







参考链接:
Mxnet 训练代码
Tensorflow 训练代码
论文数据集
WiderFace数据集

数据集打包方法:
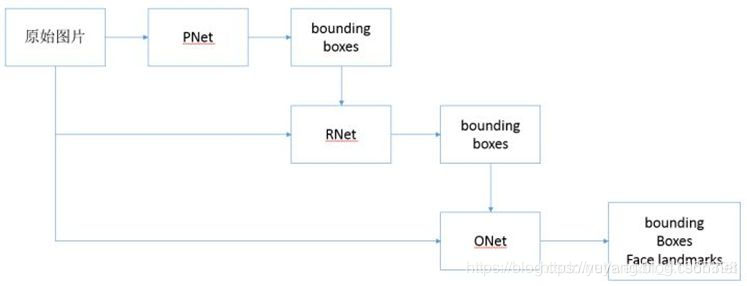
本文设计的网络包含三个不同的网络结构,Second Network的训练数据需要用到First Network训练好的模型生成,Third Network的训练数据由Second Network训练好的模型生成。 所以在模型训练阶段,需要面向多个任务,在网络训练的不同阶段,运行相应的脚本文件按,打包不同的数据。
- First Network数据打包
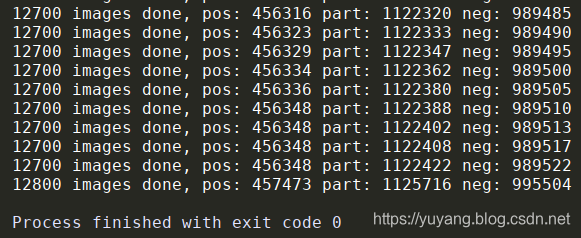
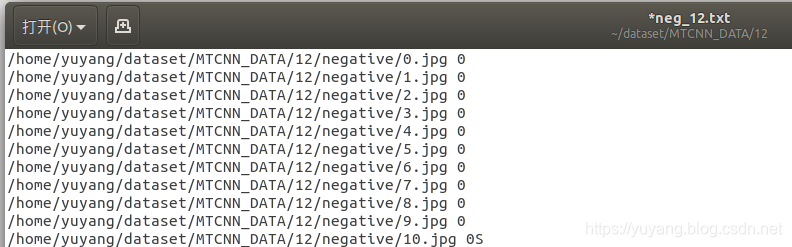
(1) 运行gen_12net_data.py生成目标检测所用到的数据,原始数据为Widerface数据集,生成了部分代码如下。
im_dir = "/home/yuyang/dataset/MTCNN_DATA/WIDER_train/images"
pos_save_dir = "/home/yuyang/dataset/MTCNN_DATA/12/positive"
part_save_dir = "/home/yuyang/dataset/MTCNN_DATA/12/part"
neg_save_dir = '/home/yuyang/dataset/MTCNN_DATA/12/negative'
save_dir = "/home/yuyang/dataset/MTCNN_DATA/12"
将相对路径中…/DATA 改为绝对路径/home/yuyang/dataset/MTCNN_DATA。
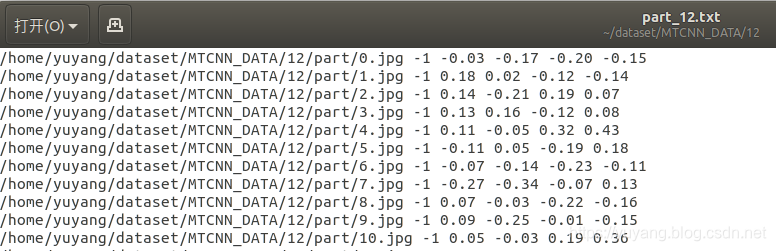
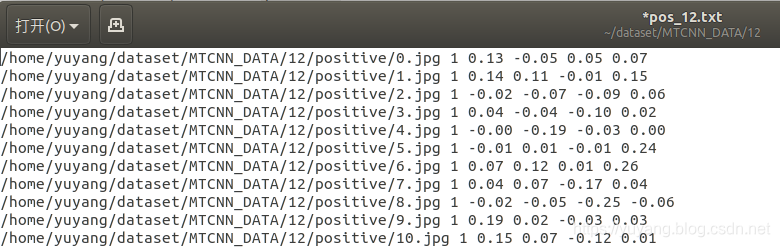
(2) 运行gen_landmark_aug_12.py生成关键点定位所用到的数据。

(3) 运行gen_imglist_pnet.py将前两部分的数据合二为一,生成图像列表。
(4) 根据第三步获取的图像列表,运行gen_PNet_tfrecords.py生成tensorflow框架所需的训练数据格式tfrecords。
2. Second Network数据打包
(1) 在完成First Network 训练后,运行gen_hard_example 生成Second Network的训练数据,此部分的训练数据用于人脸检测。
from sklearn.externals import joblib #将pickel去掉,这个会有缓存要求,内存不够,导致运行几小时的结果无法保存
def parse_args():
parser = argparse.ArgumentParser(description='Test mtcnn',
def parse_args():
parser.add_argument('--test_mode', dest='test_mode', help='test net type, can be pnet, rnet or onet',
default='PNet', type=str)
parser.add_argument('--prefix', dest='prefix', help='prefix of model name', nargs="+",
default=['../data/MTCNN_model/PNet_Landmark/PNet', '../data/MTCNN_model/RNet_Landmark/RNet', '../data/MTCNN_model/ONetLandmark/ONet'],
type=str)
parser.add_argument('--epoch', dest='epoch', help='epoch number of model to load', nargs="+",
default=[30, 14, 16], type=int) #此处为30,与逊
return args
if __name__ == '__main__':
net = 'PNet'
if net == "PNet":
image_size = 24
if net == "RNet":
image_size = 48
base_dir = '/home/yuyang/dataset/MTCNN_DATA/WIDER_train'
data_dir = '/home/yuyang/dataset/MTCNN_DATA/%s' % str(image_size)
neg_dir = get_path(data_dir, 'negative')
pos_dir = get_path(data_dir, 'positive')
part_dir = get_path(data_dir, 'part')
结果:
1.083285 seconds for each image
12700 out of 12880 images done
1.773485 seconds for each image
12800 out of 12880 images done
1.591134 seconds for each image
num of images 12880
time cost in average1.261 pnet 1.261 rnet 0.000 onet 0.000
boxes length: 12880
finish detecting
save_path is :
../MTCNN_DATA/no_LM24/RNet
(2) 运行gen_landmark_aug_24.py生成关键点定位所用到的数据。
#将data_path写上
def GenerateData(ftxt, data_path,net,argument=False):
if net == "PNet":
size = 12
elif net == "RNet":
size = 24
elif net == "ONet":
size = 48
else:
print('Net type error')
return
image_id = 0
f = open(join(OUTPUT,"landmark_%s_aug.txt" %(size)),'w')
data = getDataFromTxt(ftxt,data_path)
if __name__ == '__main__':
# train data
net = "RNet"
data_path = "/home/yuyang/dataset/MTCNN_DATA/lfpw"
#train_txt = "train.txt"
train_txt = "trainImageList.txt"
imgs,landmarks = GenerateData(train_txt, data_path,net,argument=True)
(3) 运行gen_imglist_pnet.py将前两部分的数据合二为一,生成图像列表。
(4) 根据第三步获取的图像列表,运行gen_RNet_tfrecords.py生成tensorflow框架所需的训练数据格式tfrecords,此脚本运行4次,分别生成Positive faces、Negative faces、Part faces、Landmark face的数据集。
if __name__ == '__main__':
dir = '/home/yuyang/dataset/MTCNN_DATA'
net = '24'
output_directory = '/home/yuyang/dataset/MTCNN_DATA/imglists/RNet'
if not os.path.exists(output_directory):
os.makedirs(output_directory)
name = 'pos' #更该name=neg,pos当name =landmark时,需要将 net = “/imglist/Rnet”,因为,生成的难例landmark.txt在Imaglists/RNet下。
run(dir, net, output_directory,name, shuffling=True)
- Third Network 数据打包
(1) 在完成Sirst Network 训练后,运行gen_hard_example 生成Second Network的训练数据,此部分的训练数据用于人脸检测。
def parse_args():
parser = argparse.ArgumentParser(description='Test mtcnn',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--test_mode', dest='test_mode', help='test net type, can be pnet, rnet or onet',
default='RNet', type=str)

(2) 运行gen_landmark_aug_48.py生成关键点定位所用到的数据。
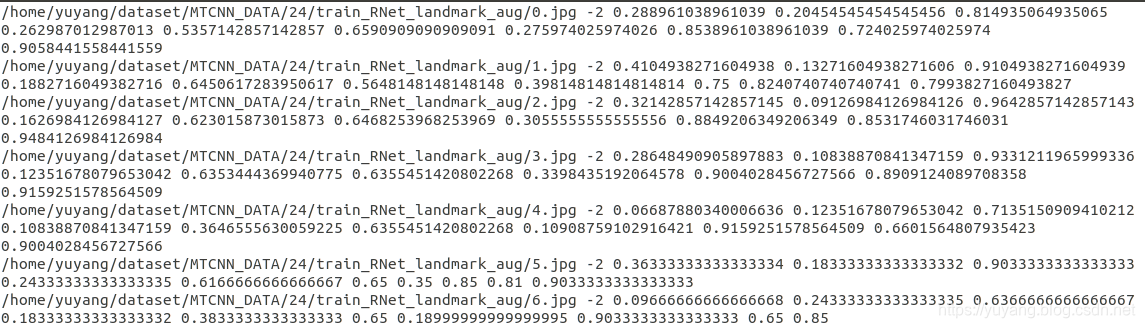
生成了landmark_48_aug.txt和train_ONet_landmark_aug文件夹(图片)。
(3) 运行gen_imglist_pnet.py将前两部分的数据合二为一,生成图像列表。
(4) 根据第三步获取的图像列表,运行gen_ONet_tfrecords.py生成tensorflow框架所需的训练数据格式tfrecords,此脚本运行4次,分别生成Positive faces、Negative faces、Part faces、Landmark face的数据集。
简介:
core: 核心例程 for MTCNN training and testing.
tools: 工具 for training and testing
data: Refer to Data Folder Structure for dataset reference. Usually dataset contains images and imglists
model: Folder to save training symbol and model
prepare_data: scripts for generating training data for pnet, rnet and onet






















 1109
1109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









