







目录
0. 本栏目竞赛汇总表
1. 竞赛信息解读
1.1 竞赛链接与概览

1.2 竞赛解读
本次竞赛的目标是通过构建自然语言处理(NLP)模型,预测数学多选题中错误选项(干扰项)与潜在误解(misconceptions)之间的关联性。在传统的标注流程中,每个错误选项都需要经过人工仔细匹配到相应的误解,这一过程不仅耗时费力,还容易出现标注不一致的问题。竞赛希望参赛者开发的模型能够实现这一匹配过程的自动化或半自动化,不仅能够精准覆盖已知的误解,还能对新出现的误解表现出良好的泛化能力,从而有效减轻人工标注的负担,提升教育的效率与质量。
图例:
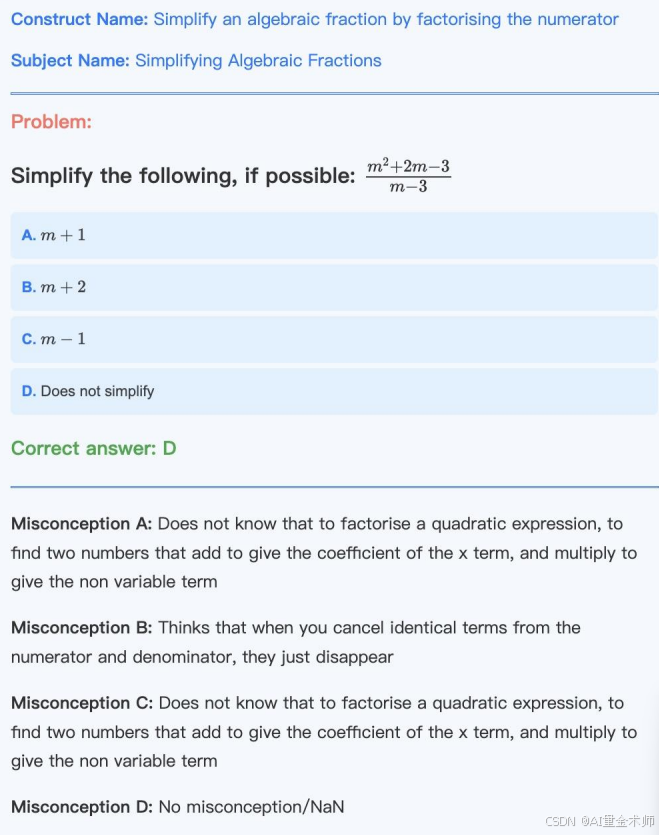
1.3 大白话说竞赛解读
数学单选选择题(4选1),会有1个正确答案,和3个错误答案,每个错误答案(A)应该都要有错误解释(B),本竞赛的主要目的是使用大语言模型,实现错误答案(A)与错误解释(B)的关联。
2. 数据探索
2.1 数据概览


2.2 错误解释(B)数据展示
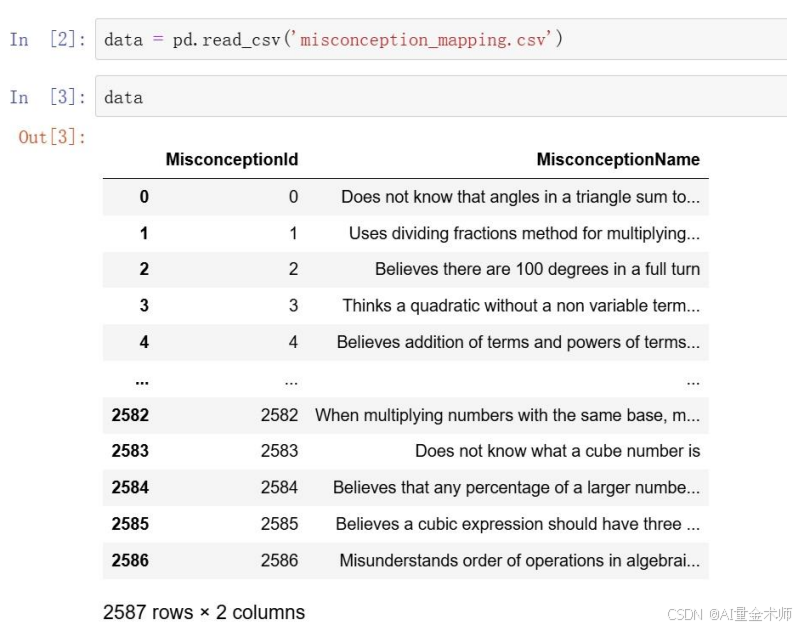
可见错误解释(B),有2587类,我们需要做的是,给每个题目的错误答案(A),匹配上合适的错误解释(B)对应的id。
2.3 训练数据预览
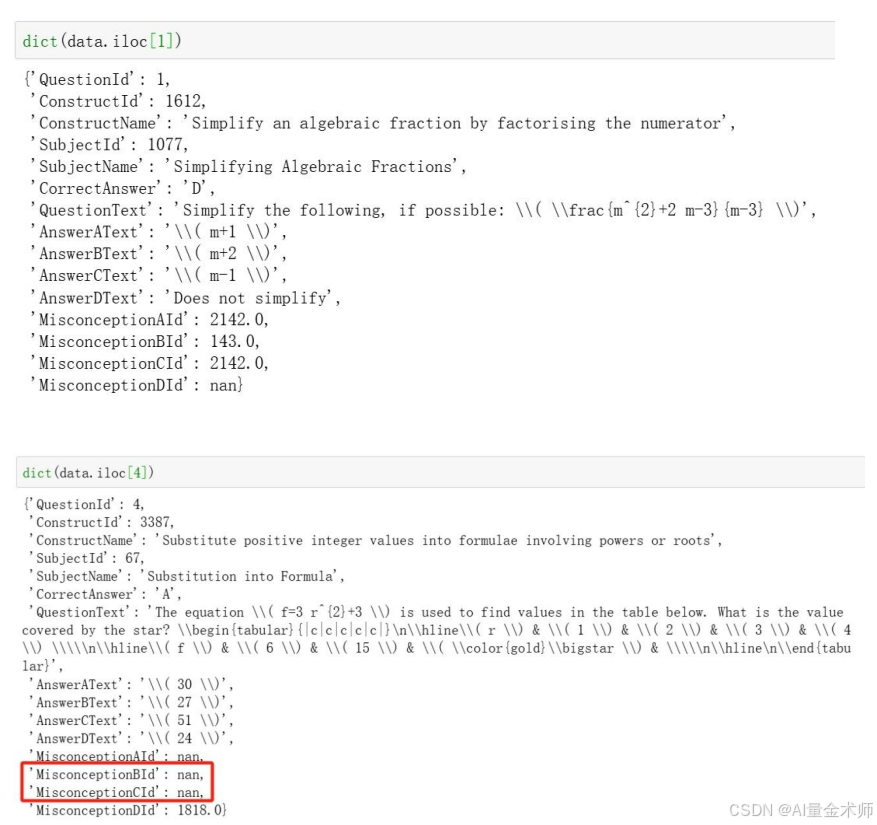
发现数据问题:
以上id为4的问题,正确答案是A,但是错误答案B\C却没有匹配上错误解释。
解决方案:
使用AI工具,对缺失的错误解释进行补全,再对错误解释列表进行相似性分析,获取出错误解释(B)对应的id。
2.4 测试数据预览
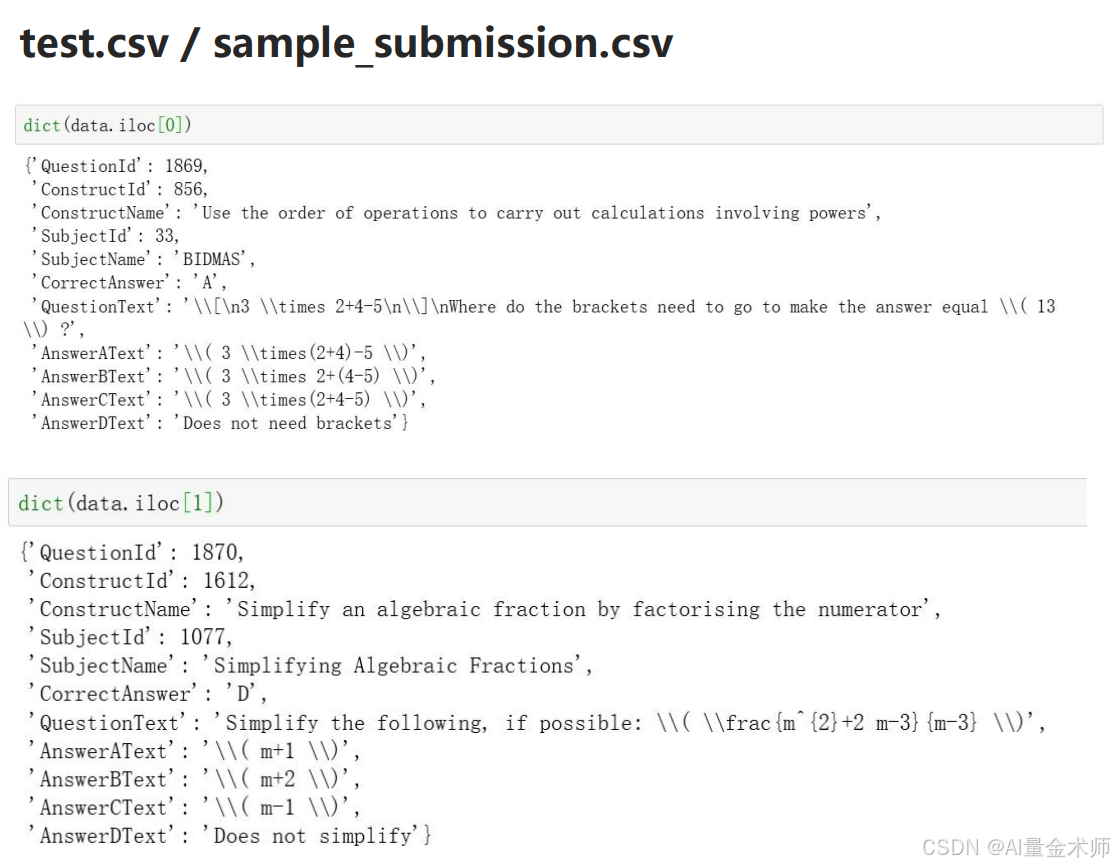
2.5 大白话说训练数据与测试数据
可见测试数据,相较于训练数据少了:错误答案(A)与错误解释(B)的关联。如下图所示:

而这就是需要使用AI蒸馏技术与AI架构开发实现的内容。
3. 评分方式
3.1 评分概览

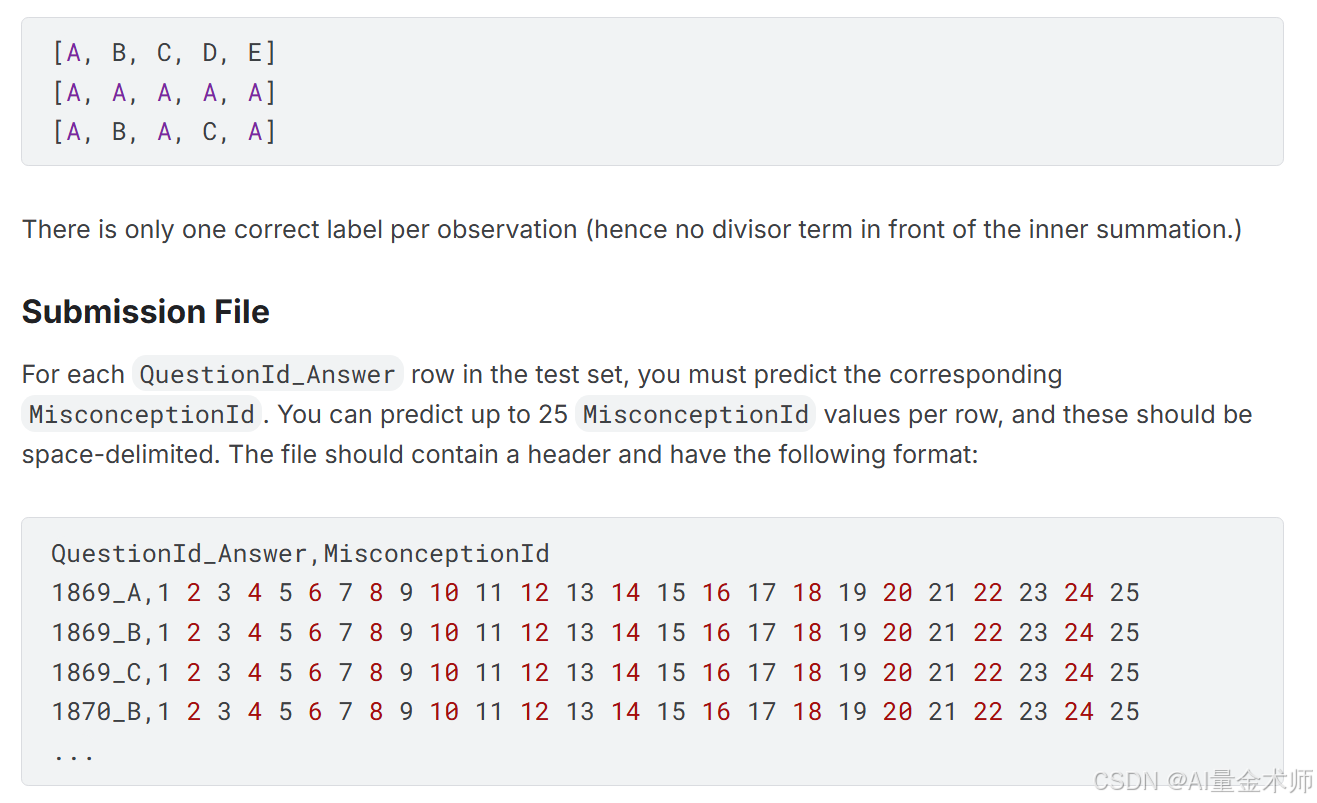
3.2 评分解读
把提交的错误答案(A)与错误解释(B)的关联进行降序排序,获取关联性最大的前25个,与真实的关联关系进行对照。
- U: 观测数量
- P(k): 截断点k处的精确率
- n: 每个观测的预测数量
- rel(k): 指示函数,排名k处为正确标签时为1,否则为0
3.3 大白话评分解读
假设1869题的A答案,的错误解释id为23,以下是几种提交情况:
- 提交01:
| QuestionId_Answer | MisconceptionId |
|---|---|
| 1869_A | 23 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 1 24 25 |
本次提交获得分数:25/25=1分
- 提交02:
| QuestionId_Answer | MisconceptionId |
|---|---|
| 1869_A | 2 3 4 5 6 23 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 1 24 25 |
本次提交获得分数:20/25=0.8分
- 提交03:
| QuestionId_Answer | MisconceptionId |
|---|---|
| 1869_A | 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 1 24 25 23 |
本次提交获得分数:1/25=0.04分
因此我们需要使错误解释(B)的id尽可能靠前。
(To be continued)


















 675
675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











