关系,但是,这种关系并非严格的函数映射关系。从数据集中,我们也看到了这一点。相同面积的房屋,价格并不完全相同,但是,也不会相差过大。
解决方法
我们现在的目的就是,从现有的数据(经验)中,去学习(确定)w与b的值。一旦w与b的值确定,我们就能够确定拟合数据的线性方程,这样就可以对未知的数据 x(房屋面积)进行预测 y(房屋价格)。
多元线性回归
然而,现实中的数据可能是比较复杂的,自变量也很可能不只一个。例如,影响房屋价格也很可能不只房屋面积一个因素,可能还有距地铁距离,距市中心距离,房间数量,房屋所在层数,房屋建筑年代等诸多因素。不过,这些因素,对房屋价格影响的力度(权重)是不同的,例如,房屋所在层数对房屋价格的影响就远不及房屋面积,因此,我们可以使用多个权重来表示多个因素与房屋价格的关系:
y
^
=
w
1
∗
x
1
+
w
2
∗
x
2
+
w
3
∗
x
3
+
…
…
+
w
n
∗
x
n
+
b
\hat{y} = w_{1} * x_{1} + w_{2} * x_{2} + w_{3} * x_{3} + …… + w_{n} * x_{n} + b
y^=w1∗x1+w2∗x2+w3∗x3+……+wn∗xn+b
其中,每个x为影响因素(特征),每个w为对应的影响力度(权重),y 为房屋的价格(预测值)。我们也可以使用向量的表示方式,设x与w为两个向量:
w
=
(
w
1
,
w
2
,
w
3
,
…
…
w
n
)
x
=
(
x
1
,
x
2
,
x
3
,
…
…
x
n
)
w = (w_{1}, w_{2}, w_{3}, …… w_{n})\\ x = (x_{1}, x_{2}, x_{3}, …… x_{n})
w=(w1,w2,w3,……wn)x=(x1,x2,x3,……xn)
则方程可表示为:
y
^
=
∑
j
=
1
n
w
j
∗
x
j
+
b
=
w
T
∗
x
+
b
\hat{y} = \sum_{j=1}^{n}w_{j} * x_{j} + b\\ \ \ = w ^ {T} * x + b
y^=∑j=1nwj∗xj+b =wT∗x+b
我们也可以令:
{
x
0
=
1
w
0
=
b
\left\{\begin{matrix}x_{0} = 1 & \\ w_{0} = b & \end{matrix}\right.
{x0=1w0=b
这样,就可以表示为:
y
^
=
w
0
∗
x
0
+
w
1
∗
x
1
+
w
2
∗
x
2
+
w
3
∗
x
3
+
…
…
+
w
n
∗
x
n
=
∑
j
=
0
n
w
j
∗
x
j
=
w
T
∗
x
\hat{y} = w_{0} * x_{0} + w_{1} * x_{1} + w_{2} * x_{2} + w_{3} * x_{3} + …… + w_{n} * x_{n}\\ \ \ = \sum_{j=0}^{n}w_{j} * x_{j}\\ \ \ = w ^ {T} * x
y^=w0∗x0+w1∗x1+w2∗x2+w3∗x3+……+wn∗xn =∑j=0nwj∗xj =wT∗x
说明:在机器学习中,习惯用上标表示样本,用下标表示特征。
多元线性回归在空间中,可以表示为一个超平面,去拟合空间中的数据点。
损失函数
通过之前的介绍,我们得知,对机器学习来讲,就是从已知数据(经验)去建立一个模型,使得该模型能够对未知的数据进行预测。实际上,机器学习的过程,就是确定(学习)模型参数(即模型的权重与偏置)的过程,因为只要模型的参数确定了,我们就可以利用模型进行预测(有参数模型)。
那么,模型的参数该如果求解呢?
对于监督学习来说,我们可以通过建立损失函数来实现。损失函数,也称目标函数或代价函数,简单的说,就是关于误差的一个函数。损失函数用来衡量模型预测值与真实值之间的差异。
机器学习的目标,就是要建立一个损失函数,使得该函数的值最小。
也就是说,损失函数是一个关于模型参数的函数(以模型参数作为自变量的函数),自变量可能的取值组合通常是无限的,我们的目标,就是要在众多可能的组合中,找到一组最合适的自变量组合(值),使得损失函数的值最小。
损失函数我们习惯使用 J 来表示,例如,J(w) 则表示以 w 为自变量的函数。
损失函数分类
损失函数有很多种,常见的损失函数为:
- 平方和损失函数
- 交叉熵损失函数
参数求解
误差与分布
接下来,我们来看一下线性回归模型中的误差。正如我们之前所提及的,线性回归解释的变量(现实中存在的样本),是存在线性关系的。然而,这种关系并不是严格的函数映射关系,但是,我们构建的模型(方程)却是严格的函数映射关系的,因此,对于每个样本来说,我们拟合的结果会与真实值之间存在一定的误差,我们可以将误差表示为:
y ^ ( i ) = w T ∗ x ( i ) y ( i ) = y ^ ( i ) + ε ( i ) \hat{y} ^ {(i)} = w ^ {T} * x ^ {(i)}\\ y ^ {(i)} = \hat{y} ^ {(i)} + \varepsilon ^ {(i)} y^(i)=wT∗x(i)y(i)=y^(i)+ε(i)
其中, ε ( i ) \varepsilon ^ {(i)} ε(i)表示每个样本与实际值之间的误差。
由于每个样本的误差 ε \varepsilon ε是独立同分布的,根据中心极限定理, ε \varepsilon ε服从均值为0,方差为 σ 2 \sigma ^ {2} σ2的正态分布。因此,根据正态分布的概率密度公式:
p ( ε ( i ) ) = 1 σ 2 π e x p ( − ( ε ( i ) ) 2 2 σ 2 ) p ( y ( i ) ∣ x ( i ) ; w ) = 1 σ 2 π e x p ( − ( y ( i ) − w T x ( i ) ) 2 2 σ 2 ) p(\varepsilon ^ {(i)}) = \frac{1}{\sigma\sqrt{2\pi}}exp(-\frac{(\varepsilon ^ {(i)}) ^ {2}}{2\sigma ^ {2}})\\ p(y ^ {(i)}|x ^ {(i)};w) = \frac{1}{\sigma\sqrt{2\pi}}exp(-\frac{(y ^ {(i)} - w ^ {T}x ^ {(i)}) ^ {2}}{2\sigma ^ {2}}) p(ε(i))=σ2π1exp(−2σ2(ε(i))2)p(y(i)∣x(i);w)=σ2π1exp(−2σ2(y(i)−wTx(i))2)
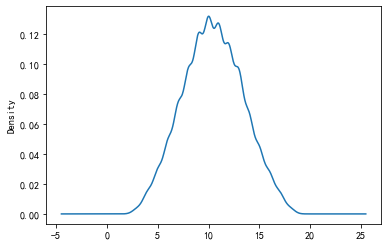
# 中心极限定理
# 如果随机变量X(x1, x2, x3……)是独立同分布的,则变量之间的和
# 是服从正态分布的。
# 玩骰子 三粒 取值 3 - 18
import numpy as np
import pandas as pd
result = []
for i in range(10000):
result.append(np.sum(np.random.randint(1, 7, size=3)))
s = pd.Series(result)
s.plot(kind="kde")
最大似然估计
以上是一个样本的概率密度,我们假设数据集中共有m个样本,每个样本具有n个特征,则多个样本的联合密度函数(似然函数)为:
L ( w ) = ∏ i = 1 m p ( y ( i ) ∣ x ( i ) ; w ) = ∏ i = 1 m 1 σ 2 π e x p ( − ( y ( i ) − w T x ( i ) ) 2 2 σ 2 ) L(w) = \prod_{i=1}^{m}p(y ^ {(i)}|x ^ {(i)};w)\\ = \prod_{i=1}^{m}\frac{1}{\sigma\sqrt{2\pi}}exp(-\frac{(y ^ {(i)} - w ^ {T}x ^ {(i)}) ^ {2}}{2\sigma ^ {2}}) L(w)=∏i=1mp(y(i)∣x(i);w)=∏i=1mσ2π1exp(−2σ2(y(i)−wTx(i))2)
根据最大似然估计,我们让所有样本出现的联合概率最大,则此时参数w的值,就是我们要求解的值。不过,累计乘积的方式不利于求解,我们这里使用对数似然函数,即在联合密度函数上取对数操作(取对数操作不会改变函数的极值点),这样就可以将累计乘积转换为累计求和的形式。
l n ( L ( w ) ) = l n ∏ 1 m 1 σ 2 π e x p ( − ( y ( i ) − w T x ( i ) ) 2 2 σ 2 ) = ∑ 1 m l n 1 σ 2 π e x p ( − ( y ( i ) − w T x ( i ) ) 2 2 σ 2 ) = m l n 1 σ 2 π − 1 σ 2 ∗ 1 2 ∑ 1 m ( y ( i ) − w T x ( i ) ) 2 ln(L(w)) = ln\prod_{1}^{m}\frac{1}{\sigma\sqrt{2\pi}}exp(-\frac{(y ^ {(i)} - w ^ {T}x ^ {(i)}) ^ {2}}{2\sigma ^ {2}})\\ = \sum_{1}^{m}ln\frac{1}{\sigma\sqrt{2\pi}}exp(-\frac{(y ^ {(i)} - w ^ {T}x ^ {(i)}) ^ {2}}{2\sigma ^ {2}})\\ = mln\frac{1}{\sigma\sqrt{2\pi}} - \frac{1}{\sigma ^ {2}} * \frac{1}{2}\sum_{1}^{m}(y ^ {(i)} - w ^ {T}x ^ {(i)}) ^ {2} ln(L(w))=ln∏1mσ2π1exp(−2σ2(y(i)−wTx(i))2)=∑1mlnσ2π1exp(−2σ2(y(i)−wTx(i))2)=mlnσ2π1−σ21∗21∑1m(y(i)−wTx(i))2
上式中,前半部分都是常数,我们的目的是为了让联合密度概率值最大,因此,我们只需要让后半部分的值最小即可,因此,后半部分,就可以作为模型的损失函数。该函数是二次函数,具有唯一极小值。
最小二乘法
最小二乘法,即最小平方法(也许这样称呼或许更合理),通过让样本数据的预测值与真实值之间的误差平方和最小,进而求解参数的方法。
一方面,我们通过极大似然估计,寻找出目标函数,不过,我们也可以直观的进行分析。从简单的角度看,我们的目的,其实就是要寻找一条合适的直线(平面),使得所有样本距离直线(平面)的距离,达到最小化即可。因此,我们可以采用每个样本的预测值与真实值做差,然后取平方和的方式,能够让该平方和最小的w,就是我们需要求解的w)。思考:为什么要用平方和,而不是直接求和,或者绝对值求和?
J
(
w
)
=
1
2
∑
1
m
(
y
(
i
)
−
w
T
x
(
i
)
)
2
J(w) = \frac{1}{2}\sum_{1}^{m}(y ^ {(i)} - w ^ {T}x ^ {(i)}) ^ {2}
J(w)=21∑1m(y(i)−wTx(i))2
由于:
y
^
=
(
y
^
(
1
)
y
^
(
2
)
…
…
y
^
(
m
)
)
=
(
w
T
∗
x
(
1
)
w
T
∗
x
(
2
)
…
…
w
T
∗
x
(
m
)
)
=
(
w
1
x
1
(
1
)
+
w
2
x
2
(
1
)
+
…
…
+
w
n
x
n
(
1
)
w
1
x
1
(
2
)
+
w
2
x
2
(
2
)
+
…
…
+
w
n
x
n
(
2
)
…
…
w
1
x
1
(
m
)
+
w
2
x
2
(
m
)
+
…
…
+
w
n
x
n
(
m
)
)
=
(
x
1
(
1
)
,
x
2
(
1
)
,
…
…
x
n
(
1
)
x
1
(
2
)
,
x
2
(
2
)
,
…
…
x
n
(
2
)
…
…
x
1
(
m
)
,
x
2
(
m
)
,
…
…
x
n
(
m
)
)
⋅
(
w
1
w
2
…
…
w
n
)
=
X
⋅
w
y
=
(
y
(
1
)
y
(
2
)
…
…
y
(
m
)
)
e
r
r
o
r
=
(
e
r
r
o
r
(
1
)
e
r
r
o
r
(
2
)
…
…
e
r
r
o
r
(
m
)
)
=
(
y
^
(
1
)
−
y
(
1
)
y
^
(
2
)
−
y
(
2
)
…
…
y
^
(
m
)
−
y
(
m
)
)
=
y
^
−
y
=
X
⋅
w
−
y
=
>
∑
1
m
(
e
r
r
o
r
(
i
)
)
2
=
∑
1
m
(
y
^
(
i
)
−
y
(
i
)
)
2
=
∑
1
m
(
w
T
x
(
i
)
−
y
(
i
)
)
2
=
e
r
r
o
r
T
⋅
e
r
r
o
r
%y_hat定义 \hat{y} = \begin{pmatrix} \hat{y} ^ {(1)}\\ \hat{y} ^ {(2)}\\ ……\\ \hat{y} ^ {(m)} \end{pmatrix} = \begin{pmatrix} w ^ {T} * x ^ {(1)}\\ w ^ {T} * x ^ {(2)}\\ ……\\ w ^ {T} * x ^ {(m)} \end{pmatrix} = %wi * xi 展开式 \begin{pmatrix} w_{1}x_{1} ^ {(1)} + w_{2}x_{2} ^ {(1)} + …… + w_{n}x_{n} ^ {(1)}\\ w_{1}x_{1} ^ {(2)} + w_{2}x_{2} ^ {(2)} + …… + w_{n}x_{n} ^ {(2)}\\ ……\\ w_{1}x_{1} ^ {(m)} + w_{2}x_{2} ^ {(m)} + …… + w_{n}x_{n} ^ {(m)} \end{pmatrix} = \begin{pmatrix} x_{1} ^ {(1)}, x_{2} ^ {(1)}, ……x_{n} ^ {(1)}\\ x_{1} ^ {(2)}, x_{2} ^ {(2)}, ……x_{n} ^ {(2)}\\ ……\\ x_{1} ^ {(m)}, x_{2} ^ {(m)}, ……x_{n} ^ {(m)} \end{pmatrix} \cdot \begin{pmatrix} w_{1}\\ w_{2}\\ ……\\ w_{n} \end{pmatrix} = X\cdot w \\ %y的定义 y = \begin{pmatrix} y ^ {(1)}\\ y ^ {(2)}\\ ……\\ y ^ {(m)} \end{pmatrix}\qquad %error定义 error = \begin{pmatrix} error ^ {(1)}\\ error ^ {(2)}\\ ……\\ error ^ {(m)} \end{pmatrix} = \begin{pmatrix} \hat{y} ^ {(1)} - y ^ {(1)}\\ \hat{y} ^ {(2)} - y ^ {(2)}\\ ……\\ \hat{y} ^ {(m)} - y ^ {(m)} \end{pmatrix} = \hat{y} - y = X\cdot w - y\qquad => \\ %error总结 \sum_{1}^{m}(error ^ {(i)}) ^ {2} = \sum_{1}^{m}(\hat{y} ^ {(i)} - y ^ {(i)}) ^ {2} = \sum_{1}^{m}( w ^ {T}x ^ {(i)} - y ^ {(i)}) ^ {2} = error ^ {T} \cdot error
y^=
y^(1)y^(2)……y^(m)
=
wT∗x(1)wT∗x(2)……wT∗x(m)
=
w1x1(1)+w2x2(1)+……+wnxn(1)w1x1(2)+w2x2(2)+……+wnxn(2)……w1x1(m)+w2x2(m)+……+wnxn(m)
=
x1(1),x2(1),……xn(1)x1(2),x2(2),……xn(2)……x1(m),x2(m),……xn(m)
⋅
w1w2……wn
=X⋅wy=
y(1)y(2)……y(m)
error=
error(1)error(2)……error(m)
=
y^(1)−y(1)y^(2)−y(2)……y^(m)−y(m)
=y^−y=X⋅w−y=>∑1m(error(i))2=∑1m(y^(i)−y(i))2=∑1m(wTx(i)−y(i))2=errorT⋅error
因此:
J ( w ) = 1 2 ∑ 1 m ( y ( i ) − w T x ( i ) ) 2 = 1 2 ( X w − y ) T ( X w − y ) J(w) = \frac{1}{2}\sum_{1}^{m}(y ^ {(i)} - w ^ {T}x ^ {(i)}) ^ {2}\\ = \frac{1}{2}(Xw - y) ^ {T}(Xw - y) J(w)=21∑1m(y(i)−wTx(i))2=21(Xw−y)T(Xw−y)
我们要求该目标函数的最小值,只需要对自变量w进行求导,导数为0时w的值,就是我们要求解的值。
▽ w J ( w ) = ▽ w ( 1 2 ( X w − y ) T ( X w − y ) ) = ▽ w ( 1 2 ( w T X T − y T ) ( X w − y ) ) = ▽ w ( 1 2 ( w T X T X w − w T X T y − y T X w + y T y ) ) \triangledown_{w} J(w) = \triangledown_{w}(\frac{1}{2}(Xw - y) ^ {T}(Xw - y))\\ = \triangledown_{w}(\frac{1}{2}(w ^ {T}X ^ {T} - y ^ {T})(Xw - y))\\ = \triangledown_{w}(\frac{1}{2}(w ^ {T}X ^ {T}Xw - w ^ {T}X ^ {T}y - y ^ {T}Xw + y ^ {T}y)) ▽wJ(w)=▽w(21(Xw−y)T(Xw−y))=▽w(21(wTXT−yT)(Xw−y))=▽w(21(wTXTXw−wTXTy−yTXw+yTy))
根据矩阵与向量的求导公式,有:
∂
A
x
⃗
∂
x
⃗
=
A
T
\frac{\partial A\vec{x}}{\partial \vec{x}} = A ^ {T}
∂x∂Ax=AT
∂
A
x
⃗
∂
x
⃗
T
=
A
\frac{\partial A\vec{x}}{\partial \vec{x} ^ {T}} = A
∂xT∂Ax=A
∂
(
x
⃗
T
A
)
∂
x
⃗
=
A
\frac{\partial (\vec{x} ^ {T}A)}{\partial \vec{x}} = A
∂x∂(xTA)=A
∂
(
x
⃗
T
A
x
⃗
)
∂
x
⃗
=
(
A
T
+
A
)
x
⃗
\frac{\partial (\vec{x} ^ {T}A\vec{x})}{\partial \vec{x}} = (A ^ {T} + A)\vec{x}
∂x∂(xTAx)=(AT+A)x
特别的,如果 A = A T A = A ^ {T} A=AT(A为对称矩阵),则:
∂
(
x
⃗
T
A
x
⃗
)
∂
x
⃗
=
2
A
x
⃗
\frac{\partial (\vec{x} ^ {T}A\vec{x})}{\partial \vec{x}} = 2A\vec{x}
∂x∂(xTAx)=2Ax
因此:
▽
w
(
1
2
(
w
T
X
T
X
w
−
w
T
X
T
y
−
y
T
X
w
+
y
T
y
)
)
=
1
2
(
2
X
T
X
w
−
X
T
y
−
(
y
T
X
)
T
)
=
X
T
X
w
−
X
T
y
\triangledown_{w}(\frac{1}{2}(w ^ {T}X ^ {T}Xw - w ^ {T}X ^ {T}y - y ^ {T}Xw + y ^ {T}y))\\ = \frac{1}{2}(2X ^ {T}Xw - X ^ {T}y - (y ^ {T}X) ^ {T})\\ = X ^ {T}Xw - X ^ {T}y
▽w(21(wTXTXw−wTXTy−yTXw+yTy))=21(2XTXw−XTy−(yTX)T)=XTXw−XTy
令导函数的值为0,则:
w = ( X T X ) − 1 X T y w = (X ^ {T}X) ^ {-1}X ^ {T}y w=(XTX)−1XTy
以上的求解方式,就是最小二乘法。使用最小二乘法求解的时候,要求矩阵 X T X X ^ {T}X XTX必须是可逆的。
一元线性回归程序示例
接下来,我们来实现一元线性回归。
# sklearn 命名惯例:
# 矩阵 使用大写字母
# 向量 使用小写字母
# 所有模型的拟合(训练)方法都叫fit。
# 所有模型的测试方法都叫predict。
import numpy as np
# LinearRegression 线性回归的类,我们可以使用该类实现线性回归。
# 底层就是使用最小二乘公式来进行求解的。
from sklearn.linear_model import LinearRegression
# 该方法可以用来对数据集进行切分,分为训练集与测试集。训练集用于训练模型(求解出模型的参数w与b),
# 测试集用来验证我们建立模型的效果如何。
from sklearn.model_selection import train_test_split
# 设置随机种子。
np.random.seed(0)
x = np.linspace(-10, 10, 1000)
# 将x转换为二维的格式。之所以要将x转换为二维矩阵的格式,是因为稍后的模型fit方法中,第一个
# 参数(X)需要是二维的格式。
x = x.reshape(-1, 1)
# 自行构建一个方程,生成y值。
y = 0.85 * x - 0.72
# 生成正态分布的噪音。
e = np.random.normal(scale=1.5, size=x.shape)
# 令y值加入噪音,这样,更符合现实中数据的情况。(并不是完美的函数映射关系。)
y += e
# 创建线性回归类的对象。
lr = LinearRegression()
# 将样本数据切分为训练集与测试集。
# 该函数接收若干个数组,将每个数组切分为两部分,并返回。
# 相关参数:
# shuffle 是否进行洗牌,默认为True。
# random_state: 洗牌时候所使用的随机种子,相同的随机种子,一定可以产生相同的洗牌序列。
# test_size: 测试集数据所占有的比例。
train_X, test_X, train_y, test_y = train_test_split(x,
y,
test_size=0.25,
random_state=0)
# 拟合数据,即使用训练数据(X与y)去训练模型。实际上,拟合(训练)就是求解模型的参数(w与b)。
lr.fit(train_X, train_y)
# coef_ 返回模型训练好的权重w值。
print(f"权重:{lr.coef_}")
# intercept_ 返回模型训练好的截距(偏置)b。
print(f"截距:{lr.intercept_}")
# 测试方法。模型经过拟合训练后,就可以得到(求解出)w与b。一旦w与b确定,模型就能够进行预测。
# 根据参数传递过来的X,返回预测的结果(目标值)y_hat。
y_hat = lr.predict(test_X)
print(f"实际值:{test_y.ravel()[:10]}")
print(f"预测值:{y_hat.ravel()[:10]}")
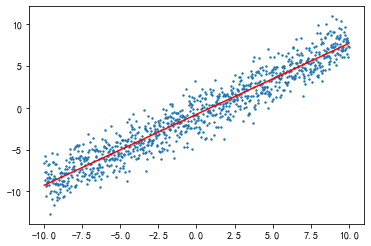
权重:[[0.84850287]]
截距:[-0.78380631]
实际值:[ 8.03907916 5.43572543 -4.74810247 -0.21098171 -0.70311919 8.75684748
-9.04131632 -6.02904889 -6.0141805 4.1986826 ]
预测值:[ 7.59930008 5.32303614 -4.20669575 0.12500056 2.14645884 7.22558511
-8.81018478 -5.34482773 -4.0707994 2.72401835]
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams["font.family"] = "SimHei"
mpl.rcParams["axes.unicode_minus"] = False
# 绘制数据集样本。
plt.scatter(x, y, s=2)
# 绘制线性回归的拟合直线。即模型y = w * x + b的那条线。也就是 y = 0.84850287 * x + -0.78380631
plt.plot(x, lr.predict(x), "r-")
线性回归模型评估
当我们建立好模型后,模型的效果如何呢?我们可以采用如下的指标来进行衡量。
- MSE
- RMSE
- MAE
- R 2 R ^ {2} R2
MSE
MSE(Mean Squared Error),平均平方误差,为所有样本误差(真实值与预测值之差)的平方和,然后取均值。
M S E = 1 m ∑ i = 1 m ( y ( i ) − y ^ ( i ) ) 2 MSE = \frac{1}{m}\sum_{i=1}^{m}(y ^ {(i)} - \hat{y} ^ {(i)}) ^ {2} MSE=m1∑i=1m(y(i)−y^(i))2
RMSE
RMSE(Root Mean Squared Error),平均平方误差的平方根,即在MSE的基础上,取平方根。
R M S E = M S E = 1 m ∑ i = 1 m ( y ( i ) − y ^ ( i ) ) 2 RMSE = \sqrt{MSE} = \sqrt{\frac{1}{m}\sum_{i=1}^{m}(y ^ {(i)} - \hat{y} ^ {(i)}) ^ {2}} RMSE=MSE=m1∑i=1m(y(i)−y^(i))2
MAE
MAE(Mean Absolute Error),平均绝对值误差,为所有样本误差的绝对值和。
M A E = 1 m ∑ i = 1 m ∣ y ( i ) − y ^ ( i ) ∣ MAE = \frac{1}{m}\sum_{i=1}^{m}|y ^ {(i)} - \hat{y} ^ {(i)}| MAE=m1∑i=1m∣y(i)−y^(i)∣
R 2 R ^ {2} R2
R
2
R ^ {2}
R2为决定系数,用来表示模型拟合性的分值,值越高表示模型拟合性越好,最高为1,可能为负值。
R
2
R ^ {2}
R2的计算公式为1减去RSS与TSS的商。其中,TSS(Total Sum of Squares)为所有样本与均值的差异,是方差的m倍。而RSS(Residual sum of squares)为所有样本误差的平方和,是MSE的m倍。
R 2 = 1 − R S S T S S = 1 − ∑ i = 1 m ( y ( i ) − y ^ ( i ) ) 2 ∑ i = 1 m ( y ( i ) − y ‾ ) 2 y ‾ = 1 m ∑ i = 1 m y ( i ) R ^ {2} = 1 - \frac{RSS}{TSS} = 1 - \frac{\sum_{i=1}^{m}(y ^ {(i)} - \hat{y} ^ {(i)}) ^ {2}} {\sum_{i=1}^{m}(y ^ {(i)} - \overline{y}) ^ {2}} \\ \overline{y} = \frac{1}{m}\sum_{i=1}^{m}y ^ {(i)} R2=1−TSSRSS=1−∑i=1m(y(i)−y)2∑i=1m(y(i)−y^(i))2y=m1∑i=1my(i)
从公式定义可知,最理想情况,所有的样本的预测值与真实值相同,即RSS为0,此时 R 2 R ^ {2} R2为1。
# sklearn.metrics 该模块提供很多模型度量(评估)的方法。
# mean_squared_error MSE
# mean_absolute_error MAE
# r2_score 求R ^ 2
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# y_true 标签的真实值(所有样本)
# y_pred 标签的预测值(所有样本)
mse = mean_squared_error(y_true=test_y, y_pred=y_hat)
print(f"均方误差(MSE):{mse}")
rmse = np.sqrt(mse)
print(f"均方根误差(RMSE):{rmse}")
mae = mean_absolute_error(y_true=test_y, y_pred=y_hat)
print(f"平均绝对值误差(MAE):{mae}")
# 我们也可以自行计算MSE,RMSE,MAE。
# print(np.mean((test_y - y_hat) ** 2))
# 计算模型的评分制。
# 从结果可以看出,通过R^2进行评估,可以比其他几种方式更加直观。
r2 = r2_score(y_true=test_y, y_pred=y_hat)
print(f"R^2的值(测试集):{r2:.3f}")
# 以上指标(MSE, RMSE, MAE, R^2)也可以在训练集上进行评估。
r2_train = r2_score(y_true=train_y, y_pred=lr.predict(train_X))
print(f"R^2的值(训练集):{r2_train:.3f}")
# R^ 2求解的另外一种方式,可以使用模型的score方法。
# 总结:R ^ 2可以采用两种方式进行求解。
# 1 r2_score
# 2 模型对象.socre方法。
# 注意:尽管两个方法都能够求解R ^ 2值,但是,两个方法传递的参数意义是不同的。
# 对于r2_score,需要传递的是真实值(标签)与预测值(标签)。
# 对于lr.score,需要传递的是样本数据(X)与对应的真实标签。
train_score = lr.score(train_X, train_y)
test_score = lr.score(test_X, test_y)
print(f"测试集R^2:{test_score:.3f}")
print(f"训练集R^2:{train_score:.3f}")
均方误差(MSE):1.9469051097000563
均方根误差(RMSE):1.3953154158469174
平均绝对值误差(MAE):1.077355895155826
R^2的值(测试集):0.923
R^2的值(训练集):0.914
测试集R^2:0.923
训练集R^2:0.914
多元线性回归程序示例
类似的,我们也可以实现多元线性回归。这里,我们需要创建多个特征(x),我们也可以像之前程序那样,随机生成多个特征,不过,这里,我们使用sklearn库提供的更方面的方法。
make_regression(n_samples=5,
n_features=2,
coef=False, bias=5.5,
random_state=0,
noise=10)
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
# 可以生成用于回归分析的样本数据与对应的标签。
from sklearn.datasets import make_regression
# 参数说明:
# n_samples:生成的样本数量。
# n_features:生成的特征数量。(有几个x)
# coef:是否返回方程的权重(w)。如果该值为True,则返回X,y与coef。
# 如果该值为False,仅返回X与y。默认为False。
# bias:偏置值(截距),也就是方程中的b。
# random_state:设置随机种子。
# noise:噪声的值。该值会影响数据的波动情况。值越大,波动性越大。
X, y, coef = make_regression(n_samples=1000, n_features=2, coef=True, bias=5.5, random_state=0, noise=10)
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.25, random_state=0)
print(f"实际权重:{coef}")
lr = LinearRegression()
lr.fit(train_X, train_y)
print(f"权重:{lr.coef_}")
print(f"截距:{lr.intercept_}")
y_hat = lr.predict(test_X)
print(f"均方误差:{mean_squared_error(test_y, y_hat)}")
print(f"训练集R^2:{lr.score(train_X, train_y)}")
print(f"测试集R^2:{lr.score(test_X, test_y)}")
实际权重:[41.09157343 40.05104636]
权重:[40.45489185 40.70039455]
截距:5.090359583452669
均方误差:88.59167239350731
训练集R^2:0.9714238034122037
测试集R^2:0.9725277852723199
# meshgrid的演示
x1 = np.array([2, 3, 4])
x2 = np.array([2, 3, 4, 5])
X1, X2 = np.meshgrid(x1, x2)
display(X1)
display(X2)
array([[2, 3, 4],
[2, 3, 4],
[2, 3, 4],
[2, 3, 4]])
array([[2, 2, 2],
[3, 3, 3],
[4, 4, 4],
[5, 5, 5]])
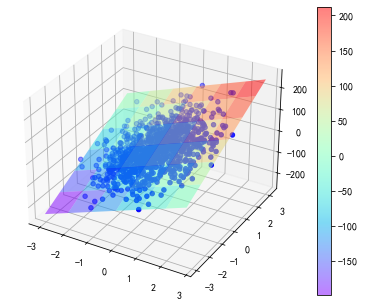
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams["font.family"] = "SimHei"
mpl.rcParams["axes.unicode_minus"] = False
#Axes3D 用来绘制3D图形的类。
from mpl_toolkits.mplot3d import Axes3D
# 设置绘图后,以弹出框的形式显示。因为嵌入显示(默认)的形式,图像为一张图片,
# 无法进行拖动而转换角度。这在三维图中不利于观察。
# %matplotlib qt
# 分别返回x1与x2两个特征的最大值。
max1, max2 = np.max(X, axis=0)
# 分别返回x1与x2两个特征的最小值。
min1, min2 = np.min(X, axis=0)
# 在x1轴的区间上取若干点。
x1 = np.linspace(min1, max1, 30)
# 在x2轴的区间上取若干点。
x2 = np.linspace(min2, max2, 30)
# 接收两个一维数组。进行网格扩展。过程:将x1沿着行进行扩展,扩展的行数与x2含有的元素
# 个数相同。将x2沿着列进行扩展,扩展的列数与x1含有的元素个数相同。返回扩展之后的X1与X2(并非
# 就地修改)。X1与X2的形状(shape)是相同的。
# 扩展的目的:依次对位取出X1与X2中的每个元素,就能够形成x1与x2(原始的一维数组x1与x2)中任意
# 两个元素的组合,进而就能够形成网格的结构。
X1, X2 = np.meshgrid(x1, x2)
# 创建一个画布对象,用于绘制图像。
fig = plt.figure()
# 创建Axes3D对象,用于绘制3D图。参数指定画布对象,表示要在哪个
# 画布上进行绘制。(要绘制图像,就不能离开画布对象的支持。)
ax = Axes3D(fig)
# 绘制3D散点图。
ax.scatter(X[:, 0], X[:, 1], y, color="b")
# 绘制3D空间平面(曲面)。预测的y_hat值需要与X1或X2的形状相同。
# rstride 在行(row)的方向上前进的距离。
# cstride 在列(column)的方向上前进的距离。
# 距离越大,网格越宽。
# cmap colormap,指定绘制的风格。可以通过plt.cm.颜色图对象进行指定。
# alpha 指定透明度。
surf = ax.plot_surface(X1, X2, lr.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
rstride=5, cstride=5, cmap=plt.cm.rainbow, alpha=0.5)
# 显示颜色条。可以观察到每种颜色所对应的值。参数指定为那个图像对象所设定。
fig.colorbar(surf)
plt.show()
e:\virtualenv\ykda\lib\site-packages\ipykernel_launcher.py:30: MatplotlibDeprecationWarning: Axes3D(fig) adding itself to the figure is deprecated since 3.4. Pass the keyword argument auto_add_to_figure=False and use fig.add_axes(ax) to suppress this warning. The default value of auto_add_to_figure will change to False in mpl3.5 and True values will no longer work in 3.6. This is consistent with other Axes classes.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









