




 WaveNet是一种先进的音频生成模型,能创造出前所未有的自然语音。它利用Dilated Causal Convolutions解决高频率音频处理的问题,实现高质量的文本到语音转换。模型不仅能生成接近真人发音的语音,还能根据不同说话者身份条件生成多种声音。
WaveNet是一种先进的音频生成模型,能创造出前所未有的自然语音。它利用Dilated Causal Convolutions解决高频率音频处理的问题,实现高质量的文本到语音转换。模型不仅能生成接近真人发音的语音,还能根据不同说话者身份条件生成多种声音。
WaveNet
前言:
目前deep learning的目标逐渐开始注重视频的声音,然后声音的frequency是非常高的,paper做法一般采用16khz,一般mp3文件可能更高,大约100多khz左右吧。然后常规的convolution卷积的效果并不理想,因为感受野太小了,怎么样提高感受野是audio模型的关键问题,wavenet采用了DILATED CAUSAL CONVOLUTIONS,然而其实本篇paper还有很多声音的细节处理值得我们学习。另外目前处理还是停留在单声道阶段,笔者在用python自己读音乐的wav的时候发现双声道左右的内容其实是不同的。
优势:
1): We show that WaveNets can generate raw speech signals with subjective naturalness never before reported in the field of text-to-speech (TTS), as assessed by human raters.
wavenet可以生成接近人自然腔调的声音
2): We show that when conditioned on a speaker identity, a single model can be used to generate different voices.
condition固定一个人,可以根据这个人声音生成不同的语音。
论文主页
demo: https://deepmind.com/blog/wavenet-generative-model-raw-audio/
paper: https://arxiv.org/pdf/1609.03499.pdf
知乎源码阅读:https://zhuanlan.zhihu.com/p/24568596
具体内容
(1):input
There are no pooling layers in the network, and the output of the model has the same time dimensionality as the input.
没有pooling层,input和output有一样的time dimension。模型本身根据PixelCNNs搭的。
(2): DILATED CAUSAL CONVOLUTIONS
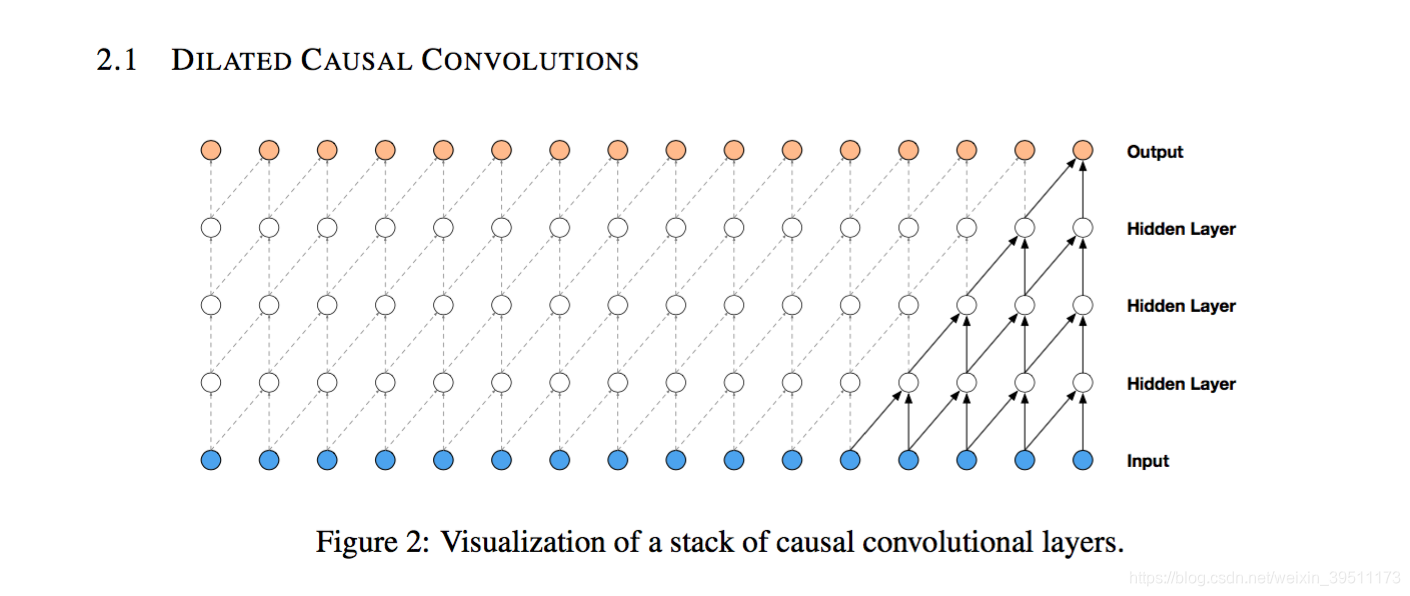 1):Each audio sample
x
t
x_{t}
xt is therefore conditioned on the samples at all previous timesteps. 通过上图这种结构确保了condition的顺序。
1):Each audio sample
x
t
x_{t}
xt is therefore conditioned on the samples at all previous timesteps. 通过上图这种结构确保了condition的顺序。
2): For images, the equivalent of a causal convolution is a masked convolution (van den Oord et al., 2016a) which can be implemented by constructing a mask tensor and doing an elementwise multiplication of this mask with the convolution kernel before ap- plying it. For 1-D data such as audio one can more easily implement this by shifting the output of a normal convolution by a few timesteps.
3): At training time, the conditional predictions for all timesteps can be made in parallel because all timesteps of ground truth x are known. When generating with the model, the predictions are se- quential: after each sample is predicted, it is fed back into the network to predict the next sample.
training时候因为我们有ground truth所以可以直接全拿一起算loss,然后用model生成东西的时候,只能先生成一个sample,然后拿这个sample放进网络里去生成下一个sample
4):具体部分可以参考知乎的源码阅读链接
(3): info about audio
1): mu-law 通过mu lawtransformation将16 bit int的audio的可能的output转换成为256 possible values,需要注意
−
1
<
x
t
<
1
,
μ
=
255
-1<x_{t}<1, \mu=255
−1<xt<1,μ=255.
通过mu lawtransformation将16 bit int的audio的可能的output转换成为256 possible values,需要注意
−
1
<
x
t
<
1
,
μ
=
255
-1<x_{t}<1, \mu=255
−1<xt<1,μ=255.
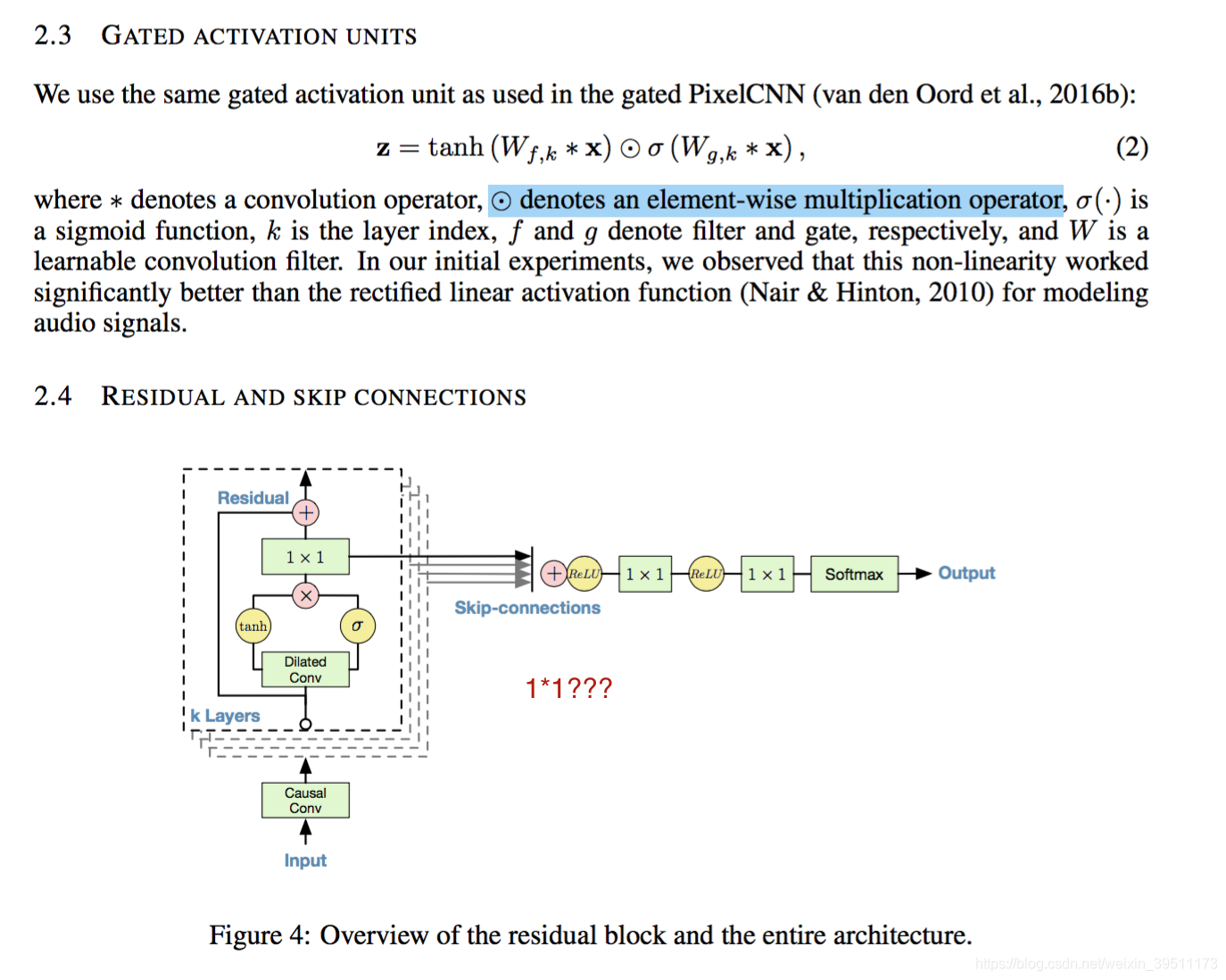
2): 激活函数和模型结构

















 1024
1024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









